To address the limitations of traditional failure mode and effects analysis (FMEA) methods in elevator fault analysis, including heavy reliance on human experience, limited use of large scale heterogeneous text data, static analysis results and insufficient interpretability, this study aims to develop an intelligent FMEA method for the elevator domain.
An elevator FMEA method based on retrieval augmented generation (RAG) is proposed. An external knowledge base is constructed by integrating a knowledge graph (KG) with a vector database. During retrieval, a multi-route retrieval strategy is adopted to obtain candidate documents. A reranking model named CapsGCN-Rank based on a graph convolutional capsule neural network is designed to perform fine-grained filtering and reranking of candidate documents. The reranked documents are then combined with a large language model to generate structured fault analysis results.
Experimental results show that the proposed method outperforms several baseline methods in context precision, context recall, as well as the relevance and correctness of generated answers. The method effectively improves the accuracy and completeness of elevator FMEA.
The proposed approach introduces structured semantics from the KG, a multi-route retrieval strategy and dynamic routing of capsule neural networks into the RAG framework. It enables fine-grained document reranking and interpretable fault analysis for the elevator domain, providing an effective solution for FMEA in complex industrial scenarios.
1. Introduction
Failure mode and effects analysis (FMEA) is a typical risk assessment technique that systematically identifies potential failure modes and evaluates them according to severity and likelihood, thereby supporting maintenance decision-making (Schmitt and Pfeifer, 2015). At present, FMEA has been widely applied in many fields, including mechanical manufacturing (Ervural and Ayaz, 2023), marine engineering (Ceylan and Memiş, 2025) and aerospace engineering (Filz et al., 2021).
However, traditional FMEA methods face many challenges in modern elevator maintenance scenarios. In the evaluation process, these methods assign equal weights to failure occurrence probability, detection probability and severity, while such a balance is difficult to achieve in real operating conditions (Filz et al., 2021). Meanwhile, maintenance records are often large in volume and poorly structured. Difference in personal experience among maintenance personnel results in inconsistent recording standards, which further reduce data completeness and consistency and hinders systematic assessment (Lu et al., 2025). Moreover, traditional FMEA results are typically presented as static tables, lacking reasoning capability and association analysis, which limits the identification of key patterns across failure modes and hinders the provision of clear guidance (Bahr et al., 2025).
In elevator scenarios, existing studies have shown that related data often exhibit imbalanced distributions and high complexity. Such data characteristics limit the performance of intelligent fault analysis (Xiao et al., 2024). Although some deep learning-based fault diagnosis models alleviate these issues through methods such as feature extraction (Wang et al., 2024) and data augmentation (Jiawei et al., 2025), their analytical performance still relies heavily on domain knowledge, with limitations in knowledge integration and result interpretation.
In recent years, the emergence of large language models (LLMs) has provided new directions for FMEA. LLMs show strong capabilities in semantic understanding and text summarization, which enables them to extract key information from large scale and structurally complex industrial documents. At the same time, the introduction of retrieval augmented generation (RAG) has further improved the accuracy of LLM-based FMEA. RAG stores knowledge in external databases and performs retrieval and generation during inference, thereby reducing hallucination in LLMs and improving results interpretability (Wu et al., 2025). However, existing RAG methods still face difficulties in identifying highly relevant information. Especially in elevator scenarios, data such as failure modes, fault locations and maintenance texts exhibit clear, structured semantic relationships. In practice, these data are often distributed across heterogeneous and fragmented documents, which makes it difficult for retrieval modules to accurately identify core information that is truly related to specific failure modes. Knowledge graph (KG) can organize this dispersed information into a unified semantic network in the form of triples (Lu et al., 2024). With the support of graph database query languages, specific entities and their contextual relationships can be precisely retrieved, providing comprehensive and high-quality knowledge support for the reasoning module (Wan et al., 2025). By adopting a knowledge graph as the external database, RAG can retrieve information that is more closely aligned with the query intent and perform deeper reasoning based on structured knowledge during generation, thereby producing more complete, reliable and interpretable results for FMEA.
Therefore, we propose an elevator FMEA method based on RAG. The main contributions are as follows:
A multi-route retrieval strategy that integrates KG and vector database is proposed. By combining keyword retrieval based on the KG with similarity retrieval based on the vector database, the relevance and coverage of candidate documents are improved.
