

This paper aims to present a modular pipeline approach by combining extractive and abstractive summarisation methods in order to improve the accuracy of automatic text summarisation (ATS).
In our framework we have used LangChain [20], a large language model integration platform, to orchestrate an extractive algorithm (LexRank) and an abstractive algorithm (Bidirectional and Auto-Regressive Transformers (BART)). LexRank identifies key sentences from the input text, ensuring core information is retained without redundancy, BART is used for refining these extracted sentences into human-like, concise summaries.
We evaluated the performance of our framework by using CNN/Daily Mail, Newsroom and XSum datasets, which are widely used benchmark for summarisation tasks. Evaluation results demonstrate that this modular approach improves accuracy of generated summaries in two ways, (1) word level similarities between reference summary and generated summary and (2) semantic similarity between reference summary and generated summary.
In our experiments, we used datasets that have short length documents (within 7,000 characters). We need to perform more experiments with long documents to evaluate the robustness of our pipeline. We have not investigated error propagation from extractive phase to abstractive phase that may have an impact on the performance of our framework.
The primary contribution of this study is the development and evaluation of a modular pipeline combining LexRank, an extractive summarisation technique, and BART, an advanced abstractive model, using LangChain. The results indicate that the hybrid approach outperforms traditional single-model methods and other existing hybrid models, as evidenced by higher Recall-Oriented Understudy for Gisting Evaluation and BERTScores across various examples.
1. Introduction
In the age of digital information, the rapid expansion of textual data plays an enormous challenge for users to efficiently access and comprehend relevant information. With the Internet and various textual sources generating massive amounts of data daily, finding concise and accurate summaries is becoming increasingly essential. Automatic text summarisation (ATS) is a solution that enlightens this challenge by filtering essential information from large datasets into brief, manageable summaries [1, 2]. ATS is significant in domains like news aggregation, scientific research and business intelligence, where summarising vast amounts of data quickly and accurately is vital.
As the field of text summarisation evolves, different techniques have manifested each with their advantages and limitations [3]. These ATS techniques are often classified based on input and output characteristics [1–3]. Input-based classification is concerned with the nature, quantity and structure of the input data. It primarily includes two categories: single-document summarisation and multi-document summarisation. Single-document summarization involves summarising a single source of text, such as a news article or research paper [1, 4, 5]. In contrast, multi-document summarisation processes multiple documents, often on the same topic. This summarisation process identifies and merges overlapping information while maintaining coherence and diversity [1, 4, 5]. Output-based classification, meanwhile, is based on the form and nature of the summary generated. The two main types are extractive and abstractive summarisation. Both the approaches involve various algorithms and techniques to accomplish ATS [1, 4, 5].
Traditional extractive methods include frequency-based approaches, where words that occur frequently are assumed to be more important, and sentences containing those words are selected [4]. More advanced extractive techniques involve graph-based algorithms like TextRank [6], which constructs a graph of sentences with edges representing semantic similarity and ranks them to identify the most central ones [7, 8]. In recent past, deep learning models and pre-trained transformers (e.g. variant of Bidirectional Encoder Representations from Transformers (BERT) [9, 10]) have been utilised for extractive summarisation by exploring richer contextual relationships [4, 5].
On the other hand, abstractive methods aim to generate new sentences that paraphrase and condense the original text resembling human-like summaries [9, 11]. Traditional abstractive methods relied on rule-based or statistical approaches, which were limited in flexibility and fluency [4, 5]. The advent of sequence-to-sequence (Seq2Seq) neural networks allowed models to focus on relevant parts of the input while generating each word in the output [4, 5, 12]. Further improvements came with the introduction of transformer-based architectures, such as Bidirectional and Au-to-Regressive Transformers (BART) [7, 13, 14], T5 (Text-To-Text Transfer Transformer) [13, 15, 16] and PEGASUS [13]. Typically these models are pre-trained on large corpora and fine-tuned on summarisation datasets.
Automatic text summarisation (ATS) has shown tremendous growth but still faces obstacles where one of the key limitations of current models is the trade-off between speed and quality. Extractive summarisation selects and stitches together sentences directly from the original text, often resulting in summaries that lack coherence, context and flow [2]. These summaries may include redundant or less relevant information and may miss the document's overall meaning if key ideas are spread across multiple sentences. Extractive methods also struggle with paraphrasing and do not simplify or rephrase complex content, which makes them unsuitable for applications requiring concise or reader-friendly summaries. On the other hand, abstractive summarisation models are prone to factual inaccuracies, known as “hallucinations”, where the generated content includes information not present in the source [17]. This limits the application of abstractive summarisation in critical applications such as medical or legal summaries. Recent transformer models, such as BART and PEGASUS [13], have improved performance but continue to struggle with maintaining factual accuracy across varied domains [9]. In the recent past, hybrid method of text summarisation has evolved, and it combines extractive and abstractive summarisation to improve the performance of ATS. However, these methods have their own limitations including disjointed summary that lacks fluency or misrepresents the original text that results in inaccuracy [5]. Overall, as found in the literature, accuracy is a big obstacle in ATS and typical average accuracy achieved by various approaches is not very satisfactory [4, 7, 9, 12, 18], which is the main motivation behind this work.
