

Due to the characteristics of large inertia, large time delay and non-linearity in ship motion, the manoeuvrability of ships is an important issue related to the safety of ship navigation. The manipulation of ships significantly affects the safety of ship navigation, and its importance will gradually increase with the development of autonomous ships (ASs). Due to the complexity of inland waterways and the density of ships, collisions are common. In this work, an autonomous learning framework with deep reinforcement learning (DRL) was constructed for ASs. The state space, action space, reward function and neural network structure of DRL were designed based on the AS's manoeuvring characteristics and control requirements. A deep deterministic policy gradient (DDPG) algorithm was then used to implement the controller. Finally, some representative route segments of an inland waterway were selected for simulation research based on a virtual simulation environment. The designed DRL controller was able to quickly converge from the training and learning process to meet the control requirements. The effectiveness of the DDPG algorithm was verified by comparisons with the experimental results. This study provides a reference for future research on collision-avoidance technology for ASs in inland rivers.
Notation
- at
action at time t
- E
environment
- J
starting distribution
- L(θQ)
loss
- Q(s, a)
action value function
- rt
reward at time t
- st
state at time t
- st+1
new state at time t + 1
- β
stochastic behaviour policies
discount factor
- ρ
distribution function
- ρβ
state distribution function of the sample space
- μ
deterministic policy
- π∗
optimal policy
1. Introduction
Safety is the most important factor in ship path planning due to the complex manoeuvrability of ships and the characteristics of ship navigation. Presently, collision avoidance is the main research direction of ship path planning in China and other countries, including the safe avoidance of static obstacles (islands, reefs, bridge piers etc.) and dynamic obstacles such as other ships. One or more of the objectives of economy, safety and timeliness are usually used as evaluation indicators.
Deep reinforcement learning (DRL), a key research hotspot in machine learning, has had remarkable progress in games and robot control in recent years. The development of autonomous mobile robots, intelligent drones and autonomous vehicles has increased significantly. Moreover, the realisation of these technologies requires the corresponding intelligent machines to have the ability of reactive obstacle avoidance (Bandyophadyay et al., 2010; Kamalapurkar et al., 2016). A reinforcement learning algorithm is a decision making algorithm that guides an agent to execute action strategies according to the state information using reward signals. The reactive obstacle avoidance problem requires the robot to make action decisions immediately after acquiring sensor information. Therefore, reinforcement learning is a new and effective method for solving reactive obstacle avoidance problems.
DRL complements the strong perception ability of deep learning and the decision making ability of reinforcement learning and has more advantages than traditional methods in dealing with complex tasks. DRL technology has been applied in the field of intelligent ship control. Zhang et al. (2014) used the Sarsa on-policy algorithm to develop a behaviour-based local path planning and obstacle avoidance method for autonomous ships (ASs), and tested it in a real marine environment. Fu et al. (2018) used a feature fusion pyramid network and DRL to develop a ship rotation detection model. The duelling Q network was applied to the task of tilting ship detection to realise the function of AS guidance and docking. Wang et al. (2018) achieved good experimental results by introducing a heading tracking control scheme for ASs combined with the deep deterministic policy gradient (DDPG) algorithm. Yang et al. (2019) demonstrated the autonomous navigation control of an unmanned ship based on the relative value iterative gradient algorithm. They also designed a navigation environment for the ship using the Unity3D game engine software. The simulation results showed that the AS successfully avoided obstacles and reached its destination in a complex environment. Zhao and Roh (2019) proposed an autonomous collision-avoidance model for ASs in a multi-ship environment using the proximal policy optimisation algorithm combined with a ship motion model and navigation rules. The model achieved timeliness and collision-free paths for multiple ships and had good adaptability to unknown complex environments. Shen et al. (2019) proposed a multi-ship automatic collision-avoidance algorithm based on the duelling deep Q-network (DQN) algorithm. They also combined ship manoeuvrability, crew experience and the International Regulations for Preventing Collisions at Sea, also known as the Collision Regulations (Colregs), to verify the path planning and collision-avoidance capabilities of unmanned ships. Chen et al. (2019) introduced a Q-learning-based approach for the path planning and manoeuvring of autonomous cargo ships. The method was able to learn an action–reward model and obtain an optimal action policy. The boat could find the correct path or navigation strategy after sufficient training. Zhang et al. (2019) proposed an adaptive navigation method based on autonomous surface ships at sea for hierarchical DRL. The method incorporated ship manoeuvrability and navigation rules (Colregs) for training and learning. The method was shown to effectively improve navigation safety and avoid a collision. However, the controller with fixed parameters could not achieve the optimal control performance for the controlled plant. Qin et al. (2022) optimised the control effort of linear active disturbance rejection control (LADRC) using online parameter adjustment, a DRL algorithm and the DDPG to enhance the LADRC for ship course control and to obtain the optimised parameters of LADRC in different conditions.