A reranking model named CapsGCN-Rank based on a graph convolutional capsule neural network is developed. Multi-scale document capsule representations are constructed by integrating graph convolutional networks with a query-aware attention mechanism to achieve effective alignment between document features and user queries.
Dynamic routing mechanism is introduced to perform fine-grained filtering and reranking of candidate documents, which further improves the contextual quality during the RAG stage.
2. Related work
2.1 Traditional FMEA
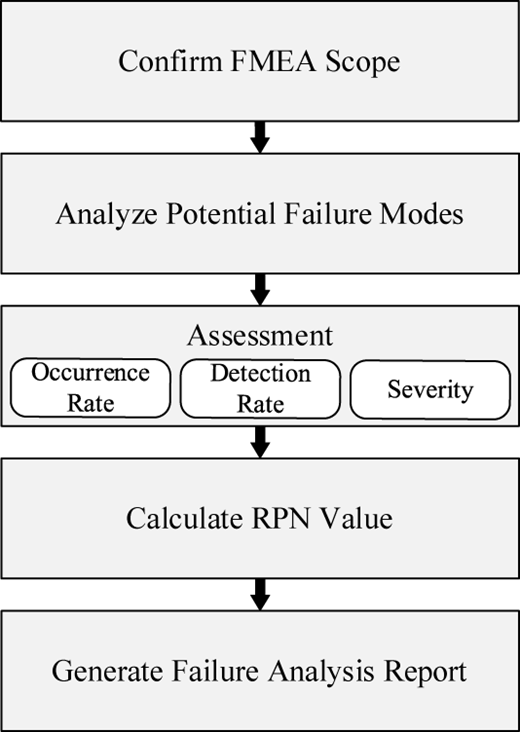
The basic procedure of the traditional FMEA is illustrated in Figure 1. First, the scope of FMEA is defined through system analysis, and the system architecture and functions are identified. Second, potential failure modes, failure causes and their effects are analyzed. Then, different failure modes are evaluated from the perspectives of failure occurrence, detection probability and severity. Finally, the risk priority number (RPN) is calculated, and failure modes are ranked according to the RPN to formulate maintenance actions for high-risk failures. For example, Suwankanit (2019) used the FMEA method to analyze the installation process of an elevator, identifying failure modes, their effects and corresponding failure causes during installation.
2.2 Retrieval augmented generation-based FMEA
Traditional FMEA methods are difficult to conduct efficiently in modern industrial systems that involve large volumes of data. To address this issue, many studies have attempted to introduce LLMs into FMEA and have proposed RAG-based FMEA methods. For example, Alenjareghi et al. (2026) proposed an LLM-enhanced FMEA method and applied it to safety risk analysis in human–robot collaboration scenarios. Bahr et al. (2025) further introduced a KG into the RAG framework, where structured knowledge was used to reduce hallucination in LLMs and thus improve the analytical performance of FMEA.
Although above methods improve the intelligence level of FMEA to some extent, existing studies mainly focus on introducing knowledge at the retrieval stage and lack further filtering and reranking of candidate documents. To address this limitation, we introduced a multi-route retrieval strategy to improve the coverage completeness of candidate documents and further designed a reranking model to enhance the relevance between candidate documents and user queries.
3. Method
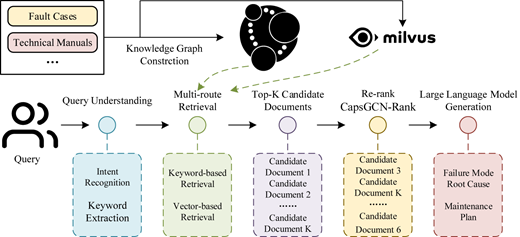
To address intelligent fault analysis in elevator systems, we propose an elevator FMEA method based on RAG (KG-CapsGCN-RAG). The overall procedure is shown in Figure 2. First, an external database is constructed by converting the collected text data into vector representations and storing them in a vector database, while a domain KG is built in parallel. Second, within the RAG module, the query is processed through keyword extraction and vector representation. A multi-route retrieval strategy is then adopted, where keyword retrieval is performed on the KG and vector similarity retrieval is conducted in the vector database to obtain candidate documents related to the query. Next, the proposed reranking model CapsGCN-Rank is applied to perform filtering and reranking of the candidate documents. Finally, the reranked documents and the query are jointly fed into an LLM, which performs contextual reasoning and summarization to generate the final FMEA results.