In this work, we aim to address the limitation of accuracy of ATS, found in the literature, by exploring a modular pipeline approach, combining extractive and abstractive methods to leverage their strengths. As highlighted in recent research that modular systems, which incorporate multiple specialised models, can improve factual consistency and adaptability across domains [19]. Following this we have used LangChain [20], a large language model (LLM) integration platform, to orchestrate pre-trained models for extractive and abstractive summarisation of texts. More specifically, in our framework we use LexRank [7, 21], an extractive algorithm, to identify key sentences from the input text, ensuring core information is retained without redundancy. We have used Hugging Face's BART [7, 13, 14] model for the abstractive stage, refining these extracted sentences into human-like, concise summaries. We have selected LexRank and BART for the pipeline after evaluating a number of popular extractive and abstractive algorithms as discussed in Section 3. We evaluated the performance of our framework by using CNN/Daily Mail [22], Newsroom [23] and XSum [24] datasets, which are widely used benchmark for summarisation tasks. Evaluation results demonstrate that this modular approach improves accuracy of generated summaries in two ways:
Word level similarities, ensuring coverage of key information, between reference summary and generated summary, as indicated by Recall-Oriented Understudy for Gisting Evaluation (ROUGE) [25] score and
Semantic similarity between reference summary and generated summary, as indicated by BERTScore [26].
The rest of the paper is structured as follows: in Section 2, we provide an overview of recent developments in the area of ATS including categories of ATS and paradigms applied for ATS; in Section 3, we discuss the design and development of our modular framework for text summarisation; in Section 4, we present and discuss the experimental results that were carried out to evaluate our framework and, finally, in Section 5, we provide concluding remarks and recommendations for future enhancements of our modular framework.
2. Related works
The goal of ATS is to distil vast amounts of information while keeping the essential elements. As shown in Figure 1, ATS has been classified in different ways in literature, e.g. based on the input of the ATS, based on the output of ATS and algorithms or paradigms applied in the ATS.
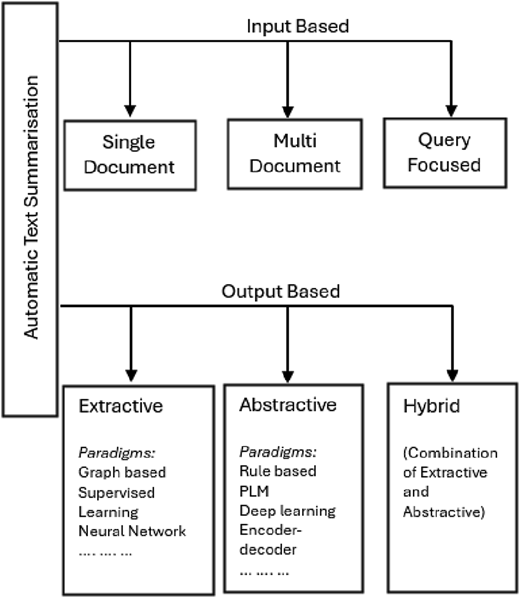
Based on the format of input to the ATS process, it has been classified as single-document, multi-document and query-focused summarisation [1 4, 9]. Single-document summarisation summarises the content of a single document, while in multi-document summarisation, multiple documents, typically on the same topic, are selected as input to generate the summary. On the other hand, query-focused summarisation tries to generate a summary that specifically addresses an input query, such as a topic or keywords.
Based on how the output summary is generated, ATS is classified into extractive, abstractive and hybrid methods [1, 4, 9, 10, 18]; extractive ATS, which selects important sentences or phrases directly from the source, has been widely used due to their simplicity and speed [1, 4, 9]. Conversely, abstractive summarisation methods aim to generate new sentences based on the original content, resembling human-like summaries that are more fluid and natural but come with higher computational complexity [1, 4, 9, 11]. Various paradigms have been applied for the realization of output-based ATS over the years [1, 4, 9], e.g. statistical methods, deep learning methods, pre-trained language model and, more recently, LLMs. A key limitation of both approaches lies in balancing speed and quality. Extractive ATS often leads to summaries that lack coherence and fluidity, as they rely on exact sentences from the original text [2, 3]; while abstractive summarisation, though more accurate in terms of meaning, is computationally intensive and prone to generating factual errors [2, 9]. Hybrid summarisation methods have evolved to combine the strengths of both extractive and abstractive methods to achieve more balanced and accurate results [4, 12].
Among the different types of ATS, output-based ATS, i.e. abstractive ATS, extractive ATS and hybrid ATS have attracted more attention in the literature [1, 4, 9, 10, 18]. In the rest of this section, we discuss the recent developments in extractive, abstractive and hybrid summarisation. We also review the data pre-processing mechanisms typically followed for the realisation of ATS.
2.1 Extractive summarisation
To increase the efficacy of extractive summarisation, a number of approaches have been developed over time. Graph-based, machine learning and deep learning-based methods are some of the most popular methodologies. Each approach has advantages and disadvantages based on the use and level of summarisation.
Graph-based techniques depict texts as nodes in a graph, with relationships – often based on similarity – reflected by the edges connecting the nodes [10]. This method is based on the intuitive understanding that significant sentences for summarisation are closely related to other significant sentences. Because of their effectiveness, simplicity and interpretability, these techniques were among the first to be developed for summarisation and are still in use today. TextRank [6–8] and LexRank [7, 21, 27], the two most popular graph-based algorithms, rank the significance of phrases using the centrality principle in graphs. TextRank was one of the first efforts to adapt the graph-based algorithm for extracting the most important sentences from a document [7]. The algorithm builds an undirected graph, where the nodes represent sentences, and the edges are weighted based on the similarity between sentences. Typically, the similarity between the sentences is computed using methods like cosine similarity or Jaccard similarity. Graph-based methods have several advantages, including their simplicity and computational efficiency [10, 27]. For example, they do not require training data, making them less dependent on annotated corpora, which can be difficult and expensive to obtain. However, these methods are often limited in their ability to capture the full semantic meaning of sentences. This is because they primarily focus on sentence similarity, which may not fully reflect the complexity of natural language and the context in which the sentences are used. Additionally, graph-based methods may struggle with handling documents that involve ambiguous or nuanced language. The fuzzy logic-based approach is also employed to identify the most important sentence from the source document or context. However, to achieve improved results, it requires the application of a redundancy removal technique [5, 12, 28].
