The cocktail party effect refers to a challenging problem in speech perception where one is able to selectively attend to one sound source in a noisy and multi-talk environment. The recent studies in neuroscience and psychoacoustics shed light on how the human brain solves the cocktail party problem, that inspires many computational solutions. With the advent of novel physiological techniques and deep learning algorithms, it is now possible to effectively detect auditory attention based on brain signals. In this paper, we provide a comprehensive overview of the most recent EEG-based auditory attention detection techniques and the methods to evaluate their performance. We examine both statistical and deep learning approaches, exploring their strengths and limitations. Furthermore, we also point out the gaps between the state-of-the-art and the practical needs in real-world applications. We also offer an overview of the available resources for EEG-based auditory attention detection research.
1 Introduction
Speech perception is a cognitive process that enables us to interpret and understand our acoustic environment. Although we often take the discrimination, identification, and interpretation of acoustic signals for granted, speech perception is a complex motor process that begins in the cochlea, travels through the auditory nerve and several auditory nuclei, and ends in the primary auditory cortex and different brain regions [91]. For individuals with normal hearing, speech perception may seem straightforward, yet the limitations of this ability are revealed in the presence of background noise, particularly among the elderly and those with hearing loss [93]. Indeed, high-intensity non-speech noise can obscure sounds and make words ambiguous or unintelligible. When the noise is composed primarily of other speakers, it may also distract the listener’s attention, creating a more complicated scenario, namely the cocktail party problem [27].
The inability to follow a single speaker in a cocktail party situation is usually the first symptom of a speech perception problem for most people [90]. Such a speech perception problem is not only common in elders but also afflicts young adults with mild hearing loss and cochlear implant recipients [91]. Moreover, many people with normal hearing thresholds may experience difficulties understanding speech in noisy environments [7]. With the increasing number of people with hearing problems, it is crucial to explore the underlying mechanisms of selective listening at cocktail party scenarios for a better understanding of hearing loss, and further improve the hearing function in difficult listening conditions. Since the 1950s, the cocktail party problem has been the subject of research in a wide range of disciplines, including physiology, neurobiology, psychophysiology, cognitive psychology, biophysics, computer science, and engineering [17, 56].
In the context of a cocktail party, speech perception entails two fundamental tasks: speech separation and selective auditory attention [75]. Human ears collect a mixture of signals from all sound sources in the auditory scene. However, the listener may be interested only in one particular sound source. Hence, empowering a hearing-aid device to extract the target speech from the mixture will greatly benefit speech perception for hearing-impaired individuals. The study of computational solutions to speech separation is worthy of another full overview, which is not the focus of this article. Interested readers are referred to [112] for in-depth discussions. In this paper, we are particularly interested in the second task, that is to automatically detect the auditory attention of a listener from his/her brain signals. As the human brain is born with the auditory attention ability in the cocktail party, the findings on the brain’s “magic” not only advance the understanding of related clinical studies, but also offer valuable insights into effective interventions for clinical populations who may experience challenges in speech perception.
The exploration of how the human brain solves the cocktail party problem has been a sustained effort. It is common to keep the subject in a cocktail party environment and monitor the associated neural response in his/her brain. The functional methods in these experiments mainly fall into two broad categories [98]. One is the hemodynamic measurements including functional magnetic resonance imaging (fMRI), positron emission tomography (PET), and functional near-infrared spectroscopy (fNIRS), among others, in which we learned the neural activity in the whole brain through the changes to blood flow. For instance, Peelle and Wingfield discovered that focusing on a speech at a cocktail party environment activates more brain regions than hearing speech that is acoustically clear [91]. Another is the studies of the activity in brain neurons using various biological signals, including both invasive methods such as Electrocorticography (ECoG) and stereoelectroencephalography (sEEG), as well as non-invasive methods like electroencephalography (EEG) and magnetoencephalography (MEG). These studies revealed that biological signals respond preferentially to critical features of the attended speech (such as temporal representations [5, 39, 78, 88, 96] and spatial locations [37, 114, 116]) rather than mixture speeches.
The advancement of these neuroimaging and neurophysiological studies has greatly benefited speech perception in cocktail party scenarios as well. As the neural response of the brain is closely related to attention, it is logical to hypothesize that one can detect auditory attention from brain signals. This topic has gained increasing traction in the past decade, and is generally referred to as auditory attention detection (AAD). The success of AAD opens up the possibilities of neuro-steered smart hearing devices, which detect a listener’s auditory attention so as to select a sound source from a complex acoustic environment just like what humans do. A number of biological signals may carry such auditory attention trace. Not all of them are appropriate for neuro-steered hearing devices. For instance, hemodynamic measurements have a long data collection latency, the invasive EEG and ECoG may be harmful to the population outside of the clinical treatment, and MEG is not wearable. In contrast, EEG enjoys the superiority of being less expensive, more widely available, and easier to use, making it a viable option for integration into everyday devices and future brain-computer interface (BCI) applications. Therefore, we mainly limited the scope of this article to EEG-based AAD methods.
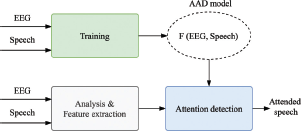
The training and run-time inference of a typical EEG-based speech perception system is illustrated in Figure 1. In the offline training phase, the model learns to associate the EEG signals and their speech stimuli. During the run-time inference, the attended speech will be determined and enhanced to improve speech perception. These techniques can be categorized in different ways, for example, according to the type of speech stimulus - clean speech vs speech mixtures; the type of attention focus - speaker vs locus, the type of EEG data - full scalp EEG vs ear-EEG; the workflow of the AAD model - stimulus-reconstruction vs direct classification; the generalization ability -subject-dependent vs subject-independent. From the viewpoint of the speech stimulus, early EEG-based speech perception research was premised on the assumption of ideal speech separation performance. These studies utilized the ground truth of speech stimulus directly as a reference. With clean speech, one can study a linear or non-linear reconstruction function to estimate the acoustic features of the attended speech, e.g. envelope, spectrogram, Mel-spectrogram, linguistic speech representations, from the full scalp EEG recordings, or vice versa. Although such reconstruction functions cannot perfectly reconstruct the stimuli, auditory attention can be determined by the correlation between the output with the ground-truth feature. This pipeline has been widely studied with different approaches, just name a few, linear regression (LS) [88], canonical correlation analysis (CCA) [28], averaging decoders [88], averaging auto-correlation matrices [12]. Later, with the advancements in deep learning, some studies aimed to reconstruct the envelope of the target speaker’s signal from EEG signals using non-linear neural networks (NNs) [105] and long short-term memory (LSTM) model [82].