3.1 Knowledge graph embedding
The text data used in this study are expressed in natural language form. Before model inference, the text corpus needs to be embedded by converting text into vector representations, so that semantic information can be captured and similarity retrieval can be performed.
The Moka massive mixed text embedding model (M3E) is trained on a large-scale Chinese sentence pair dataset with tens of millions of samples, and it provides high-quality Chinese text embeddings with strong accuracy in semantic matching and retrieval tasks. Experimental results on multiple Chinese benchmark datasets show that its Normalized Discounted Cumulative Gain at 10 (NDCG@10) scores are higher than those of most baseline models. In addition, the M3E model contains only 110M parameters, which makes it suitable for efficient deployment. In the elevator scenario, most of the processed texts are in Chinese, with only a small amount of English content. Therefore, the M3E text embedding model is selected to embed both the textual data and user queries.
3.2 Multi-route retrieval
The accuracy of candidate documents is a key factor affecting the results of elevator FMEA. Accordingly, we adopt a multi-route retrieval strategy for candidate documents acquisition by combining keyword retrieval based on the KG with similarity retrieval in the vector database. Through the joint use of these two retrieval approaches, the overall performance of the retrieval process is improved.
Keyword retrieval
In the query understanding module, the LLM is used to analyze the user query and extract key entities. The keyword retrieval formulates graph database query statements to retrieve all key entities from KG and then outputs the corresponding triples. The retrieved triples can be represented as .
Vector similarity retrieval
We evaluate the similarity between the query vector and vectors stored in the vector database using cosine similarity. The core idea is to measure the degree of similarity by computing the cosine value of the angle between two vectors in the vector space.
When a query is received, the M3E text embedding model is used to embed the query and obtain the query vector . The similarity computation between the query vector and vectors in the vector database can be expressed as
where denotes the dot product between vectors; and represent the L2 norms of and , respectively. The output represents the similarity degree between the text and the query.
Finally, based on the similarity scores, the top K most relevant vectors are returned as the output and represented as . The results of keyword retrieval and vector similarity retrieval are then integrated to obtain a set of candidate documents .
3.3 CapsGCN-rank
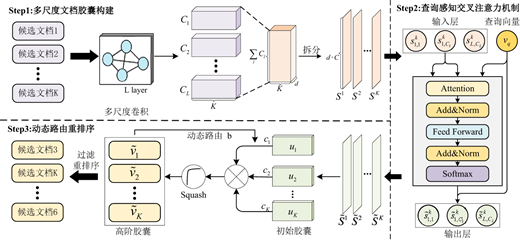
Because candidate documents obtained at the retrieval stage often exhibit weak relevance and semantic redundancy, this can significantly limit the reasoning quality of the LLM during the generation stage (Xiong et al., 2025). To improve the overall performance of KG-CapsGCN-RAG, reranking of candidate documents is essential. The objective is to further filter and rank documents obtained from multi-route retrieval, extracting more informative and query-relevant content. This study proposes a reranking model based on a graph convolutional capsule neural network (CapsGCN-Rank) to enable effective filtering and accurate reranking of candidate documents. As shown in Figure 3, the model consists of three components. First, GCN is used to construct multi-scale document capsules, where candidate documents are taken as input to produce multi-channel semantic representations. Second, a query-aware cross-attention mechanism is introduced to fuse features across different channels by incorporating the query vector, thereby generating primary document capsules. Finally, the dynamic routing reranking is applied to iteratively construct higher-level capsules, and the vector length of the final capsule is used as the similarity criterion between documents and the query, enabling candidate document filtering and reranking.
3.3.1 Multi-scale document capsule construction
In the RAG process, the user query is represented as , and the K candidate documents are denoted as . Their embeddings are given by , with dimensionality . In this section, filtering and reranking are performed based on the similarity between the user query and the candidate documents.
Since relations may exist among candidates, documents and GCN can effectively capture such internal features by incorporating semantic graph structures. GCN is applied to process the document embeddings to obtain initial document features:
where is a learnable weight matrix and denotes the number of channels in the lth layer. is the adjacency matrix, denotes the degree matrix corresponding to the adjacency matrix and is the identity matrix. represents the embedding of candidate documents at the lth GCN layer, with the initial value set to .