Zhao et al. (2019) used deep neural networks (NNs) to map the state of encountering ships to their own steering commands, making collision-avoidance decisions for multiple ships. Chun et al. (2021) proposed a collision-avoidance algorithm based on DRL to determine avoidance time and generate avoidance paths that comply with the Colregs for the most dangerous ships. Chen et al. (2021) used the DQN reinforcement learning method to simulate a collaborative collision-avoidance relationship between two ships. Zhou et al. (2021) used the DDPG algorithm to achieve intelligent collision avoidance for ships.
Liu et al. (2022) used a twin delayed DDPG algorithm to build an AS collision-avoidance model; they combined it with the Colregs for multi-ship encounter scenario training. Sui et al. (2023) proposed a method based on multi-agent DRL, which combined the attention reasoning method, the multi-head attention mechanism and the Colregs to construct a multi-ship intelligent agent collaborative collision-avoidance decision model.
Liu et al. (2023) considered environmental factors such as wind and current, static obstacles, dynamic obstacles and ship manoeuvrability. They combined the advantages of model-based reinforcement learning and model-free reinforcement learning and designed a decision model for ship collision avoidance based on the Dyna-DQN. Wang et al. (2024) proposed a novel reliability and risk hierarchical critic network, and integrated an intelligent collision-avoidance strategy optimisation algorithm based on safety reinforcement learning, which was applied to complex encounter scenarios such as busy ports. Lan et al. (2024) proposed a multi-stage collision-avoidance model based on fuzzy set theory and DRL, which could assist ASs in achieving precise collision-avoidance guidance in complex waterway traffic environments. Zheng et al. (2024) proposed a method called rule guided visual supervised learning and applied it to a collision-avoidance decision environment with maritime encounter generalisation ability. The advantages of this method in terms of adaptability and learning cost were verified.
Meng et al. (2024a) proposed a hybrid reliability-based design optimisation (RBDO) method based on a portfolio allocation strategy to complex engineering systems. Yang et al. (2024) introduced the multi-strategy enhanced circulatory system based optimisation (MECSBO) – an algorithm designed for global optimisation and RBDO. MECSBO was outperformed by the state-of-the-art algorithms in terms of accuracy, efficiency and robustness in RBDO problems. Meng et al. (2024b) proposed an intelligent optimisation-inspired support vector regression modelling strategy to construct a high-precision approximation model. These algorithms provided some reference for the AS collision-avoidance strategies proposed in this paper.
Early intelligent collision-avoidance decision making algorithms often focused on whether collision avoidance was successful or whether the optimal path was planned, with little or no consideration for ‘collision-avoidance rules’. Some algorithms did not consider emergency collision-avoidance situations, while some algorithms had problems such as local extremum, poor applicability to dynamic environments and weak ability to handle multi-ship encounters. To some extent, DRL algorithms will solve the problems of traditional algorithms by setting reward functions, deep NNs and using their own advantages.
DRL interacts with the environment through a reward function, maximising the expected cumulative return during the exploration and utilisation stages of the algorithm to find the optimal decision. Unlike other collision-avoidance decision making methods, DRL can achieve scenario-driven collision-avoidance decisions, such as regular encounter scenarios and dangerous scenarios with long tail effects, and can afford trial and error. In most cases, DRL methods can save the cost of collecting scenario data. However, there is a certain deviation between the training results in these simulators or demonstration data and the training results in actual scenarios. Moreover, there is always room for improvement in terms of the convergence and reliability of DRL methods. Although some scholars are studying the AS collision-avoidance decision making problem based on DRL, it is still in the initial stage of exploration and development. Its core key technologies have not been fully realised, nor has the theoretical system been systematically studied.
The DDPG method integrates the Actor-Critic (AC) framework on the basis of the DQN method, successfully solving the problem of processing continuous state space environments based on continuous action space. By using experience replay, the correlation between sampled data is reduced and the stability of NN training is improved. The use of a soft update strategy in updating the target network makes the learning process more stable. The use of a deterministic strategy gradient solves the problem of difficult convergence in the AC framework, making it a mature and widely applicable reinforcement learning algorithm. At present, there is a lack of research on the DDPG algorithm for AS collision avoidance in inland rivers, and the aim of this study was to fill this research gap.
In this work, an autonomous learning framework with DRL for autonomous driving tasks was constructed. The state space, action space, reward function and NN structure of DRL were designed based on the ship's manoeuvring characteristics and control requirements. A DDPG algorithm was then used to implement the controller. Some representative route segments of an inland waterway were selected for simulation research based on the virtual simulation environment. The designed DRL controller quickly converged from the training and learning process to meet the control requirements. This study provides a reference for future research on the collision-avoidance technology of ASs in inland rivers.