We posit that the stimulus-reconstruction approach exhibits two limitations. Firstly, the process of stimulus reconstruction and correlation evaluation is not optimized to effectively detect attention. Secondly, the compression of multichannel EEG signals into a single waveform through stimulus reconstruction reduces the available information for analysis. While such transformation interprets well how brain signals correlate with speech stimulus, it doesn’t necessarily represent the best way for auditory attention detection. To avoid any information loss in data compression, some recent works intended to classify the attended speaker [29] or locus [110] directly, and have achieved great success.
Since clean speech is not always available, especially in real-life scenarios, studies on EEG-based speech perception are conducted to estimate the selective attention from the mixture to improve the feasibility of the neuro-steered hearing devices. Coordination with speech separation [11, 33, 109] is one of the research directions to overcome this challenge. Besides, in [25, 63], the attended speech is directly extracted from the mixture with the additional feature estimated from EEG data. Another direction to increase the practicability is making the system more portable, which is achieved by reducing the number of the required EEG electrodes [22, 81, 83–85, 101], using different types of EEG recording equipment, such as ear-EEG [14, 15, 36, 38, 42, 43, 61, 64–66, 73, 76, 77, 80].
Geirnaert et al. [49] presented an overview of EEG-based AAD, which summarizes the traditional modeling approach. With the advent of deep learning, EEG-based speech perception techniques have seen a significant advancement. The neural solution has not only enhanced the existing state-of-the-art methods but also bridged the gap between the ideal model and the practical implementation of neuro-steered hearing devices in noisy environments. Additionally, it opens up a new avenue of research beyond the existing stimulus-reconstruction and direct classification AAD methodologies. Nonetheless, these classical AAD approaches have played a critical role in advancing the understanding of speech perception in cocktail party environments and provided valuable insights into various aspects of the research challenge. With this paper, we aim to offer a comprehensive overview of EEG-based AAD research for speech perception in cocktail party scenarios by presenting a perspective that highlights the core design principles, ranging from the ideal AAD model to practical implementation, along with the challenges encountered and the future directions of the field.
This paper is organized as follows: Section 2 introduces the fundamentals of how the brain’s auditory system perceives speech. In Section 3, we provided a brief overview of works that reconstructed speech from brain signals and explained the reason why employ the EEG-based AAD to support speech perception in a cocktail party environment. Followed with Sections 4 and 5, we introduced the conventional AAD algorithms and emerging works with deep learning, In Section 6, we focused on the application-oriented AAD works towards speech perception in cocktail parties. In Sections 7 and 8, we summarize the publicly available research resources for EEG-based AAD in cocktail party scenarios and discuss the challenges and future directions. We conclude this paper in Section 9.
2 Fundamental of the Speech Perception
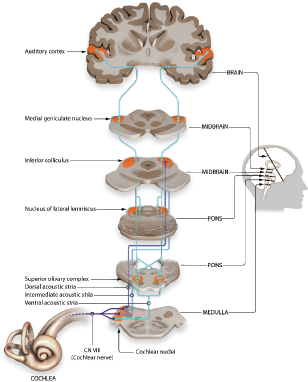
Before delving into how a listener reacts to the cocktail party speech mixture, it will be helpful to review how the human brain completes the speech perception process. Speech perception occurs within a hierarchical processing system in the auditory system, involving several core brain regions [91]. A typical example is depicted in Figure 2. The speech is produced by the vocal folds and primarily received by the inner ear. The cochlea, as the main hearing organ in the inner ear, contains numerous nerve endings that convert sound vibrations into electrical impulses. These impulses, which correspond to different pitches or frequencies of sound, are then transmitted along the auditory nerve. These electrical impulses are further processed by various auditory nuclei, allowing for the estimation of physical characteristics such as spatial location cues by comparing signals from both ears. Finally, the auditory information reaches the auditory cortex, where the streams of nerve impulses are converted into meaningful sound, and multiple brain regions are engaged in the comprehension of speech.
Although the auditory system processes speech in a hierarchical manner, it cannot be solely regarded as a linear, feedforward process. Traditional perception theories previously suggested that the brain processes stimuli in a bottom-up manner, constructing perceptions through the combination of sensory inputs [40]. However, recent theories propose that the brain is a dynamic system that interacts with sensory inputs [16]. This interaction is facilitated by the “top-down processing” mechanism, where perception is influenced by prior experiences and expectations. This top-down processing allows the brain to process sensory information more efficiently [89]. Furthermore, the interplay between bottom-up and top-down processing enables the brain to achieve precise perception, even in the presence of degraded sensory inputs [99].
In the field of speech perception, the brain is portrayed as a “prediction machine” where top-down expectations are constantly predicting bottom-up information [108]. Such a mechanism is especially noticeable in acoustically challenging scenarios. Despite potential degradation of the speech signal, such as background noise, overlapping speakers, or minor disruptions during communication, individuals with normal hearing can still, to a certain degree, follow the speaker. The predictive coding theory [13] offers a plausible explanation for this phenomenon, suggesting that top-down information generates prior expectations about speech content. This top-down information is constructed based on sensory inputs from various domains, such as speaker identity, speech knowledge, and language comprehension, and is further consolidated as cognitive factors. This also explains why, when people listen to strangers speak, their speech perception efficiency gradually improves over time, all due to the accumulation of the speaker’s prior knowledge [91].
In the cocktail party problem, the top-down processing mechanism is also essential for speech perception. Previous studies have demonstrated that the brain responds to all stimuli, and top-down attention forces the neural activity to be selective in order to construct a representation only of the attended stream [3]. Consequently, decoding the target speaker in a noisy social environment necessitates extracting the relevant stream from the brain’s signals, a task often accomplished using biological signals.