To more effectively capture interactions among documents, an adaptive adjacency matrix construction method is further introduced, where the adjacency matrix is dynamically built based on document embeddings:
where t is a temperature coefficient used to control the smoothness of the similarity distribution. This adjacency matrix construction method enables the graph structure to be dynamically learned according to semantic similarity among documents, thereby enhancing the capability of GCN to model semantic relationships.
After obtaining the outputs of each GCN layer, they are reorganized into multi-scale document feature representations. For the lth GCN layer, the output is denoted as , where each channel corresponding to a d dimensional document vector. To construct the initial document capsule, the output of each layer is split by channel into individual channel vectors:
After integrating channel features from all layers, a total of channels are obtained.
3.3.2 Query aware cross-attention mechanism
In GCN, vectors from different layers and different channels describe document features at multiple scales and in different representation spaces. However, the importance of these vectors is not uniform. Some vectors may contain irrelevant semantics or noise, which can affect the performance of subsequent dynamic routing, and moreover, they are not compared with the query vector in terms of similarity.
To address this issue, a query-aware cross-attention mechanism is introduced to apply weighted scaling to each channel vector. This mechanism allows the model to highlight key information related to the query semantics while suppressing redundant components. For the kth candidate document, vectors from all layers and channels are concatenated to form a complete document embedding representation:
To distinguish the importance of different channels and their correlation with the query vector, we perform computation using a cross-attention mechanism. Specifically, for the kth candidate document, the query vector and the key vector are constructed as
where and are learnable weight matrices. is only related to the query and remains the same for all candidate documents. is determined by the specific candidate document.
Then, based on the query vector and the key vector, the attention weights are computed as follows:
the computed contains attention weights of the channels. According to these attention weights, each channel vector is scaled as
After concatenating all attention results, a complete document embedding is obtained , and all candidate documents can be represented as . Each element has dimensionality .
3.3.3 Dynamic routing Re-ranking
Subsequently, the document embeddings are further updated by incorporating the dynamic routing mechanism. First, the document embeddings are expanded to generate an initial document capsule set , where and denote the capsule dimension. Then, prediction vectors are computed through an affine transformation:
where represents the prediction vector of the kth document capsule with respect to the jth higher-level capsule. is a learnable weight matrix. After aggregating all prediction vectors, the higher-level capsule can be obtained as
where is an activation function. denotes the coupling coefficient, which is used to describe the contribution of a document capsule to a higher-level capsule. For each document capsule , the sum of its coupling coefficients with all higher-level capsules are initialized to 1. The coupling coefficient is computed through the dynamic routing mechanism as follows:
where the initial value of is set to 0 and is dynamically updated during the routing iterations according to the computation results of the higher-level capsules. The update process is realized through the accumulation of .
Through this dynamic routing mechanism, document capsules and higher-level capsules are able to maintain feature consistency during the iterative process. This enables the model to strengthen document capsules with higher contribution degrees while suppressing noise, thereby generating higher-level document semantic representations for ranking.
Finally, the loss function is designed to minimize the cosine distance between the query vector and the higher-level capsule, so as to constrain the semantic direction of the higher-level capsule to be consistent with the query:
3.4 Reranking
In capsule neural networks, the length of a higher-level capsule vector is usually used to represent the probability strength of the features expressed by the capsule. In reranking tasks, the direction of the higher-level capsule vector is more capable of reflecting the relevance between candidate documents and the query. Therefore, the importance of candidate documents with respect to the query is determined according to the direction of the higher-level capsule, and reranking is performed accordingly.
For each candidate document , a higher-level capsule vector is computed. Based on the cosine similarity defined in the loss function, the similarity between and the query vector is computed as follows:
A higher score indicates a stronger relevance between the document and the query. Subsequently, candidate documents are filtered and reranked according to a threshold, and the final document set is obtained as
where denotes the final document set and represents the threshold. Documents with scores lower than the threshold are filtered out. In the generation stage, the reranked documents are integrated with the query to jointly form the contextual input to the LLM, which performs deeper integration and outputs structured standard answers.