Supervised learning techniques for extractive summarisation require labelled datasets with human-generated summaries. Features such as sentence length, term frequency, sentence position and semantic similarity are extracted and used to train models like support vector machines, logistic regression or random forests. These models learn to classify sentences as either important or unimportant based on their features. Once trained, the model can select key sentences for summarisation [15, 29, 30]. Despite their widespread popularity, supervised machine learning techniques do have several drawbacks. The largest obstacle is the requirement for extensively annotated datasets, which aren't always accessible, particularly in specialized fields. Furthermore, these techniques may have trouble generalizing, especially when used on texts with writing styles or domains that differ greatly from those used for training. Notwithstanding these difficulties, supervised learning approaches have demonstrated considerable promise, especially in fields requiring domain-specific summarisation tasks or where labelled data are accessible [4].
By using neural networks to automatically learn features from data, deep learning-based techniques have completely changed extractive summarisation by eliminating the necessity of manually created features. These methods, specifically recurrent neural networks (RNNs) [4, 9] and, more recently, transformer-based architectures, are able to understand the complex syntactic and semantic relationships between words and reflect long-range dependencies in the text. Extractive summarisation has been accomplished by recurrent neural networks (e.g. long short-term memory [4, 9]), in which model sentence dependencies choose phrases according to their significance to the entire manuscript. Because the meaning of a sentence frequently depends on the sentences that come before or after it, RNNs are especially well suited for sequential data, such as text. Transformer models are another innovation in deep learning-based extractive summarisation. These models calculate the relative value of each word or sentence in the document using attention mechanisms. One particularly significant contribution in this area has been Bidirectional Encoder Representations from Transformers [9, 10], which is a general pre-trained model that can be used for various applications in natural language processing (NLP.) By optimizing BERT for summarisation tasks, it can better comprehend sentence relationships and context, which makes it very successful at selecting the most important sentences in a document. Among the many benefits of deep learning-based approaches is their capacity to comprehend intricate linkages and adjust to a broad range of data. Because models like BERT can be pre-trained on big datasets and adjusted for certain tasks or domains, they are also incredibly versatile. However, there are drawbacks to deep learning models, including the requirement for a lot of labelled data, the processing power needed for training and the models' interpretability.
2.2 Abstractive summarisation
There are various approaches to abstractive summarisation implementation. Among the most well-known methods are Seq2Seq models and transformer-based pre-trained language models.
Seq2Seq (also known as encoder-decoder) models are the fundamental architecture for abstractive text summarisation [31]. These models comprise of an encoder and a decoder. In typical scenario, the encoder identifies and parses the input sequence and then utilizes high dimensional dense feature vector to characterize the input sequence. The decoder of the model then uses the feature vectors of the input items to generate the output items. Seq2Seq models do, however, have certain drawbacks, such as they have trouble sustaining long-range dependencies, which are essential for comprehending the document's whole context. Furthermore, the encoder's fixed-length vector might not adequately represent the document's complexity, which makes it challenging for these models to produce grammatically and fluently accurate summaries [32]. Seq2Seq models, despite these difficulties, helped to promote abstractive summarisation and are still a basis for more sophisticated methods. Rule-based methods are utilized when input documents must be represented as classes and lists of aspects. However, this method requires the creation of rules, which is a time-consuming task. The reliance on manually crafted rules makes it less efficient compared to the other methods discussed earlier in this subsection [5, 12]. The semantic graph-based model primarily extracts semantic information by assigning weights to the nodes and edges within sentences. As a result, it performs effectively in most cases but depends on having a semantic representation of the text [12].
Abstractive summarisation has greatly benefited from the use of transformer-based pre-trained language models like T5 (text-to-text transfer transformer) [13, 15] and BART [7, 8, 13]. These models have developed rich linguistic and contextual representations by extensive pre-training on massive text data corpora, which enables them to produce fluent, coherent and contextually appropriate summaries with little task-specific fine-tuning. These models can be trained for a variety of tasks, such as summarising, by pre-training them to learn a broad range of language patterns, syntax and semantic understanding. While transformer models like T5 and BART have set new benchmarks in abstractive summarisation, they are computationally expensive and require significant resources for training. Despite this, the ability to process long sequences in parallel and capture complex relationships between words and phrases in a document has made transformer-based models the leading architecture for modern NLP applications, including abstractive summarisation.
2.3 Hybrid model for summarisation
A modular pipeline approach is one in which multiple models or components are chained together, each responsible for a specific task within the overall process. This concept is gaining attention in NLP due to the increasing availability of specialized models that perform well on specific subtasks. For example, LangChain [20] enables the integration of multiple models and techniques within a pipeline, facilitating both extractive and abstractive summarisation workflows. According to recent research, combining multiple models – such as using an extractive summarizer to select important sentences followed by an abstractive model to rephrase them – can reduce hallucination and improve factual consistency [19]. LangChain's flexibility in chaining different models and allowing custom steps offers opportunities to experiment with various model architectures. For instance, an extractive summarizer can serve as a filter to identify key parts of a text, after which a transformer-based abstractive model generates a more refined summary. Furthermore, pipelines are more adaptive to context-specific requirements since they may be customised to domains [33]. Despite the promise, hybrid models have not yet achieved full potential in text summarisation. For example [34], introduced pointer-generator networks that integrate abstractive and extractive summarisation methods. With the help of an RNN-based encoder-decoder architecture, the model may generate new words (abstractive) and choose sentences (extractive) to create more fluid summaries. The pointer method used by pointer-generator networks enable the model to “point” to words in the input text so that it can directly copy significant words or phrases into the summary, enhancing the quality of the summary. In Reference [35], extractive summarisation and abstractive summarisation are combined by applying clustering and NLP to reduce redundancy in the generated summary. In the first step, Term Frequency-Inverse Document Frequency is used for feature extraction; K-means clustering is then used to group similar sentences. In the final step, selected sentences are then fed into the BART model to generate the final abstractive summary. However, summary generated by this approach may still contain redundant or less relevant information if the clustering or similarity measures are not correctly aligned with the summary objectives. Similarly, in Reference [18] extractive summarization and abstractive summarisation are combined to generate final summarisation. In the extractive phase, sentence similarity matrix and sentence differentiation are used to identify the most important sentences from the input, while in abstractive phase, beam search algorithm is used to rewrite the extracted sentences. In Reference [36], a hybrid ATS approach is developed by combining a recurrent neural network and a sequence-to-sequence attentional model for extraction and abstraction. This approach is restricted to only two layers of RNN model. In Reference [37], a hybrid ATS method is proposed based on deep learning and a rapid self-attention mechanism. This approach is focused only on Chinese text summarisation. Similarly, in Ref. [38] an ensemble-based framework tailored for Turkish legal document summarisation is presented. This framework integrates four transformer models, LED, Long-T5, BART-Large and GPT-3.5 Turbo, where these models leverage both extractive precision and abstractive fluency to generate the final summary. In Reference [39], a hybrid model is developed only for summarising Amharic texts. This approach combines statistical and semantic features for extractive ATS and then combines the extractive method with standard abstractive ATS methods like BART.