3 Speech Reconstruction from Brain Signal
Researchers have spent decades trying to figure out the neural representations of speech signals along the brain’s auditory system. The stimulus reconstruction was proposed to interpret neural responses in the stimulus domain intuitively [4]. However, with the advent of the BCI concept, it is thought that reconstructing speech from the human auditory cortex is one of the ways for machines to establish direct communication with the brain. Considering the sampling rate gap between speech signals and brain signals, the reconstruction target is typically chosen as acoustic representations rather than the original waveforms.
The acoustic representations of the stimulus fall into two categories, i.e., discrete units and continuous speech. Common discrete units used include phonemes [68], phonetic categories [58], and words [67]. However, using discrete units eliminates prior knowledge provided by the top-down processing mechanism, such as paralinguistic information (e.g., speaker identity). Therefore, in this section, we concentrated on reconstructing the acoustic representations of continuous speech from continuous electronic brain signals. Previous studies primarily employed acoustic representations in either the time-frequency domain, such as the magnitude of the Short-Time Fourier Transform (STFT) spectrogram or Mel spectrogram, or the temporal domain, such as the envelope [44, 88]. Typically, brain signals are collected using multiple electrodes, making the stimulus reconstruction a multiple-input-multiple-output (MIMO) process when using time-frequency representations and a multiple-input-single-output (MISO) process when using temporal representations.
Regardless of representations, the concept of reconstruction can be divided into two categories: linear and nonlinear. The linear stimulus reconstruction method is first introduced in [79] and further adopted in various tasks, including the cocktail party problems. The fundamental idea of the linear stimulus reconstruction method is estimating a linear mapping between the acoustic representations and the population neural activity. With the spectrogram as an example, let us denote the ground-truth spectrogram as S(t, f) and the reconstructed spectrogram as Ŝ(t, f). With the response at electrode n at time t as R(t, n), the linear reconstruction is described as [79]:
where g(τ, f, n) represents a spatio-temporal filter that maps R(t, n) to S(t, f). When the stimulus is an envelope, the filter becomes only temporal, and linear reconstruction is described as:
The estimation of the filter g(·) is achieved by reducing the mean squared error (MSE) between the actual and reconstructed stimuli through the use of normalized reverse correlation.
By combining recent advances in deep learning, the nonlinear methods based on deep neural network (DNN) [4, 118] have significantly improved the reconstruction accuracy. In these methods, the stimulus reconstruction can be described by a composition of 2 networks with specific functions as:
where F(·) denotes the feature extraction network that reflects the neural responses R to high dimensional. Α(·) denotes the feature summation network that nonlinearly regresses the high dimensional representations to the acoustic representations Ŝ. On one hand, deep learning models have demonstrated their effectiveness in capturing statistical patterns of speech signals accurately. On the other hand, nonlinear regression methods have shown remarkable results in reconstructing the nonlinear encoding of speech features in neural data.
The works in the field of stimulus reconstruction also benefit speech perception in cocktail party problems. Research has shown that the human auditory system is capable of reconstructing the representation of the speaker being attended to and suppressing irrelevant speech, as if the person was listening to that speaker alone [62, 78, 88]. Besides, it has been verified that the selection of the acoustic representations of the stimulus [71] and the selection of frequency band of the brain signals [114] will significantly impact the estimation of the attentions in cocktail party problem.
In the prior studies, it was found that the attended speech envelope, that is a low-frequency component of the original speech, can be reconstructed from brain signals, such as ECoG or sEEG. The low-frequency signal can be used to identify the attended sound source, therefore, detecting the attended speaker. Unfortunately, ECoG or sEEG signals are collected from invasive devices, which is not practical for daily applications. The non-invasive EEG signals can be a convenient substitute [62, 70]. However, EEG has a lower signal-to-noise ratio, higher sensitivity to movement and artifacts, and lower bandwidth than ECoG or sEEG. Normally, most EEG studies focus primarily on the low-frequency range, including the δ (< 4 Hz), θ (4-8 Hz), α (8-12 Hz), and β (13-30 Hz) bands that are commonly associated with speech production and perception in the human cortex [30]. Unfortunately, the gamma-band (around 70-150 Hz) within this range tends to be overlooked [103]. However, it is important to recognize that the γ-band has demonstrated a strong correlation with perception, cognitive function, and motor tasks [31].
To summarize, studies show that it is possible to reconstruct low-resolution speech stimuli from brain signals. This lays the foundation for auditory attention detection (AAD). By combining a speech separation module that separates multiple speakers from an input speech mixture [49], i.e. cocktail party, and an AAD module that detects and selects the attended speech or speaker, one may construct a neuro-steered hearing device.
4 Typical EEG-based Auditory Attention Detection
At a cocktail party, it’s common to have multiple speakers talking at the same time. For ease of illustration, we only limit our discussion to two competing speakers, i.e. an attended and an unattended speaker. Most existing AAD models assume the availability of clean speech from the mixture of speakers during run-time inference, so as to find the correlation between such clean speech and the EEG signals.
Let’s denote a decision window of three time-aligned signals, i.e. the attended speech source, the unattended speech source, and the EEG signals as s0, s1, and e respectively. As will be discussed later, AAD aims to detect the attended speaker or locus index, which is denoted as y ∈ {0,1}, representing one of the two speakers. As human attention may switch between the two speakers, a long speech-EEG signal can be segmented into a number of decision windows of length τ. The AAD function can be formulated as follows,
where Α(·) is also called the window-wise AAD function in the rest of this paper. There are two typical ways to implement the AAD function, stimulus reconstruction or direct classification.
4.1 Stimulus Reconstruction
The stimulus reconstruction approach seeks to reconstruct the attended stimulus from the EEG signals and detect the attention in three steps.
1) Speech feature extraction
Since speech signals are sampled at a higher rate than EEG signals, it is essential to extract speech features that are synchronized with the EEG signals. Such monaural speech features can be represented by either one single signal (e.g., envelope [12, 88, 113]) or multiple signals (e.g., spectrogram). Let’s denote the feature of s0 and s1 as f0 and f1, the feature extraction can be described by a function,
For instance, F(·) could be a speech envelope or a spectrogram. 2) Stimulus reconstruction
The mapping between acoustic features of speech stimulus and observed EEG signals can be done in both ways [6, 74]. In this paper, we only discuss the reconstruction of acoustic features from EEG signals. Let’s denote the output of the decoder as , the mapping can be described as:
The prediction function D(·), also discussed in Section III, can be implemented by either linear regression or non-linear DNN.