2. DDPG algorithm
The DDPG (Silver et al., 2014), which combines the DQN, deterministic policy gradient and the actor–critic algorithm, was developed to improve the training ability of existing policy gradient methods. It can be used to solve DRL problems on continuous action spaces, borrowing the basic concept of DQNs (Mnih et al., 2015): learning in mini-batches rather than online. The DQN approximates the value function using a NN. Its parameters are the weights of each layer of the network. The update value function updates the weight parameters. DQN stores tuples of historical samples in the form [st, at, rt, st+1] using a playback buffer, thus stabilising training and making efficient use of hardware optimisations (Mnih et al., 2015). Mini-batches are randomly drawn from the playback buffer to update the weights of the network during training (Lillicrap et al., 2015). Additionally, separate target networks are created as copies of the original actor and critic networks. The weights of the target network are constrained to vary slowly, thus significantly enhancing the stability of the network (Lillicrap et al., 2015).
The actor–critic algorithm is based on the policy gradient theorem, which allows applications in continuous spaces. It has two components – the actor network updated by the policy gradient theorem and the critic network, which estimates the action value function Q(s, a) (Figure 1).
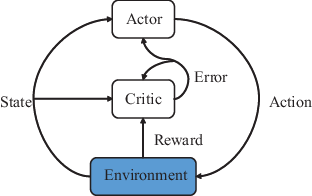
In DRL algorithms, a DDPG represents a successful application of NNs in the reinforcement learning paradigm to solve continuous control problems. The DDPG is a policy-based DRL algorithm that works with continuous state and action spaces. Policy-based reinforcement learning methods directly search for the optimal policy (π*), thus providing a feasible framework for continuous control. The Q-function (Equation 1) can be learned off-policy using transitions (from the environment E) generated from different stochastic behaviour policies (β) if the target policy (π∗) is a deterministic policy (μ) (Rodriguez-Ramos et al., 2019).
A function approximator parameterised by θQ approximates the Q-function in the DDPG. Optimisation is performed by minimising the loss L(θQ):
where
The use of a replay buffer and a separate target network to compute yt, first demonstrated by the DQN, is crucial for the convergence of large non-linear approximators (in discrete space) (Rodriguez-Ramos et al., 2019). The DDPG handles large continuous state and action spaces by modifying the actor–critic paradigm and using two NNs to approximate a greedy deterministic policy (actor) and a Q-function (critic). The DDPG method learns in 20 times fewer empirical steps than the DQN (Rodriguez-Ramos et al., 2019).
The actor network is updated by following the chain rule and applying it to the expected return from the starting distribution (J) in relation to the actor parameters (Equation 4).
Off-policy methods can be explored independently of learning. In this case, the entire autocorrelation Ornstein–Uhlenbeck (OU) noise is explored (Uhlenbeck and Ornstein, 1930).
The DDPG uses a deep NN with parameters θμ and θQ to represent a deterministic policy a = π(s|θμ) and a value function Q(s, a|θQ), respectively. For deep NNs, the distribution of the inputs to each layer changes with training (Ioffe and Szegedy, 2015) – a phenomenon known as internal covariate shift. This phenomenon leads to extreme difficulty when training models with large non-linearities (Ioffe and Szegedy, 2015). Networks with batch normalisation can reduce internal covariate shifts (Rodriguez-Ramos et al., 2019) by speeding up training and improving performance in the original setting (Ioffe and Szegedy, 2015). It is difficult to train DDPG networks due to the high degree of exploration freedom. Therefore, a DDPG network is usually trained by placing a batch normalisation layer on each layer of the NN before the activation function to improve training efficiency (Lillicrap et al., 2015).
The DDPG combined with the actor–critic algorithm, playback buffer, target network and batch normalisation can perform continuous control and improve training efficiency and stability compared with the original actor–critic network (Lillicrap et al., 2015). Therefore, the DDPG can be used in industrial environments, where control actions are usually continuous.
3. Collision-avoidance strategy for inland river ASs based on the DDPG algorithm
3.1 DDPG algorithm implementation framework
The established collision-avoidance strategy framework for inland river AS based on the DDPG algorithm is shown in Figure 2. The actor network (i.e. strategy), critic network (i.e. value function), simulation environment for inland river AS navigation and the experience pool are the main features of the algorithm. The environment accepts inputs from a network of actors and produces state transitions. The generated new states and actions are then passed to the reward function. The reward function passes the update to the critic network, which estimates the value of the state/action pair at the current time step. The new policy gradient and the new temporal-difference-error update the parameters of the actor and critic networks, respectively. The OU random process is used as the introduced random noise in the DDPG algorithm. The OU stochastic process has a very good correlation in time series, thus enabling the agent to explore the environment with momentum properties (Uhlenbeck and Ornstein, 1930).