4. Experiments
4.1 Evaluation metrics
To evaluate the accuracy of the conclusions of elevator FMEA, the experiments adopt the RAGas framework for performance evaluation. RAGas is a framework specifically designed for evaluating the performance of RAG systems, which involves multiple metrics:
Context precision (CP): CP is used to measure the relevance of retrieved context fragments to the answers of a given question. Its formulation is expressed as follows:
where Precision@k represents the proportion of positive results among the top k retrieval results.
Context recall (CR): CR is used to measure the consistency between the retrieved context and the ground truth provided by humans. Its formulation is expressed as follows:
where GT denotes the ground truth. In this formula, the numerator represents the number of sentences in the retrieved context that are relevant to the ground truth, while the denominator represents the total number of sentences in the ground truth.
Answer relevancy (AR): AR is used to measure the degree of association between the generated answer and the user query. To compute this metric, RAGas invokes LLM to infer possible questions in reverse based on the generated answer and then calculates the average cosine similarity between all inferred questions and the user query. The core idea is that if the generated answer can respond to the user query, the inferred questions and the user query will exhibit a relatively high similarity.
Answer correctness (AC): AC is used to measure the similarity between the generated answer and the ground truth. To compute this metric, RAGas allows LLM to read both the generated answer and the ground truth simultaneously and then evaluates the degree of semantic consistency and factual consistency between them. The final AC score is obtained through weighted computation.
In this study, CP and CR are used to evaluate the candidate documents obtained from retrieval and reranking, so as to measure the relevance and coverage completeness of the candidate documents. At the same time, AR and AC are used to evaluate the conclusions of elevator FMEA obtained in the generation stage, measuring the quality of the generated answers from the perspectives of semantic consistency and factual correctness. By combining these four metrics, the overall performance of the RAG framework across retrieval and generation processes can be comprehensively evaluated.
4.2 Dataset construction
To evaluate the accuracy of FMEA, we construct a question answering evaluation dataset that conforms to the RAGas framework. For question design, the dataset covers multiple types of questions, including simple question answering and complex reasoning, so as to ensure diversity in question types. At the same time, all questions and ground truth are specifically designed based on the actual data used in RAG. To further improve data quality, all proposed questions and ground truth undergo multiple rounds of screening and are validated by domain experts to ensure their accuracy and reliability.
Finally, based on the above procedure, an evaluation dataset consisting of 100 question answering samples is constructed. Some examples are shown in Figure 4.
4.3 Experimental environment and parameter settings
In this study, m3e-base was used as the text embedding model to encode both queries and documents. Deepseek-v3.2 was selected as the baseline LLM of KG-CapsGCN-RAG to perform question understanding and answer generation. During the training of the CapsGCN-Rank reranking model, the multi-route retrieval was configured to retrieve 10 relevant documents for each query. The number of training epochs was set to 10, learning rate was set to 5e−5 and Adam was selected as the optimizer. In addition, the number of GCN layers was set to 3, with the number of channels in each layer set to 2. The number of dynamic routing iterations in the capsule neural network was set to 3. The experimental environment and the remaining parameter settings in this section are shown in Table 1.
Finally, the following RAG frameworks are selected for comparison in this study:
NaiveRAG (Gao et al., 2023): NaiveRAG is a standard baseline model of existing RAG frameworks. This method is based on vector retrieval, where the original documents are sliced and encoded to obtain similar document information.
GraphRAG (Edge et al., 2024): GraphRAG is a KG–based RAG method. It summarizes document content by constructing graph level and node level community reports and performs RAG by incorporating the community reports.
LightRAG (Guo et al., 2024): LightRAG is a KG-based RAG method. It adopts a two-level retrieval architecture that combines lower level specific entity retrieval with higher level topic retrieval, thereby improving retrieval coverage.