3) Attention selection
With the reconstructed stimulus and the actual stimuli f0 and f1, one may easily detect the attended speech source by comparing through a similarity function C(·), e.g. a cosine similarity or Pearson correlation, we have and .
4.2 Direct Classification
The direct classification approach [29] doesn’t rely on the reconstructed stimulus. It employs a neural network R(·) that takes the EEG signals and two speech features as input, and predicts the attended speaker through a regression function.
R(·) can be a neural network to perform the regression task. In [29], R(·) is achieved with 2 convolutional layers and 4 fully connected layers, that are trained with the cross-entropy cost function.
5 Deep Learning Approaches
With the advent of deep learning, several EEG-based AAD studies have reported superior performance to traditional methods. The success of deep learning approaches is built on the previous studies, namely stimuli reconstruction and direct classification, that can be summarized in three aspects.
1) Deep stimulus reconstruction
Deep learning models have shown superior performance for regression tasks in signal processing. The stimulus reconstruction task can be considered as an EEG-to-speech regression. It is generally believed that higher quality speech reconstruction leads to more accurate auditory attention detection for stimulus reconstruction approach to AAD. There have been recent studies exploring deep learning techniques for high-dimensional representations. For instance, the CNN-based vocoder [4], the dilated convolutional neural network [1, 2, 94], Long Short-Term Memory (LSTM) based [82] and, etc. With the improved modeling capability, these deep learning models improve the reconstruction quality with a short decision window, therefore, lower detection latency.
2) Deep EEG representation learning
Deep learning is known for its capability to learn representations that are highly effective for various downstream tasks, often outperforming traditional feature extraction or selection techniques. EEG signals pose significant challenges due to their high levels of noise and dimensionality, making traditional feature representations less effective. In light of the successes of deep learning in signal processing and pattern classification, deep representation learning has emerged as a compelling alternative for EEG analysis.
One approach is the use of a CNN-based model as described in [82], which employs a data-driven approach to find the optimal representation. The other approach leverages prior knowledge from neuroscience to apply deep learning techniques and extract specific information from EEG signals. For example, a frequency-channel neural attention mechanism was introduced in [23] to dynamically assign differentiated weights to EEG signals based on their differing physiological origins. Additionally, the use of a Spiking Neural Network (SNN) has been explored in [18, 41] to learn the EEG representation from alpha power. The SNN is designed to imitate the neural computation and coding strategies in the brain, making it a promising approach for EEG representation.
3) Deep regression model
To associate EEG signals with speech stimuli, a regression model is often employed in either direct classification or stimulus reconstruction techniques. Notable examples of successful approaches include linear methods and nonlinear neural networks. Deep neural networks represent the recent advances [19], where cross-model attention was used to dynamically adjust the weights of audio components based on the EEG attention vector, and show superior AAD performance.
However, it is important to note that EEG-based AAD is primarily studied in controlled laboratory settings with acoustic environments. To facilitate the application of EEG in real-world BCI systems, such as neuro-steered hearing devices, several implementation challenges must be addressed. In the following section, we will delve into these practical considerations and discuss their significance.
6 Towards Neuro-steered Hearing Devices
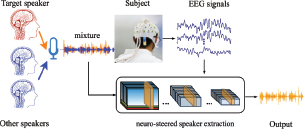
Figure 3 depicts a general diagram of a neuro-steered hearing device for speech perception. The microphone picks up a speech mixture, whereas the wearable EEG device records the corresponding EEG signals. The neuro-steered hearing device, guided by the EEG signals, seeks to extract the desired targeted speech from the mixture. In other words, the EEG-based AAD directs the speaker extraction mechanism to focus the attention on the target speaker. Therefore, a neuro-steered hearing device is also called neuro-steered speaker extraction. We next summarize the studies to overcome several implementation challenges.
The clean target speech stimulus is unavailable during training and testing.
The practical EEG signal acquisition on the move.
The label of the attention is not available during training.
There have been studies in addressing the challenges, that also point to the emerging research directions as summarized next.
6.1 Modeling without Clean Speech Stimuli
In a real-world acoustic environment, it is technically challenging to record the individual sound sources that make up a speech mixture. The individual sound sources are required as the reference during the training of an auditory attention detection model. Capturing each individual sound source during run-time inference is nearly impossible, which necessitates the development of neuro-steered speaker extraction solutions that can function without clean speech stimuli.
6.1.1 Training AAD Model with Separated Speech as Reference
A neuro-steered speaker extraction can be implemented by two parallel processes, speech separation, and auditory attention detection. Van Eyndhoven et al. [109] combined EEG-based auditory attention detection and non-negative blind source separation to effectively eliminate interfering sources, including the speaker not being attended to, from noisy multi-microphone recordings in a two-speaker acoustic environment. With the conventional envelope-reconstruction-based AAD and classical energy-based blind source separation, a system [11] was reported to show promising results in a cocktail environment. The viability of such an approach was further tested in [33], where the focus was on a binaural hearing aid in noisy environments with same-gender speakers positioned in different relative locations. Deep clustering [59] was used as the DNN-based speech separation algorithm instead of the previously utilized training-free linear signal processing algorithm. The findings of the study indicated that AAD utilizing linear methods yielded comparable or superior performance compared to pure DNN-based methods. Multiple microphones were shown to improve speaker separation and the AAD performance over a single microphone. Despite the positive outcomes, one should note that both of these studies still necessitate the use of clean speech stimuli during training or calibration to develop the EEG decoder. This means that the need for clean speech stimuli has not been completely eliminated.
In real-world situations, it is not always necessary to separate all sources as a listener typically is interested in one of the speakers. Ceolini et al. [25] introduced the Brain-inspired Speech Separation (BISS) model which directly performs speech extraction, without the need of speech separation. In this study, a brain decoder is trained first to translate the brain signal into the speech envelope, which is then used as supplementary information along with short-time Fourier transform (STFT) features to train the extraction mask. Additionally, in [63], a Brain Enhanced Speech Denoiser (BESD) was proposed for end-to-end speech extraction from a mixture using Feature-wise Linear Modulation (FiLM) [92]. While the end-to-end training in BESD is simpler than the two-step approach in BISS, its performance is behind the state-of-the-art. Generally, the performance of deep learning-based speech extraction models is largely impacted by the availability of a large training dataset, which can be challenging to obtain using cocktail party datasets. In comparison, the extraction network in BISS was trained using a large artificial dataset, resulting in robust and good extraction performance.