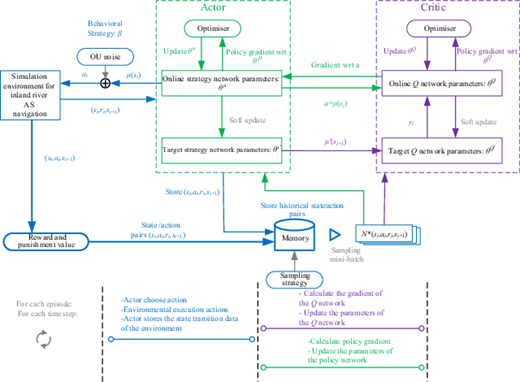
Framework of collision-avoidance strategy for inland river ASs based on the DDPG algorithm
Framework of collision-avoidance strategy for inland river ASs based on the DDPG algorithm
The DDPG algorithm generates a manipulation strategy using the actor network (Figure 2). Exploration noise is then added and sent to the simulation environment for execution. The designed reward function calculates the current reward value based on the state information. The DDPG algorithm stores the trained state, action, reward value and the next state ([st, at, rt, st+1]) into the experience buffer pool and trains the NN using the gradient descent method by randomly extracting experience (Hu, 2018).
3.2 State, action variables and reward function
Designing a proper reward function for model-free control is also difficult. The reward function must be precisely designed to inform the goal of the problem to the strategy. However, the state-behaviour space of non-zero rewards must be reachable in reasonable time from the initial conditions. This relationship requires proper coordination in the design of the reward function, the definition of the state space and the use of exploration during policy and value function fitting. The state variables, action control variables and reward functions are designed as follows.
3.2.1 State variables
The state information of AS collision avoidance selects the relative position value of automatic identification system (AIS) dynamic information position, course and speed to represent the encounter situation. The navigation status of the AS during collision avoidance is represented by coordinates (x, y, θ, v) corresponding to the real-time position, heading and speed information of the AS, respectively. The heading of the AS changes with the decision making information. The real-time position information of the AS is determined by the update of the current position, heading and speed. Manoeuvring an AS involves controlling the ‘attitude’ of the AS (i.e. controlling the heading, speed and position of the AS and other motion elements to ensure safe navigation).
3.2.2 Action control variables
It is crucial to determine how to control the AS to avoid obstacles and safely navigate to the target point. In the simulation, the steering, accelerator and decelerator are set to realise the real-time control of the heading and speed of the AS. These variables are defined in Table 1.
Definition of output variables
| Variable | Variation range | Specific description |
|---|---|---|
| Acceleration and deceleration | [−1, 1] | Values for accelerator and decelerator; −1 means the AS decelerates to the minimum and 1 means acceleration to the maximum |
| Steering | [−1, 1] | Steering wheel angle value; −1 means the steering angle goes to the rightmost position and 1 means the steering angle goes to the leftmost position |
3.2.3 Reward functions
The reward function plays a key role in the AS collision-avoidance strategy learning system. It is used to evaluate the effectiveness and safety of the AS collision-avoidance decision. The reward function is the feedback given by the system after the agent (AS) selects and performs actions according to the strategy in the current state. It is also the mapping from the state to the reward value and the driving factor for the agent to make the optimal decision. The agent makes decisions at any time by maximising the cumulative reward as the objective function.
The reward function is one of the key components of a reinforcement learning framework. Proper design of the reward function can make the algorithm converge faster and achieve better performance at the test time. In the proposed method, the reward function should be designed to reward smooth actions with respect to time when the agent intends to generate continuous control actions. When designing a collision-avoidance strategy for ASs, a ship is punished if it collides or goes out of the fairway line. The reward function can be designed as:
The AS is punished if it collides, so the reward value is set to −10. The reward value is set to 100 when it reaches the target point. When the AS leaves the channel when designing the reward function, its driving distance in the channel direction, the direction of the target point and on the longitudinal axis of the channel is weighted to obtain a reward value.
3.2.4 Training round termination conditions
The training round is terminated and started from the starting point if the following occurs:
the AS leaves the channel
AS collision occurs
the AS reaches the target point.
3.3 Implementation of the DDPG algorithm
3.3.1 Deep network design based on the DDPG algorithm
The DDPG algorithm has two deep networks – the actor policy network and the critic value network. In this work, both networks were constructed using Keras. The NN was trained by a momentum-based algorithm (Adam).