Despite hybrid ATS not being very new, it should be noted that, as reported by the works on hybrid ATS in literature, most of the approaches only achieved mediocre accuracy.
2.4 Data pre-processing for automatic text summarisation
Although the overall process of ATS depends on various factors, such as the context and domain of the summarisation problem, two steps are inevitable for any summarisation process and these are data pre-processing and summarisation methods [1, 2, 5, 40]. We have discussed about summarisation methods in section 2.1 – 2.3. In this section, we briefly focus on typical methods applied for data pre-processing in ATS. Pre-processing is the initial step in text summarisation, where unstructured data are transformed into structured data based on the requirements for summarisation. Several techniques are used to extract the most significant information from the source text and provide a summary, such as (1) text cleaning involves removal of extra characters, symbols and punctuation to lessen noise and raise the precision of later processing methods [2, 5]; (2) stopword removal aims to eliminate irrelevant words (e.g. conjunctions, substitute words and pointers) that do not carry distinctive information [5, 40]; (3) stemming is used to eliminating prefixes and suffixes from words [2, 5, 12] (4) tokenising is used to divide sentences, paragraphs or documents, into certain to-kens/parts [2, 40]. In our approach, we have applied most of these pre-processing techniques as discussed in Section 3.1 and in Section 4.
3. Design and implementation of the framework
In this section, we discuss the design and implementation of our ATS framework. We follow a structured process to implement our framework. Figure 2 shows a very high-level view of this structured process, which integrates multiple stages, starting from data input to model evaluation and deployment. It begins with the dataset Input, where the raw data, such as text documents, are ingested for processing. The data flow into the data pre-processing step, where it is cleaned, tokenized and split into manageable chunks to ensure compatibility with downstream models. Following this, the process enters into modular pipeline step, which connects the pre-processing step with the model inference process, ensuring a smooth flow of data. Once the summarisation model generates an Output Summary, the pipeline assesses the output through an evaluation mechanism. At this stage, a decision point asks whether a reference summary exists for comparison. If a reference summary is available, ROUGE and BERTScore evaluations are performed. ROUGE [25] is a common automated metric for assessing summarisation models, which compares the generated summary with the ground truth. On the other hand, BERTScore measures semantic similarity of the generated summary and the reference summary [26]. In the absence of a reference summary, the pipeline offers human evaluation, in which professionals evaluate the summary's relevance, coherence and quality by hand. Depending on the evaluation results, the summary or model might require fine-tuning or further adjustment.
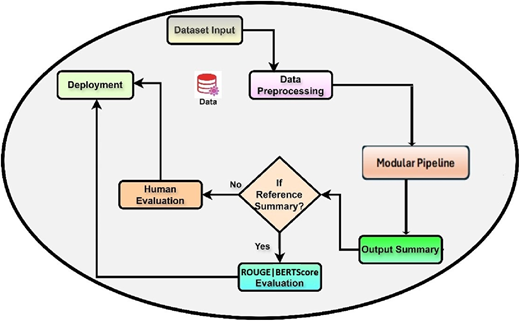
Process followed to implement modular pipeline for automatic text summarisation (high-level view)
Process followed to implement modular pipeline for automatic text summarisation (high-level view)
Once the generated summaries pass the evaluation criteria, the process concludes with deployment, where the summarisation model is integrated into production environments such as web applications. Overall, the figure outlines an end-to-end structured workflow for text summarisation, combining data pre-processing, model selection and evaluation for robust and efficient deployment in real-world applications.
In the rest of this section, we discuss the implementation of the modular pipeline and deployment of the modular pipeline with the help of detailed process diagrams.
3.1 Implementation of modular pipeline
Figure 3 shows the process that is followed to implement the modular pipeline of our framework. We have used several tools and libraries for the implementation of the modular pipeline. LangChain is used for modular pre-processing, as it guarantees the efficient handling of huge text data by breaking it up into digestible chunks. LangChain also supports the integration of other LLMs used in our implementation. For extractive summarisation, we have used LexRank algorithm, and for abstractive summarisation, the BART model from HuggingFace is used. The reason behind the selection of LexRank and BART for modular pipeline is explained in Section 4. We have also used ROUGE and BERTScores to assess the quality of the summaries, as these metrics provide numerical assessment of summary correctness in terms of the standard metrics (e.g. precision, recall and F1-score) by comparing the generated and reference summaries. Furthermore, WordCloud and Matplotlib are used for evaluating and displaying the generated summaries.