In short, there have been studies to avoid the need of clean speech stimuli for auditory attention detection modeling. This can be achieved by working with a separately trained speaker extraction or speech separation model.
6.1.2 Training Spatial AAD Model without Speech Reference
Other than detecting the attended speaker, it is possible to detect the spatial location of the target speaker from EEG signals. It was found in neuroscience research that the location of auditory attention is reflected in brain activity [45, 114]. This has motivated the study of a particular type of EEG-based AAD to detect the spatial location of the target speaker, even in noisy or cluttered environments. This is also referred to as spatial AAD. There are two types of models, linear and nonlinear, in general. The spatial AAD takes a collection of EEG signals as input and predicts the contrastive spatial location of the attended speaker, e.g. left or right, front or rear. The training of such an AAD model doesn’t rely on clean speech stimulus as the reference.
Bednar et al. [8] demonstrated that EEG responses to stimuli from different directions could be accurately classified using a support vector machine (SVM) with a success rate significantly higher than the chance level of 25%. Furthermore, it was shown that EEG data could be utilized to track the path of an attended sound source with a linear reconstruction model [9]. Although a linear reconstruction model was employed in their study, its performance was inferior compared to envelope-based methods. Geirnaert et al. [51] implemented a data-driven linear filtering technique called filterbank common spatial pattern filters (FB-CSP) to achieve fast AAD, which outperformed the stimulus reconstruction approach in terms of accuracy on short signal segments. Further improvement was achieved by using a Riemannian geometry classifier instead of a traditional CSP filter [54].
Just like in many pattern classification tasks, the convolutional neural network (CNN) is an effective nonlinear model that detects the spatial focus of attention in multi-speaker scenarios [110]. The algorithm is effective in making accurate detection within 1-2 seconds. Feature representation is a crucial aspect of AAD, as raw EEG signals have low signal-to-noise ratios. To tackle this issue, Cai et al. [24] developed a method for spectro-spatial feature extraction in AAD using a CNN based on the alpha power’s topographic specificity. This was followed by the development of the end-to-end spatiotemporal attention network (STAnet) [102]. STAnet integrates spatial and temporal attention mechanisms to capture both the modulation weights of EEG channels and the relevant temporal features of AAD. This spatiotemporal encoding method provides higher information density and outperforms traditional linear and non-linear methods on two widely used datasets. The use of deep learning in AAD has led to the development of more effective algorithms, and with continued advancements in feature extraction techniques, we can expect these algorithms to continue to evolve and make a significant impact in the field.
6.2 Simplifying EEG Acquisition
A sophisticated EEG cap is commonly required for EEG signal acquisition. For a practical neuro-steered hearing device, we call for a simplified EEG signal acquisition setup.
6.2.1 EEG Channel Selection
To simplify the standard EEG cap, it is desirable to remove some redundant EEG electrodes. The channel selection techniques are proven effective [81]. A low-density setup is expected to improve wearing comfort and reduce preparation time.
Mirkovic et al. [81] performed an iterative backward elimination algorithm to reduce electrodes from the initial electrode set and reported the first evidence that detection performance remains stable at a low number of EEG electrodes (from 96 channels to 25). Narayanan and Bertrand [83] developed a miniature
EEG device by using a greedy group-utility-based channel selection strategy and optimizing the channel combination through a mixed integer quadratic equation (MIQP) solver. They also examined the effect of reducing the inter-electrode distance and found that accuracy decreases significantly when the distance is less than 3 cm [85].
Unlike hard selection of EEG channels, some studies seek to adjust the weighting of EEG channels to derive more discriminative representations of AAD [22, 101], that is soft selection. This approach leverages the fact that some channels provide more insight into the brain’s decision-making process in AAD, while others may provide less information. By assigning different weights to different channels, soft selection takes full advantage of the information provided by all channels, resulting in a more complete picture of AAD. In comparison to the hard selection, the soft selection is better suited to handle the variability and complexity of EEG signals, which can often be difficult to capture using a fixed set of channels. By taking a more flexible approach, the soft selection is able to account for the variability of EEG signals and provide a more accurate representation of AAD.
6.2.2 Ear-EEG
In practical AAD tasks, the EEG signals are acquired from the subjects in a real-world environment as opposed to a controlled setup in the lab. Unfortunately, conventional scalp EEG data collection is typically done in the lab, which is cumbersome and unsuitable for mobile applications. To address this, ear-EEG has been developed as an alternative to traditional scalp EEG. It provides less coverage of the brain but has the benefit of being more convenient and portable.
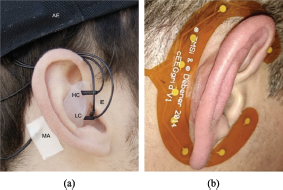
As shown in Figure 4 (a), in-ear EEG places multiple electrodes in the external auditory canal and over the outer ear through individualized earplugs [73]. Several studies have demonstrated that relevant neural signals can be successfully extracted from in-ear EEG recordings for AAD purposes [15, 65]. Despite having weaker amplitude compared to scalp EEG recordings [42, 43], in-ear EEG provides a convenient, portable, and virtually unnoticeable solution.
The around-the-ear EEG approach utilizes electrodes that are positioned close to the ear in a circular configuration around the outer ear, as shown in Figure 4 (b). Debener et al. [36] introduced the first flexible, printed Ag/AgCl electrode system with 10 electrodes arranged in a c-shape to fit comfortably on the ear. It’s called cEEGrid and offers a promising solution for neuro-steered hearing aids. A series of validation studies demonstrated that the cEEGrid could achieve reliable ear-EEG recordings [14, 66, 77]. Denk et al. conducted a comparison between the signal properties of around-the-ear and in-ear EEG electrodes [38]. They found that around-the-ear electrodes had several advantages over in-ear electrodes, including larger amplitude, improved channel independence, and a higher signal-to-noise ratio (SNR). These benefits were attributed to the greater inter-electrode distance in around-the-ear EEG recordings.