The actor network contains two hidden layers. The first layer contains 100 hidden units and the second layer contains 400 hidden units. The actor network input is the state of the simulation system, including two states of speed and direction. The ReLU function is used as the activation function of the hidden layer. The activation function of the output layer should be selected differently based on the value range of the variable. The output range of the ReLU activation function is [−1, 1], and this is used to remember the acceleration and deceleration commands of the AS. The tanh activation is used for continuous control. The output range of the tanh activation function is [−1, 1], and this is used to complete the steering command of the AS. Changes in the output of one layer can lead to highly correlated changes in the input of the next layer. The output changes are significant when the ReLU activation function is used. Layer normalisation of the actor network is conducted to avoid overfitting or gradient disappearance of the NN during training. Parametric noise is added to improve exploration, thus balancing the ‘exploration and exploitation’ contradiction.
The critical value network consists of two hidden layers. The first layer contains 500 hidden units and the second layer contains 100 hidden units. The input of the critical value network has two types of system state and action. The ReLU function is used as the activation function of the hidden layer, while the linear function is used as the activation function of the output layer. The Q value function of the state/action pair represents the output.
3.3.2 DDPG algorithm procedure
The process of the collision-avoidance strategy for ASs based on the DDPG algorithm is shown in Table 2. One episode represents a manoeuvring cycle and time t represents the time step in the manoeuvring cycle. This algorithm can make the training and learning process more stable by calculating yi using the target network of the critic network and the actor network. Performing actions when training and learning requires the addition of random noise to the output of the policy network. However, the output of the policy network is used as the execution action when the network has been learned and subsequently evaluated and used, and random noise cannot be added at this time (Uhlenbeck and Ornstein, 1930).
The algorithm process of collision-avoidance strategy for ASs based on the DDPG algorithm
| Initialise critic and actor network parameters: θQ and θμ |
| Initialise the critic and actor network target networks and directly copy parameters: |
| Initialise the experience pool R |
| 1: For episode = 1, M: |
| 2: Initialise random process N |
| 3: Obtain the initial state of the AS s1 |
| 4: For t = 1, T: |
| 5: Choose an action based on the current policy and random noise: |
| 6: Perform action at, get instant reward rt and next state st+1 |
| 7: Store state/action pairs (st, at, rt, st+1) into experience pool R |
| 8: Randomly sample K state/action pairs (st, at, rt, st+1) from the experience pool R |
| 9: Compute the ‘label value’ of the critical network: |
| 10: Calculate the error of the critical network and use gradient descent to update critical network parameters |
| 11: Calculate the gradient of the actor network and update the actor network parameters using gradient ascent: |
| 12: Update the parameters of the critic and actor network target network: |
| 13: End for |
| 14: End for |
The DDPG algorithm uses the deep network to fit the strategy function and the value function, thus expressing the more complex non-linear mapping relationship involved in the collision-avoidance strategy of ASs. The experience pooling replay and target network are used to de-correlate the data, thereby increasing the stability of the learning process and enhancing the ease of convergence (Hu, 2018).
4. Simulation experiments
Inland waterways are complicated with bends, many tributaries and many bridges. As a result, the navigation environment for inland waterway ships is complex and changeable, which often results in collisions. Specific parameters, such as the position and shape of known incoming ships and obstacles, can be obtained in real-time using AS environment perception system, shipborne radar and AIS. Straight waterways, curved waterways, bridge-area waterways and waterway intersections are all typical sections of inland waterways, which are representative for research (Cheng, 2007) and these scenarios basically comprehensively cover various situations that ASs may encounter. The simulation of the AS navigation strategy learning algorithm through Python was implemented as follows.
The hyperparameters in the network, such as the size of the experience pool, the learning rate of the network and so on are defined as:
Max_episodes = 2000
LR = 0.0006 # learning rate
Gamma = 0.99 # reward discount
Tau = 0.001 # soft replacement
Buffer_size(memory_capacity) = 20000
Batch_size = 20
Render = False
The strategy learning effects of the different situations (straight waterway, curved waterway, bridge-area waterway and waterway intersection) are shown by the number of training steps per round and the cumulative reward value per round. The two results clarify the effect of the agent learning strategy and test the effectiveness of the DDPG algorithm.
4.1 AS in a straight channel of an inland river
4.1.1 Collision avoidance between ASs and fixed obstacles
The collision-avoidance path in this scenario is shown in Figure 3. The coordinates of the starting point of the AS and the target are set at (150, 0) and (950, 0), respectively. The navigable water area boundaries of the channel are:
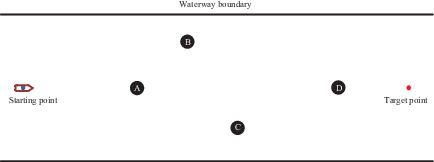
upper boundary coordinates: (0, 250)–(1000, 250)
lower boundary coordinates: (0, −250)–(1000, −250)
channel width: 500 m.