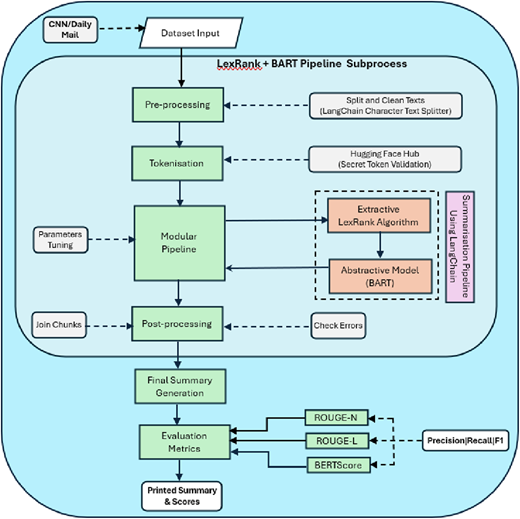
Step 1 - Dataset Setup:
We used the pre-existing CNN/Daily Mail dataset in our implementation as this is the most widely used dataset for summarisation [4, 7, 12]. Approximately 300,000 news stories are included in this dataset, which is frequently used to assess ATS methods. Each story is accompanied by a human-written summary known as “highlights.” Although the articles cover a wide range of subjects, they mostly concentrate on current affairs, and the highlights provide succinct, citation-based summaries that emphasise the articles' key ideas.
Step 2 – Pre-processing:
The pre-processing entails use of LangChain's built-in text splitters to divide long texts into digestible sections. This guarantees context continuity while keeping the input text inside the model's token bounds. We used LangChain's functions to allow smooth transitions between sections by defining a chunk size of 7,000 characters with a 250-character overlap between consecutive chunks. Newline characters (“\n”) and spaces are used as separators to support a variety of text formats. Large chunk size and overlapping was chosen to ensure preservation of context [41, 42]. Pre-processing improves performance in both extractive and abstractive summarisation tasks, simplifies text handling and optimises input for summarisation pipelines, all of which lead to improved results in subsequent tasks.
Step 3: Tokenisation:
By employing an application programming interface (API) token for authentication, safe access to external resources such as Hugging Face Hub is guaranteed. In order to integrate pre-trained models, like BART, for summarisation tasks, this procedure verifies credentials. Through authentication, users can download models and manage settings with efficiency, protect their privacy and stop unwanted access. Tokens should be kept private to safeguard sensitive operations.
Step 4: Modular pipeline implementation:
As mentioned before, the modular pipeline combines extractive and abstractive summarisation. Using graph-based ranking, LexRank first selects important sentences for extractive summarisation. For a more polished, coherent synopsis, the extracted sentences are subsequently fed into LangChain's BART-based abstractive model. The BART model creates summaries with parameters like beam search, maximum length and length penalty for balance using a Hugging Face API. By combining both techniques, the pipeline guarantees high-quality summaries by rephrasing important elements for readability (BART) and capturing them (LexRank). Both shallow and deep summarisation techniques are used in this two-step hybrid approach to increase flexibility and performance.
Step 5: Evaluation using ROUGE and BERTScore metrics:
The key evaluation metrics used for this task are ROUGE and BERTScore. ROUGE compares the overlap between model-generated summaries and human-written summaries. BERTScore computes the similarity of generated and reference summaries as a sum of cosine similarities between their tokens' embeddings. We have selected ROUGE and BERTScore as evaluation metrics, as this is reported as the most widely used evaluation metric for text summarisation [1, 2, 4, 10].
ROUGE Metric relies on n-gram matching, where the more overlapping words or phrases, the better the alignment. We have used three variants of ROUGE metric which are ROUGE-1, ROUGE-2 and ROUGE-L as defined below:
ROUGE-1: Overlapping unigrams (individual words);
ROUGE-2: Overlapping bigrams (pairs of words) and
ROUGE-L: Based on the length of the longest common subsequence.
For each of these ROUGE metrics, we have calculated recall, precision and F1 score using the formulas as shown below,
For a given a reference sentence and a generated sentence , recall, precision and F1 score are calculated using the formulas shown below. In the formulas below, represents inner product.
3.2 Deployment of modular pipeline using StreamLit
We have used StreamLit framework to create a dashboard that allows users to interact with the modular pipeline. Figure 4 presents the extended process diagram that shows the integration of the modular pipeline with SteramLit framework.
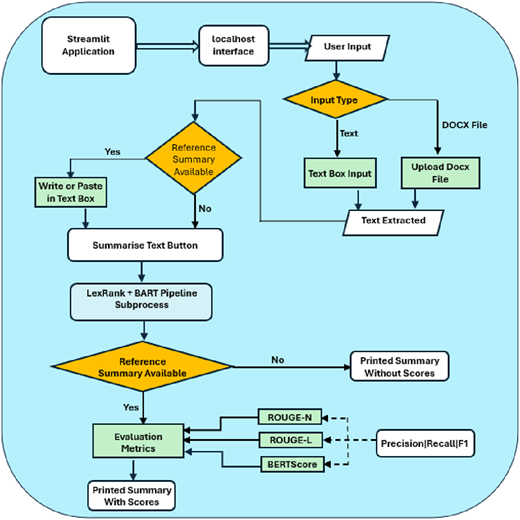
Process followed to deploy modular pipeline for automatic text summarisation as application
Process followed to deploy modular pipeline for automatic text summarisation as application
As shown in Figure 4, the user is first prompted to select whether to enter text or a DOCX file. Text is extracted if a DOCX file is selected; if not, text is entered directly into the textbox. The application asks if a reference summary is available after identifying the input type. If the user already has a reference summary, then they can paste it into the box supplied. Once input text and reference summary are provided, the text summarisation is carried out as described in Section 3.1.