Inspired by these findings, several research explored whether ear-EEG recorded by cEEGrids can be used for detecting auditory attention. The study by Mirkovic et al. [80] was the first to show that the cEEGrid ear-EEG method can detect the attended speaker with an average accuracy of 69.3%, which is above the chance level. On the other hand, the 84-channel cap-EEG resulted in an accuracy of 84.8%. This difference in accuracy can be attributed to the signal loss from the scalp to the ear. Specifically, Meiser and Bleichner [76] found that cEEGrid ear-EEG recordings showed a reduction in signal loss of 21% to 44% for four different auditory ERPs (N100, MMN, P300, and N400), when compared to 96-channel cap-EEG. Despite the lower AAD accuracy, the cEEGrid method has a practical advantage as it is portable, operated using a smartphone, and nearly invisible [64]. It is worth noting that Holtze et al. [61] modified the cEEGrid ear-EEG method incitemirkovic2016target with individually chosen hyperparameters and significantly improved AAD performance. This also suggests that cEEGrid has the potential to be considered as a suitable EEG acquisition tool for use in neural-guided hearing aids, and thus, deserves further investigation to improve its performance.
6.3 Unsupervised Learning
Training an AAD model, one may expect that the label of the attended speaker is known. However, such a label collection procedure is labor-intensive and less practical in hearing devices. Therefore, unsupervised learning could be an alternative [52, 53]. The first AAD work based on stimuli reconstruction approach with unsupervised learning is proposed in [53]. It assumes that only the two envelopes of the competing speakers and EEG data are presented during the training phase.
As it has been verified that the brain encodes attended and unattended speakers differently, it is possible to identify which envelope is the attended one and which one is unattended by using a decoder. This can be done by iteratively replacing the ground truth attention labels utilized in supervised training with the predicted labels obtained from the testing phase. This creates a self-reinforcing effect, where each iteration improves the decoder’s performance, even in the presence of labeling errors. This idea has been expanded upon in a study by Geirnaert et al. [52], who developed a time-adaptive, unsupervised stimulus reconstruction method that operates online. The method continually adjusts and improves itself as new EEG and audio data streams in, through the use of sliding window training or recursive training. Both of these methods perform better than traditional time-invariant supervised decoders.
6.4 AAD for the Hearing-Impaired
While EEG-based AAD is mostly studied for normal hearing (NH) subjects, neuro-steered hearing devices could assist hearing-impaired (HI) subjects as well. In most of the publicly available EEG-based AAD datasets, the listening subjects are mostly young and normal-hearing people, that don’t represent the demography of the hearing impaired. Globally, 34 million children are deaf or have hearing loss, and approximately 30% of people over the age of 60 have hearing loss [26]. Caution should be taken before applying previous results or technologies to detect auditory attention in subjects with hearing impairments.
Hearing loss in children can be present at birth (congenital) or develop later in childhood (acquired). As for elderly people, several studies have shown that, in addition to peripheral hearing loss, speech perception is also affected by changes in brain structure as well as changes in brain function [57, 106, 115]. Given that aging and hearing loss are major causes of neuromodulation decline in the listening brain [57, 107], AAD research needs to take these effects into account. Nogueira et al [86] first compared the EEG-based AAD performance of NH and HI listeners. 12 NH listeners (age: 26 ± 4.4 years) and 12 bilateral implanted cochlear implant users (age: 60 ± 11.0 years) were involved in this study. Results demonstrated that in principle it is possible to detect selective attention in individuals with HI with an accuracy of up to 70%, while an average accuracy of NH listeners is higher than 80%. This is also supported by that the HI listeners rated the competing speech task to be more difficult [46]. Meanwhile, some studies have also verified the feasibility of detecting selective attention through the ear-EEG signals of HI subjects [48, 55, 87].
6.5 Implementation of Practical Hearing Devices
To bring the above AAD research from the laboratory to real life, there are many other challenges that we need to overcome.
It is known that movements and distractions are reflected in brain signals associated with auditory attention during daily life. However, most AAD research has so far been performed in controlled laboratory settings. This potentially limits the generalizability of existing studies to complex acoustic environments outside the laboratory.
A practical system calls for real-time detection of auditory attention. Usually, a complex model leads to high accuracy when operating at high temporal resolutions. However, the computing cost and the limited data resource need to be taken into consideration. We need to find a tradeoff between the model’s complexity and accuracy. Furthermore, real-time implementation is a causal system that can only use historical data. That is different from the offline system.
The coupling between the AAD system and the hearing device is also a challenge. A fully mobile EEG recording system is needed. Moreover, a compact design that includes brain signal acquisition, processing, speech signal acquisition, and processing units, and their communications. Furthermore, it usually introduces communication delays between hardware components.
However, this study is still in its infancy. In [60], cEEGrids were placed near the left and right ears of the participants to record ear-EEG signals related to speech perception. For the first time, this was done for a continuous period of six hours as the participants carried out various activities such as working on a computer, conversing with coworkers, and taking lunch breaks, while also performing auditory oddball tasks in and out of the laboratory. The results indicated that the participants were able to differentiate between target and non-target sounds even while engaged in their daily activities. Additionally, it was found that the participants had higher ERP amplitudes in response to target tones as compared to standard tones. These findings suggest that it is possible to study auditory attention outside of traditional laboratory settings.
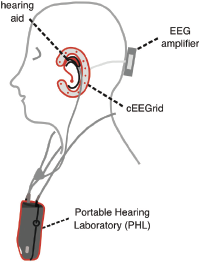
Inspired by this, a hearing aid-EEG research platform has been developed in [34, 35]. As shown in Figure 5, the Portable Hearing Laboratory (PHL) is a comprehensive hearing aid research system that can be used to present auditory stimuli to subjects and perform low-latency audio signal processing.
As for the EEG system, it consists of cEEGrid, a mobile EEG amplifier, and a smartphone. Therefore, both audio and EEG data can be acquired and synchronized using this hearing aid-EEG research device. While the PHL and cEEGrid are not entirely suitable for daily use, this setup provides a potential platform for exploring closed-loop EEG & audio applications in a research context.