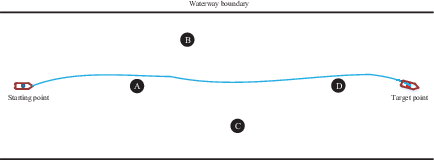
The coordinates of four fixed obstacles are located at point A (350, 0), point B (500, 150), point C (650, −150) and point D (800, 0) (Figure 3) .The experimental results are shown in Figures 4 and 5.
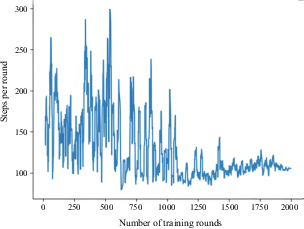
Number of training steps per round with four static obstacles in straight channel
Number of training steps per round with four static obstacles in straight channel
When the AS encountered four static obstacles in the straight channel, the AS was able to learn the optimal collision-avoidance path through strategy exploration and learning (Figure 4). The number of training steps per round is shown in Figure 5. OU exploration noise was added to the actions provided by the agent. As a result, the number of training steps of the agent became unstable during the first 1000 rounds. However, the number of training steps began to stabilise in subsequent training rounds, indicating that the agent had learned a better policy.
For the case of the AS in a straight channel with four static obstacles, the cumulative reward value of each round of the agent is shown in Figure 6. The agent improved the reward value of the environment through continuous learning, thus obtaining the maximum reward value. Therefore, the larger the reward value, the better the learning effect. OU random noise was added to the actions provided by the agent. As a result, the evolution of cumulative rewards during training was not stable. Nonetheless, the change in cumulative reward improved after the first 1000 epochs and subsequently stabilised for the rest of the training phase. The results show that the change trend of the cumulative reward value was consistent with the change trend of the number of learning steps.
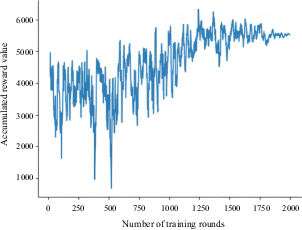
Cumulative reward value per round with four static obstacles in straight channel
Cumulative reward value per round with four static obstacles in straight channel
4.1.2 AS and multi-ship collision avoidance in inland waterways
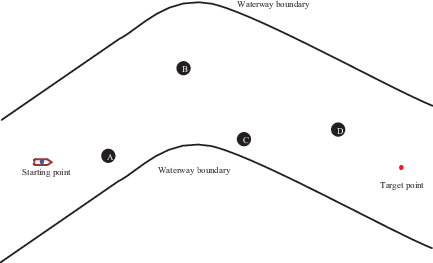
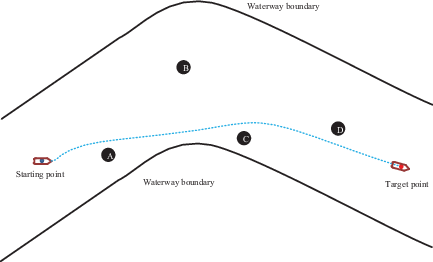
In this scenario, it was assumed that the initial coordinates of the AS was (150, 0), the target point is located at (950, 0) and the speed of the AS is 9 m/s. During the voyage, the AS will encounter three incoming ships, A, B and C, initially at (350, 200), (400, −230) and (750, 30) (Figure 7). The speeds of the incoming ships were set to 5 m/s, 9 m/s and 9 m/s, respectively. The encounters between the AS and the three ships had confrontation and cross-encounter situations.
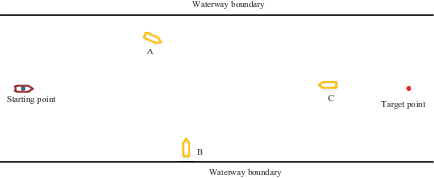
As shown in Figure 8, in this scenario, the AS was able to learn the optimal collision-avoidance path through strategy exploration and learning. The number of training steps per round is shown in Figure 9. OU exploration noise was added to the actions provided by the agent. Therefore, the number of training steps of the agent was not stable for the first 1750 epochs. However, the number of training steps began to stabilise at 1850 epochs, indicating that the agent learned a better policy.