The system combines findings and verifies mistakes through post-processing after summarisation. If a reference summary is given, the process calculates precision, recall and F1 scores for different evaluation metrics, such as ROUGE-1, ROUGE-2 and ROUGE-L. The process is concluded with the display of the final report, with or without scores as appropriate.
4. Testing and evaluation of our framework
In order to test and evaluate our framework we have examined the performance of various abstractive and extractive algorithms separately on a given dataset (CNN/DM). With the ROUGE and BERTScore serving as the assessment metric, the emphasis is on contrasting models such as TextRank and LexRank for extractive summarisation and BART and T5 for abstractive summarisation. We have selected these four models, as these models are very widely studied in literature for text summarisation [7, 8, 15, 27, 43].
Table 1 shows the configuration for extractive models that we applied for our experiments. As shown in the table, we have chosen en_core_web_sm as our tokeniser as this lightweight English language processing model is optimised for CPU usage. We have not set any threshold for sentence ranking so that all the ranked sentences are included in the summary. The rest of the settings are self-explanatory.
Hyper parameter settings for extractive models
| Model | Text cleaning | Stopwords | Tokeniser | Sentence rank threshold |
|---|---|---|---|---|
| LexRank |
| English | en_core_web_sm | None |
| TextRank |
| English | en_core_web_sm | None |
| Model | Text cleaning | Stopwords | Tokeniser | Sentence rank threshold |
|---|---|---|---|---|
| LexRank |
| English | en_core_web_sm | None |
| TextRank |
| English | en_core_web_sm | None |
Table 2 shows the configuration for abstractive models that we applied for our experiments. As shown in the table, apart from the output token size, for other parameters (i.e. max input token, beam size and length penalty), we used empirically default commonly used values as reported by References. [44, 45]. Max output token is set as 200 to allow for richer summaries as suggested in Reference [46].
Hyper parameter settings for abstractive models
| Model | Max input token | Max output token | Beam size | Length penalty |
|---|---|---|---|---|
| BART | 1,024 | 200 | 5 | 1 |
| T5 | 1,024 | 200 | 5 | 1 |
| Model | Max input token | Max output token | Beam size | Length penalty |
|---|---|---|---|---|
| BART | 1,024 | 200 | 5 | 1 |
| T5 | 1,024 | 200 | 5 | 1 |
Table 3, shows the precision, recall and F1 score for each ROUGE metric for each model. Table 4 shows the precision, recall and F1 for BERTScore. Figure 5 shows F1 score for each ROUGE metric for each model as bar charts. It should be noted that our implementation also used word clouds to show the terms that appear most frequently in the summaries that are produced, giving information on the main ideas that each model captures. We have not included any image of word clouds in this paper for brevity.
ROUGE metric scores for individual abstractive and extractive text summarisation models
| ROUGE score → | ROUGE-1 | ROUGE-2 | ROUGE-L | ||
|---|---|---|---|---|---|
| Abstractive | BART [14] | Precision | 0.5588 | 0.3939 | 0.5000 |
| Recall | 0.5135 | 0.3611 | 0.4595 | ||
| F1 | 0.5352 | 0.3768 | 0.4789 | ||
| T5 [16] | Precision | 0.2353 | 0.0303 | 0.1471 | |
| Recall | 0.1951 | 0.0250 | 0.1220 | ||
| F1 | 0.2133 | 0.0274 | 0.1333 | ||
| Extractive | TextRank [6] | Precision | 0.1619 | 0.0673 | 0.0952 |
| Recall | 0.5000 | 0.2121 | 0.2941 | ||
| F1 | 0.2446 | 0.1022 | 0.1439 | ||
| LexRank [21] | Precision | 0.1022 | 0.1125 | 0.1605 | |
| Recall | 0.5000 | 0.2727 | 0.3824 | ||
| F1 | 0.2957 | 0.1593 | 0.2261 | ||
| ROUGE score → | ROUGE-1 | ROUGE-2 | ROUGE-L | ||
|---|---|---|---|---|---|
| Abstractive | BART [14] | Precision | 0.5588 | 0.3939 | 0.5000 |
| Recall | 0.5135 | 0.3611 | 0.4595 | ||
| F1 | 0.5352 | 0.3768 | 0.4789 | ||
| T5 [16] | Precision | 0.2353 | 0.0303 | 0.1471 | |
| Recall | 0.1951 | 0.0250 | 0.1220 | ||
| F1 | 0.2133 | 0.0274 | 0.1333 | ||
| Extractive | TextRank [6] | Precision | 0.1619 | 0.0673 | 0.0952 |
| Recall | 0.5000 | 0.2121 | 0.2941 | ||
| F1 | 0.2446 | 0.1022 | 0.1439 | ||
| LexRank [21] | Precision | 0.1022 | 0.1125 | 0.1605 | |
| Recall | 0.5000 | 0.2727 | 0.3824 | ||
| F1 | 0.2957 | 0.1593 | 0.2261 | ||
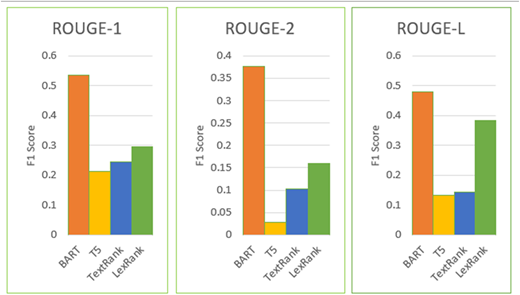
Comparison of ROUGE metric scores for individual abstractive and extractive text summarisation models
Comparison of ROUGE metric scores for individual abstractive and extractive text summarisation models
As shown in Tables 3 and 4 and Figure 5, BART performs better than other models on every metric. It achieves the highest F1 score for ROUGE-1 (0.5352) and for BERTScore (0.7179), demonstrating good overall performance in identifying important words and phrases from reference summaries. A difficult component of summarisation, the efficient modelling of bi-gram sequences is demonstrated by F1 score (0.3768) for ROUGE-2. BART's F1 score (0.4789) for ROUGE-L also demonstrates that it can generate summaries that are in good agreement with the references' sequence structure. These results validate the excellent abstractive summarisation ability of BART.