4.4 Results
4.4.1 Baseline Study
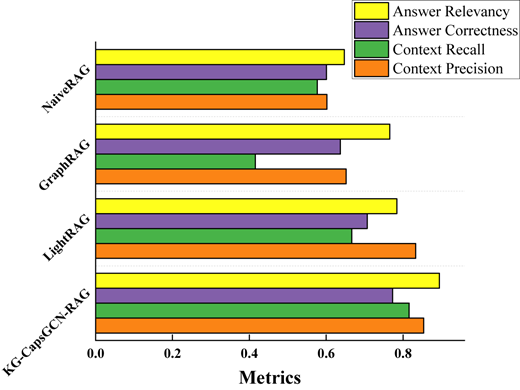
The overall experimental results are shown in Figure 5. The results indicated that, as the RAG method gradually shifts from a retrieval strategy that relies only on vector similarity to a strategy that integrates a KG, the overall performance of RAG is clearly improved. GraphRAG, LightRAG and KG-CapsGCN-RAG all introduced a KG in the retrieval stage and achieved better performance compared with NaiveRAG, which relied only on vector similarity retrieval. Furthermore, by introducing a multi-route retrieval strategy, LightRAG and KG-CapsGCN-RAG can retrieve candidate documents with broader coverage, thereby improving the overall quality of the retrieved context and enhancing the quality of the generated answers. Their overall performance was superior to that of GraphRAG, which relied on a single graph retrieval strategy. On this basis, KG-CapsGCN-RAG further introduced a reranking model. For the task of elevator FMEA, CapsGCN-Rank was designed by combining capsule neural networks with GCN, which performs fine-grained filtering and reranking of candidate documents, thereby improving question answering performance in complex engineering scenarios.
4.4.2 Ablation study
In this section, a series of ablation experiments were conducted to verify the impact of each component in the proposed method. The experiment consists of the following control groups: (1) proposed KG-CapsGCN-RAG; (2) KG-CapsGCN-RAG without keyword retrieval, denoted as w/o KG; (3) KG-CapsGCN-RAG without vector similarity retrieval, denoted as w/o Vector; (4) KG-CapsGCN-RAG without CapsGCN-Rank, denoted as w/o Rerank.
The experimental results are shown in Table 2. It can be observed that all components in KG-CapsGCN-RAG contribute positively to the improvement of RAG performance. First, when the CapsGCN-Rank was removed, the performance of RAG showed a clear decline. This result indicated that although the multi-route retrieval can provide diverse candidate documents, it inevitably included many redundant documents and low relevance information, which directly affect the generation performance of LLM. Both w/o KG and w/o Vector retained the CapsGCN-Rank, and their performance was clearly better than that of w/o Rerank, which further demonstrated that the proposed CapsGCN-Rank plays a crucial role in the overall RAG process.
Further, both w/o KG and w/o Vector rely on a single route retrieval. As a result, the candidate documents obtained by these methods show weaker coverage of relevant information compared with the multi-route retrieval strategy, leading to lower results in AC and AR than the complete method. The results of these two experiments further indicated that vector similarity-based retrieval plays a more important role than KG-based keyword retrieval, as it can match a wider range of relevant documents, while the latter can provide more accurate triple information based on the KG structure. By combining these two retrieval methods, more sufficient and precise candidate documents can be obtained.
4.4.3 LLM comparative study
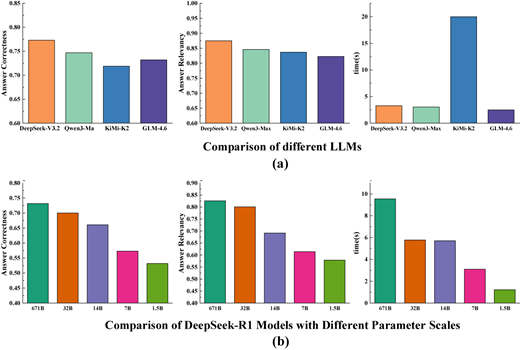
In the generation stage, the performance of the LLM used is a key factor affecting the accuracy of the final answers. A stronger model can accurately understand the question based on the prompts and effectively integrate the retrieved candidate documents. Therefore, Qwen3-Max, DeepSeek-V3.2, KiMi-K2 and GLM-4.6 were selected as baseline models for comparison. In addition, since the number of model parameters is an important indicator for evaluating LLM performance, we further investigated the impact of parameter scale on RAG performance by using different parameter versions of the same model. The objective of this experiment was to maintain RAG accuracy while adopting models with smaller parameter scales for inference, so as to reduce token consumption. In the experiments, DeepSeek-R1 was used as the baseline model, and its full version with 671B parameters, as well as versions with 32B, 14B, 7B and 0.5B parameters, was evaluated. All models were invoked through the Alibaba Cloud Bailian Application Programming Interface (API).