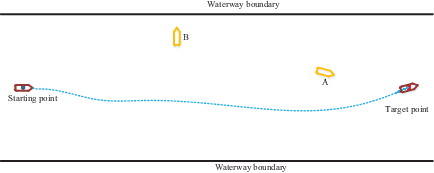
Collision-avoidance path of AS in inland straight channel with three incoming ships
Collision-avoidance path of AS in inland straight channel with three incoming ships
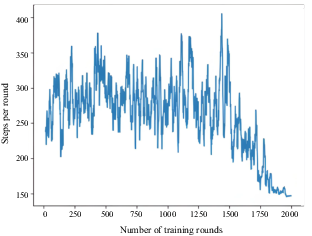
Number of training steps per round for three oncoming ships in straight channel
Number of training steps per round for three oncoming ships in straight channel
The cumulative reward value of each round of the agent is shown in Figure 10. OU random noise was added to the actions provided by the agent. Therefore, the evolution of cumulative rewards during training was not stable. Nonetheless, the change in cumulative reward improved after the first 1250 epochs and subsequently stabilised for the rest of the training phase. The number of learning steps and cumulative reward value increased at around 500 rounds. However, the cumulative reward value was stable after 1750 rounds since the number of learning steps did not significantly change. The change trends of the cumulative reward value and number of learning steps were consistent.
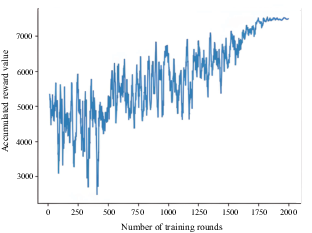
Cumulative reward value per round for three oncoming ships in straight channel
Cumulative reward value per round for three oncoming ships in straight channel
4.2 AS navigating a curved inland waterway
4.2.1 Collision avoidance between ASs and fixed obstacles
The initial state of this scenario is shown in Figure 11. The starting point of the AS was at coordinates (150, 0), the target point was at (950, 0) and four obstacles were located at points A (250, 70), B (450, 250), C (550, 110) and D (750, 150). The collision-avoidance path is shown in Figure 12, the number of training steps per round is shown in Figure 13 and the cumulative reward value per round is shown in Figure 14.
Collision-avoidance path of AS and in curved inland waterway with four static obstacles
Collision-avoidance path of AS and in curved inland waterway with four static obstacles
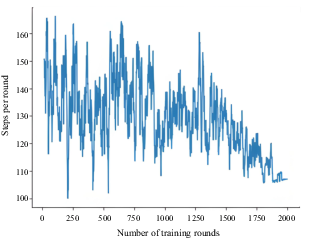
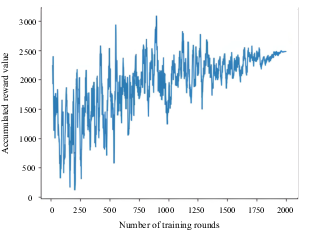
Cumulative reward value per round for four static obstacles in curved inland waterway
Cumulative reward value per round for four static obstacles in curved inland waterway
4.2.2 Collision avoidance of AS and moving ships
The initial state of this scenario is shown in Figure 15. The initial position of the AS was at coordinates (150, 0), the target point was at (950, 0) and the AS was sailing at a speed of 8 m/s. Three other ships (A, B and C) are present in the curved channel, located at (300, 50), (450, 350) and (750, 100), and travelling at sail at 5 m/s, 9 m/s and 9 m/s, respectively. The collision-avoidance path is shown in Figure 16 and the experimental results are shown in Figures 17 and 18.
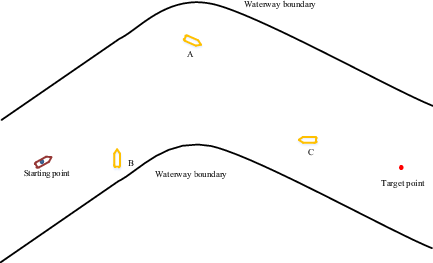
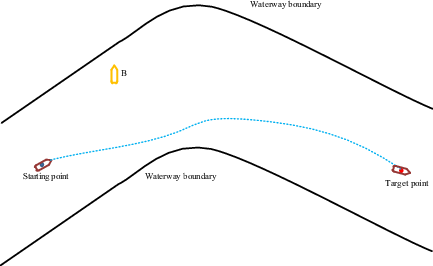
Collision-avoidance path of AS in curved inland waterway with three oncoming ships
Collision-avoidance path of AS in curved inland waterway with three oncoming ships
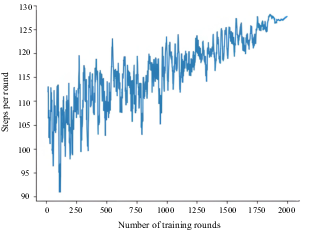
Number of training steps per round for three incoming ships in curved inland waterway
Number of training steps per round for three incoming ships in curved inland waterway
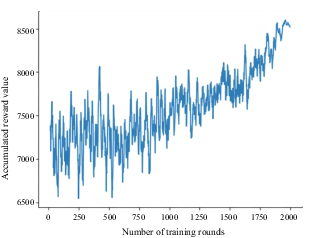
Cumulative reward value per round for three incoming ships in curved inland waterway
Cumulative reward value per round for three incoming ships in curved inland waterway
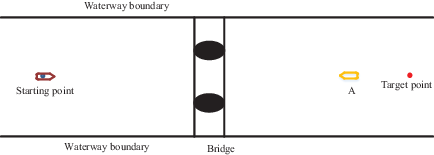
4.3 AS sailing in inland water area with a bridge
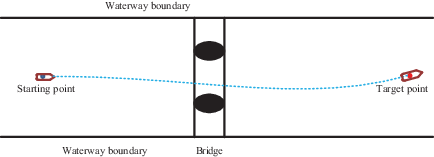
Figure 19 shows the initial state of the encounter between the AS and an oncoming ship in the vicinity of a bridge. The initial position of the AS is (150, 0), the target position is at (950, 0) and the AS is sailing at a speed of 9 m/s. The width of the channel is 150 m, the abscissa of the bridge axis is 550 m and the navigable water width between the two piers is 60 m. There is an incoming ship upstream of the bridge, located at (850, 50), sailing at 9 m/s. The collision-avoidance path is shown as Figure 20 and the experimental results are shown in Figures 21 and 22.