Tables 3 and 4 and Figure 5 also show that the graph-based extractive summarisation algorithm LexRank does well, particularly when contrasted with other extractive techniques like TextRank. It routinely outperforms TextRank in terms of F1 Score for ROUGE-1 (0.2957), for ROUGE-L (0.2261) and for BERTScore (0.6070). Additionally, LexRank appears to capture meaningful bi-gram relations more effectively than TextRank, as indicated by its F1 score (0.1593) for ROUGE-2. Although it performs worse than BART in abstractive tasks, LexRank is a powerful extractive summariser that is useful in situations where a purely extractive method is needed.
After evaluating the performance of each model, they are combined into a modular pipeline. More specifically we have combined the best performing abstractive model (BART) and the best performing extractive model (LexRank). This setup guarantees that only the best methods are used to enhance summarisation results. Table 5 shows the parameter settings (in addition to the settings shown in Tables 1 and 2 for LexRank and BART, respectively) for the pipeline that we applied for our experiments. As shown in the table, LangChain splits the initial input into chunks of 7,000 characters with a 250-character overlap between consecutive chunks. lexrank_sentences specifies the preferable number of sentences in the summary generated by LexRank, min_length and max_length signifies the preferred minimum and maximum length of the summary (in terms of characters) generated by BART.
Parameter settings for pipeline
| LangChain | LexRank | BART |
|---|---|---|
| chunk_size = 7,000 | lexrank_sentences = 15 | min_length = 20 max_length = 300 |
| chunk_overlap = 250 |
| LangChain | LexRank | BART |
|---|---|---|
| chunk_size = 7,000 | lexrank_sentences = 15 | min_length = 20 max_length = 300 |
| chunk_overlap = 250 |
In addition to CNN/DM dataset, for evaluation of our framework we have used Newsroom [23] and XSum [24] datasets. Both Newsroom and XSum are large datasets, widely used for training and evaluating summarisation systems [4, 9, 10]. Table 6 shows the precision, recall and F1 score for each ROUGE metric for the modular pipeline. Table 7 shows the precision, recall and F1 score for BERTScore. Figure 6 shows F1 score for each ROUGE metric for BART, LexRank and Hybrid (BART + LexRank) model as bar charts for CNN/Daily Mail dataset (as we evaluated individual models using CNN/Daily Mail dataset).
ROUGE metric scores for our modular pipeline (LexRank + BART)
| Data set | ROUGE score | Precision | Recall | F1 |
|---|---|---|---|---|
| CNN/DM | ROUGE-1 | 0.7188 | 0.6571 | 0.6866 |
| ROUGE-2 | 0.4839 | 0.4412 | 0.4615 | |
| ROUGE-L | 0.5000 | 0.4571 | 0.4776 | |
| Newsroom | ROUGE-1 | 0.7083 | 0.3820 | 0.4964 |
| ROUGE-2 | 0.5745 | 0.3068 | 0.4000 | |
| ROUGE-L | 0.6667 | 0.3596 | 0.4672 | |
| XSum | ROUGE-1 | 0.4250 | 0.6071 | 0.5000 |
| ROUGE-2 | 0.2658 | 0.3818 | 0.3134 | |
| ROUGE-L | 0.2500 | 0.3571 | 0.2941 |
| Data set | ROUGE score | Precision | Recall | F1 |
|---|---|---|---|---|
| CNN/DM | ROUGE-1 | 0.7188 | 0.6571 | 0.6866 |
| ROUGE-2 | 0.4839 | 0.4412 | 0.4615 | |
| ROUGE-L | 0.5000 | 0.4571 | 0.4776 | |
| Newsroom | ROUGE-1 | 0.7083 | 0.3820 | 0.4964 |
| ROUGE-2 | 0.5745 | 0.3068 | 0.4000 | |
| ROUGE-L | 0.6667 | 0.3596 | 0.4672 | |
| XSum | ROUGE-1 | 0.4250 | 0.6071 | 0.5000 |
| ROUGE-2 | 0.2658 | 0.3818 | 0.3134 | |
| ROUGE-L | 0.2500 | 0.3571 | 0.2941 |
BERTScores for our modular pipeline (LexRank + BART)
| Data set | Precision | Recall | F1 |
|---|---|---|---|
| CNN/DM | 0.7541 | 0.7747 | 0.7643 |
| Newsroom | 0.6723 | 0.8116 | 0.7354 |
| XSum | 0.6616 | 0.6222 | 0.6413 |
| Data set | Precision | Recall | F1 |
|---|---|---|---|
| CNN/DM | 0.7541 | 0.7747 | 0.7643 |
| Newsroom | 0.6723 | 0.8116 | 0.7354 |
| XSum | 0.6616 | 0.6222 | 0.6413 |
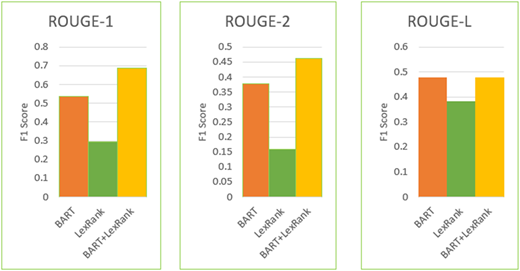
Comparison of ROUGE metric scores of BART, LexRank and our modular pipeline (LexRank + BART) for CNN/daily mail dataset
Comparison of ROUGE metric scores of BART, LexRank and our modular pipeline (LexRank + BART) for CNN/daily mail dataset
Tables 6 and 7 and Figure 6 demonstrate that, as compared to the performance of independent models (Tables 3 and 4 and Figure 5), text summarisation performance, for CNN/DM dataset, significantly improves when LexRank and BART are combined using LangChain. Superior ROUGE scores are obtained by the hybrid model for most of the metrics. For example, F1 score for ROUGE-1 achieves 68.66%, surpassing the previous peak score of 53.52% achieved by BART alone. BART's previous best F1 score for ROUGE-2 of 37.68% has been surpassed by the pipeline's F1 score, which shows the retention of meaningful bi-grams in the extractions. Additionally, F1 score for ROUGE-L for the hybrid model is very close to BART's prior maximum of 47.89%. Similarly, BERTScore for the pipeline (for CNN/DM dataset) has improved compared to BERTScore for individual models. These improvements demonstrate the hybrid model's capacity to extract important information and generate logical, well-organised summaries.