Figure 6 presented the comparison results of different models in AC, AR and average inference time. As shown in Figure 6(a), DeepSeek-V3.2, Qwen3-Max, KiMi-K2 and GLM-4.6 exhibited similar performance on AC and AR. These four models were full-parameter versions of their respective architectures and possessed strong capabilities in semantic understanding and text generation. With appropriate prompts and sufficient and accurate candidate documents support, the models can effectively integrate retrieved information, summarize the given text and produce accurate responses. Regarding inference time, DeepSeek-V3.2, Qwen3-Max and GLM-4.6 can complete inference within a relatively short time, whereas KiMi-K2 required a longer inference time. This was because KiMi-K2 incorporated a deep reasoning mechanism during inference. However, in the application scenario considered in this study, the task mainly focused on text understanding and summarization, and the deep reasoning capability did not lead to a clear advantage in generation performance.
Figure 6(b) shows the experimental results of DeepSeek-R1 under different parameter scales. The results indicated that, as the number of model parameters decreased, the performance on AC and AR in the generation stage exhibited a gradual decline. Although reducing the model scale led to some reduction in inference time, the improvement was limited and insufficient to compensate for the performance degradation caused by the decrease in parameter scale. These results indicated that, in elevator scenario, models with larger parameter scales can better exploit semantic understanding and produce more accurate FMEA results.
4.4.4 Visualization analysis
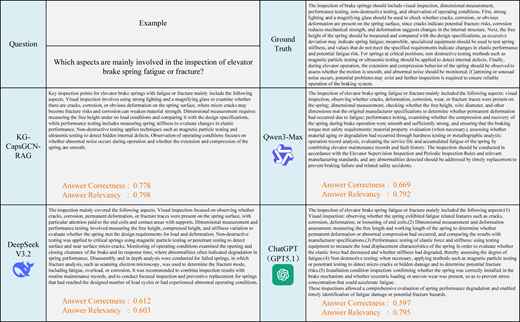
Finally, to present the performance of KG-CapsGCN-RAG in a more intuitive manner, a visualization analysis was conducted on its question answering results in practical scenarios. Taking the question “Which aspects are mainly involved in the inspection of elevator brake spring fatigue or fracture?” as an example, the proposed method was compared with commonly used general LLMs, including Qwen3-Max, DeepSeek-V3.2 and GPT5.1. The AC and AR of the answers generated by different models were calculated based on the reference answer.
As shown in Figure 7, KG-CapsGCN-RAG achieved the best performance on both metrics. Its generated answers showed advantages in content coverage, completeness and conciseness. This was mainly because the reference knowledge was processed by different methods and stored in the KG and the vector database, which enabled the retrieval stage to query relevant knowledge around the user question and provide contextual support for the generation stage.
The other three models also achieved relatively high AR values, indicating that their responses can answer the question and identify key inspection aspects such as visual inspection, dimensional measurement and performance testing. However, from the perspective of AC, the answers generated by these models still exhibited varying degrees of information omission and detail deviation compared with the ground truth. For example, the response generated by Qwen3-Max did not mention non-destructive testing. Although DeepSeek-V3.2 and GPT5.1 mentioned non-destructive testing, they did not further specify inspection techniques such as ultrasonic testing, leading to differences in key implementation details. In addition, none of the above models mentioned abnormal noise during spring operation. These differences ultimately resulted in lower AC values.
5. Conclusions
This study proposed KG-CapsGCN-RAG, an elevator FMEA method based on RAG. The overall framework of the proposed method consisted of four key steps: (1) construction of KG and vector database, (2) retrieval of candidate documents by combining a multi-route retrieval strategy, (3) filtering and ranking of candidate documents using the proposed CapsGCN-Rank reranking model and (4) generation of structured fault analysis results based on LLM.
In KG-CapsGCN-RAG, the CapsGCN-Rank reranking model constructed primary document capsules by integrating multi-scale convolution and a query aware cross-attention mechanism and evaluated document similarity through the dynamic routing mechanism. This process enabled fine-grained filtering and reranking of candidate documents. Experimental results showed that KG-CapsGCN-RAG outperformed existing RAG methods such as GraphRAG and LightRAG. In addition, the CapsGCN-Rank reranking model provided high-quality candidate documents that were highly relevant to the query, which verified the effectiveness of the proposed method for elevator FMEA tasks.