7 Datasets for Auditory Attention Detection Study
In recent years, there are few EEG datasets suitable for AAD research. Typically these datasets were collected from a dozen of young normal-hearing subjects. To reduce the cognitive load, it is best that we recruit speakers to listen to their native languages. Since the data were recorded in different countries, the languages vary from dataset to dataset. The characteristics of all publicly available data sets are summarized in Table 1.
The collection of AAD datasets typically follows a similar procedure. Take ESAA [20, 21] as an example, the participants were instructed to focus on one speaker while disregarding the other in a scenario with two overlapping speakers. The speech material consisted of various Chinese narratives narrated by two native speakers and was normalized to have the same root mean squared intensity, making the stimuli appear equally loud. The stimuli were processed using a head-related transfer function (HRTF) to simulate speech sources located at 90-degree intervals to the left and right of the subjects. EEG data was acquired using a BrainAmp system operating at a sampling rate of 8,192 Hz, with a 64-channel recording setup. To ensure that the participants were attentive during the experiment, participants were asked to complete a multiple-choice questionnaire following each trial to assess their comprehension of two separate narratives. To avoid fatigue or loss of focus, participants were given short breaks after each trial and longer breaks after 8 consecutive trials. To control for potential biases, the position of the target streams and the gender of the speakers were randomized for each participant throughout the course of the experiments.
Overall, the size of AAD datasets is highly limited, especially in the context of deep learning. This calls for a great effort in data collection. Furthermore, there is a rising interest in augmenting speech processing tasks with additional biological signals [97], such as surface electromyography (sEMG) and Electrooculography (EOG) signals. The integration of these multimodal physiological signals holds promise for AAD-enabled applications. Such studies rely on multimodal physiological signals to unlock the AAD potential.
8 Challenges and Directions
EEG-based speech perception has achieved promising success in solving the cocktail party problem, but there are challenges associated with its adoption for neuro-steered hearing devices that merit further discussion.
8.1 Process of the Noisy EEG Signals
Several traditional signal processing techniques have been studied in the area of EEG-based speech perception, as demonstrated in recent review articles [29, 49]. Despite these efforts, the EEG signal still exhibits a poor signal-to-noise ratio, resulting in limited success in achieving optimal AAD performance.
Deep learning techniques that process raw input data are referred to as representation learning methods. The objective of representation learning is to extract the most significant features from raw data, leading to improved pattern recognition performance [10]. Unfortunately, most previous AAD architectures have not benefited from representation learning. In recent years, some researchers have suggested the use of advanced deep learning methods [23, 102], which have the potential to extract discriminative features that can improve AAD performance. Therefore, it is worth further investigating deep learning frameworks that extract representations directly needed for classification or detection from raw EEG signals. Specifically, to extract relevant attention features from raw EEG, information about the EEG signals needed to be further exploited, e.g., the characteristics in the time, frequency, and spatial domains. However, because most deep learning models benefit from large model sizes, how to adapt them to AAD’s small dataset remains a challenge. Transfer learning has gained popularity in EEG signal processing as a potential solution to overcome the limitations of small datasets [111]. This technique involves utilizing pre-trained models that have been extensively trained on larger EEG datasets or similar tasks. The pre-trained models are then fine-tuned using smaller, task-specific EEG datasets. By leveraging the knowledge acquired during pre-training, transfer learning allows for rapid adaptation towards specific EEG-based AAD tasks [117].
8.2 Generalization of AAD models
There are two main aspects of generalization. One is the generalization across subjects, another is the generalization across scenarios.
The variability of brain signals in individuals presents a challenge for EEG-based BCI systems, particularly in subject-independent conditions. Brain signals of each individual can change over time due to differences in their physiological and psychological traits [69]. Additionally, the unique spatial origin, amplitude, and variability of brain signals can make it difficult to detect auditory attention tasks in a subject-independent manner [95]. In general, traditional auditory attention detection methods in EEG-based BCI systems work well in subject-dependent conditions but struggle in subject-independent conditions. This may be due to the fact that brain signals from different individuals are highly variable, discriminative, and carry specific meaning in auditory attention detection tasks. To compensate for these variations, BCI systems often require a calibration process, which adds an extra burden for the user and hinders the practical use of BCIs.
In addition to generalization across subjects, generalization across scenarios is also a challenge for EEG-based BCI systems. Most AAD studies are conducted in controlled laboratory settings, which limits the generalization of findings to complex acoustic environments in real-life scenarios. In real-life situations, subjects often handle multiple tasks, which are reflected in their brain activities. Selective listening is just one of these tasks, and detecting auditory attention from the mixture of brain activities in EEG signals is an area that requires further study.
8.3 Complexity, Cost, and Tracking Latency
In most auditory attention studies, we make a decision based on a single window of the signal. However, selective listening in the human brain is a continuous process. It is likely that human cognitive resources, loaded by the cognitive process of auditory attention to the speech sources, are affected by its previous cognitive states, as well as other factors such as distracting auditory events, moving auditory events, or other cognitive and motor activities. In short, tracking auditory attention is of practical need and yet an unexplored challenging research problem.
In general, deep neural networks have a high demand for energy consumption, data requirements, and computational power. However, these demands are particularly pronounced in BCI applications, including neuro-steered hearing devices, due to the limited data size, energy supply, and the need for real-time response. To address these challenges, various hardware accelerators have been developed to manage the high computational demands of deep learning models. Despite these advances, there remains a need for a low-cost, energy-efficient AAD algorithm that can be implemented on a single chip.
The human brain is a sophisticated network of neurons and synapses that transmit information through electrical impulses referred to as spikes. This remarkable processing capability has led to the evolution of spiking neural networks (SNNs) as a potentially valuable computing framework. SNNs operate by allowing neurons to communicate with each other through spikes with adjustable weight values that are transmitted via synapses connecting the neurons [72]. Research has demonstrated that the low computational cost of SNNs makes them well-suited for deployment on low-power hardware [104].
Considering that the AAD model is built to process brain signals, a brainlike model should be a natural choice. The utilization of SNNs in AAD offers several advantages over traditional deep learning models. Unlike deep learning models, SNNs are capable of processing data in real-time and can effectively handle noisy and unstructured data. Additionally, SNNs consume significantly less power compared to deep learning models, making them ideal for practical deployment. The ability of SNNs to simulate the dynamic nature of biological neurons and model the temporal relationships between spikes is also beneficial for AAD applications.