We have also compared the ROUGE score of our hybrid model with the other existing models that have used CNN/Daily Mail dataset for text summarisation. As reported in the exhaustive survey on text summarisation in Reference [4], several other models have conducted evaluation based on CNN/Daily Mail data set. Among these models, we have selected three best performing models, which are (1) extractive summarisation model is DiffuSum [47], (2) abstractive model is SliSum [48] and (3) hybrid model is GSum [49]. The F1 score for each ROUGE metric for these models is reported in Reference [4], and F1 score of our hybrid model is shown in Table 8. Figure 7 shows the F1 score for each ROUGE metric for these models and our hybrid model as bar charts.
ROUGE metric scores for existing models (DiffuSum, SliSum and GSum) and our modular pipeline (LexRank + BART) for CNN/daily mail dataset
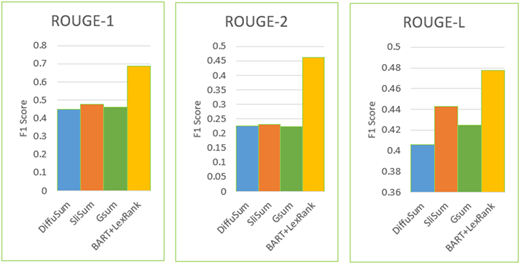
Comparison of ROUGE metric scores for existing models (DiffuSum, SliSum and GSum) and our modular pipeline (LexRank + BART)
Comparison of ROUGE metric scores for existing models (DiffuSum, SliSum and GSum) and our modular pipeline (LexRank + BART)
As shown in Table 8 and Figure 7, our hybrid model has outperformed the other models for each ROUGE metric. The use of LangChain to integrate LexRank with BART and complimentary advantages of extractive and abstractive approaches account for the pipeline's outstanding performance. Through our experiments, we made two observations that enabled our pipeline to achieve the performance reported in this section. Firstly, the selection of chunk size for LangChain. In the first place, LangChain splits the input text into smaller chunks, and the selection of the chunk size (as stated in Table 5) played a crucial role in the overall performance. In our initial experiments, a smaller chuck size (e.g. less than 5,000 characters) did not produce good results, and better results were only achieved with larger chunk size (e.g. 7,000 characters). Secondly, the selection of the size of summary is generated by LexRank (as stated as lexrank_sentence is Table 5). The election of a smaller size (e.g. less than 12) or larger value (e.g. greater than 15) did not produce good results, and better results were only achieved with summary size of 12 to 15 sentences. This ensured that in extractive phase, LexRank makes sure that crucial sentences are accurately detected, and BART rewords these extracts into coherent summaries that are rich in context. It should be noted that error propagation from extractive phase to abstractive phase is a typical issue as reported in the literature, e.g. in References [44, 50]. Though this is not investigated in our approach, our results as compared with other approaches indicate that this error propagation could be minimal in our approach. Nevertheless, we endeavour to investigate this in future work to improve the accuracy of our approach.
5. Conclusions and future directions
The primary contribution of this study is the development and evaluation of a modular pipeline combining LexRank, an extractive summarisation technique, and BART, an advanced abstractive model, orchestrated via LangChain. The results indicate that our hybrid approach outperforms traditional single-model methods and other existing hybrid models as evidenced by significantly higher ROUGE scores across various experiments. Although our work demonstrated very good results, it should be noted that it had certain shortcomings. In our experiments, we used datasets that have short length documents (within 7,000 characters). We need to perform more experiments with long documents to evaluate the robustness of our pipeline. As mentioned in Section 4, we have not investigated error propagation from extractive phase to abstractive phase, which may have an impact on the performance of our framework. Finally, the focus of our study was restricted to general-purpose summarisation; domain-specific modifications were noted as a possible topic for further research but were not thoroughly examined in this study.
Several suggestions can direct future research and real-world applications in autonomous text summarisation, building on the findings from our work, which are listed below,
Firstly, applying the modular pipeline to domain-specific datasets, such as scientific, legal or medical texts, would offer important insights about how adaptable and effective it is in particular settings. Further improving the quality and relevance of generated summaries may involve tailoring pre-processing and summarisation methods for domain-specific terminology and data structures.
Second, adding other sophisticated evaluation metrics like MoverScore or LLM based metrics (e.g. LLM-as-a-judge) could enhance ROUGE and BERTScores and offer a more sophisticated review of semantic coherence and factual consistency. These measures may also be used to detect small enhancements in the quality of abstractive summarisation that are missed by conventional evaluation techniques. Larger-scale human inspection, especially for domain-specific summaries, could confirm the pipeline's functionality and point out areas that need improvement.
Third, further research in the domain of multilingual capabilities exploration is crucial. Adding multilingual functionality to the pipeline will greatly boost its usefulness in international applications. Using pre-trained multilingual models and modifying pre/post-processing procedures to accommodate various linguistic structures would be necessary to achieve this.