In conclusion, SNNs represent a promising computing paradigm that offers several advantages over traditional deep learning models. The low computational cost, real-time processing capabilities, and ability to handle noisy and unstructured data make SNNs a suitable choice for AAD applications. Further research in the field of SNN-based AAD is encouraged, as it has the potential to lead to exciting new developments in this field.
8.4 Connection between Speech Separation and AAD
As the two sub-fields of speech perception in cocktail party environments, the development speed of speech separation and AAD are imbalanced, especially in the deep learning era. For speech separation, it is easy to generate the mixture from the public speech corpus, leading to a low cost of data acquisition. Therefore, current speech separation models employ deep learning to improve representative learning and dependency modeling and achieve amazing success.
However, for the AAD, these sophisticated models are not so easy to exploit. Given the collection of EEG data is labor-intensive, the small size of the AAD dataset makes the training of the deep learning models easy to overfit. Besides, although assistive speech perception can be achieved by the pipeline of speech separation and AAD, it is not clear whether the two local optimal achieve the global optimal. In other words, the impact of the artifacts introduced by speech separation on the AAD is not clear. The end-to-end training could be a potential solution, however, as indicated in [25], the performance is still limited by the data size. Although the separation data are easy to make, it is almost impossible to have the equivalent EEG data. Besides, the separation module usually introduces the permutation problem, which means the sequence of the output separated speech is usually randomly which may affect the performance of the AAD training. Although permutation invariant training (PIT) [119] can be adopted in the training stage, it cannot be employed in the online separation phase given the latency issue.
Moreover, there is no consensus on how to evaluate these pipeline systems. As the performance of speech separation is measured by SI-SNR whereas the AAD is evaluated with accuracy. In some cases, System A might perform better than System B on separation performance but worse on AAD accuracy, the comparison becomes confusing. In addition, as the AAD accuracy is closely related to the length of the decision window, a longer decision window indicates higher accuracy, but is less sensitive to attention shifting. Thus, from the perspective of speech perception, using the accuracy of AAD as a direct evaluation metric may also not be appropriate. Besides, the gain control of speeches for continuous decoding in a cocktail party environment generates another problem. As sudden switching of speakers (of which many by mistake) cause perceptually unpleasant spurious. Although an interpretable performance metric for AAD algorithms has been developed with adaptive gain controls in [50] using a Markov chain model, which assumes independence between consecutive decisions. However, in real-world applications, data is often segmented with overlapping in order to reduce processing latency. As a result, the connection between the deep-learning-based speech separation model and AAD in the design of neuro-steered hearing devices remains an open question.
9 Conclusion
This paper provides a comprehensive overview of EEG-based AAD for speech perception in noisy environments, such as cocktail party scenarios. It covers the essential concepts and the latest developments in the field up to 2023. The paper explores the underlying mechanisms of speech perception and the ways to build a machine that mimics the human brain to solve the cocktail problem. Additionally, the paper provides an overview of the current deep learning approaches in the field, discussing their potential and limitations. Furthermore, it points out the gap between EEG-based speech perception research and neuro-steered hearing device, and provides a list of resources available to advance the research. Overall, this article is a valuable resource for anyone interested in comprehending EEG-based auditory attention detection and developing novel deep learning techniques.
Financial Support
This work is supported by A*STAR under its RIE 2020 Advanced Manufacturing and Engineering Programmatic Grant (Grant No. A1687b0033), and by Internal Project of Shenzhen Research Institute of Big Data (Grant No. T00120220002); the Guangdong Provincial Key Laboratory of Big Data Computing, The Chinese University of Hong Kong, Shenzhen (Grant No. B10120210117-KP02), the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy (University Allowance, EXC 2077, University of Bremen, Germany).
Biographies
Siqi Cai received her Ph.D. degree from the Department of Shien-Ming Wu School of Intelligent Engineering, South China University of Technology, China, in 2020. She is now a Research Fellow at the Department of Electrical and Computer Engineering, National University of Singapore, Singapore. Her research interests include brain-computer interface, and biosignal processing. She has served as the workshop chair of the 47th IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2022.
Hongxu Zhu obtained his bachelor’s degree in information engineering from Xi’an Jiaotong University, China. He further obtained his M.S. with distinction in electronic information engineering and Ph.D. in electrical engineering from City University of Hong Kong in 2016 and 2021, respectively. Currently, he is a research fellow with the Human Language Technology Lab in the Department of Electrical and Computer Engineering, National University of Singapore, Singapore. He is also a key member of the IEEE Standards Working Group P2668 and P1451.5. His research interests broadly lie in brain-informed speaker separation, machine learning, and internet of things.
Tanja Schultz received her doctoral and diploma degree in Informatics from University of Karlsruhe, Germany, in 2000 and 1995. She joined Carnegie Mellon University, Pittsburgh, PA in 2000 and is an adjunct Research Professor at the Language Technologies Institute. From 2007 to 2015 she was a Full Professor in Informatics at the Karlsruhe Institute of Technology (KIT) in Germany before she became a Professor for Cognitive Systems at the University of Bremen, Germany in April 2015. Since 2007, she directs the Cognitive Systems Lab, where her research activities focus on the processing, recognition, and interpretation of biosignals for human-centered technologies and applications. She is an ISCA Fellow and member of the European Academy of Sciences and Arts.
Haizhou Li received the B.Sc., M.Sc., and Ph.D degree in electrical and electronic engineering from South China University of Technology, Guangzhou, China in 1984,1987, and 1990 respectively. Dr Li is currently a Professor at Shenzhen Research Institute of Big Data, School of Data Science, The Chinese University of Hong Kong, Shenzhen (CUHK-Shenzhen), China, and Department of Electrical and Computer Engineering, National University of Singapore, Singapore. His research interests include automatic speech recognition, speaker and language recognition, and natural language processing. He was the General Chair of ACL 2012, INTERSPEECH 2014, ASRU 2019, and ICASSP 2022. Dr Li is a Fellow of the IEEE and the ISCA. He was a recipient of the National Infocomm Award 2002 and the President’s Technology Award 2013 in Singapore. He was the President of Asia Pacific Signal and Information Processing Association (2015–2016). He is currently a Vice President of IEEE Signal Processing Society (2024–2026).