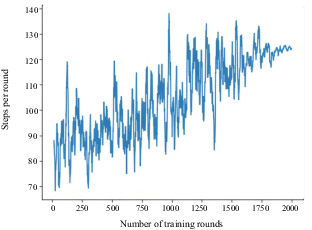
Number of training steps per round for incoming ship in bridge area of waterway
Number of training steps per round for incoming ship in bridge area of waterway
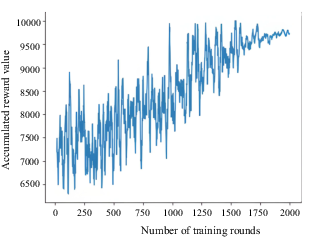
Cumulative reward value per round for incoming ship in bridge area of waterway
Cumulative reward value per round for incoming ship in bridge area of waterway
4.4 AS navigating intersection of waterways
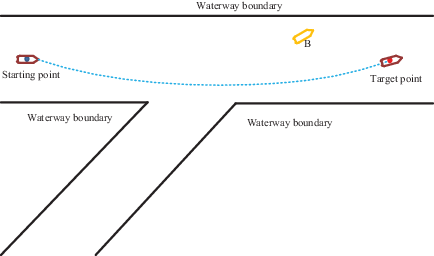
The initial state of an AS encountering two other ships at the intersection of the channel is shown in Figure 23. The initial position of the AS was set at (150, 0), the target position was (950, 0) and the AS was travelling at 9 m/s. Ship A was initially located in the same channel as the AS, at position (850, 0). Ship B was travelling along a tributary of the channel, at position (239, −348). The speed of ships A and B was set to 9 m/s. The collision-avoidance path is shown in Figure 24 and the experimental results are shown in Figures 25 and 26.
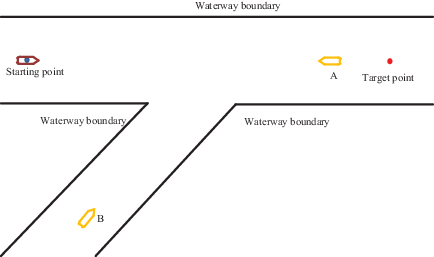
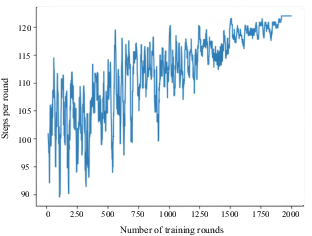
Number of training steps per round for waterway intersection with multiple ships
Number of training steps per round for waterway intersection with multiple ships
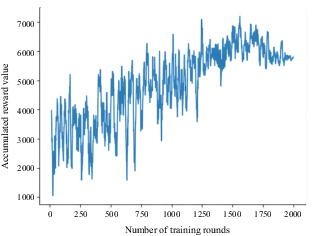
Cumulative reward value per round for waterway intersection with multiple ships
Cumulative reward value per round for waterway intersection with multiple ships
4.5 Comparison with AS collision-avoidance decision model based on DQN algorithm
In order to demonstrate that the DDPG model improved the convergence speed, a comparative experiment was conducted between the DDPG algorithm and the DQN algorithm for the scenario of the AS navigating an intersection of waterways. The two models were trained six times each, with 2000 rounds of training each time. The average reward values of the two models after six training sessions are shown in Figure 27.
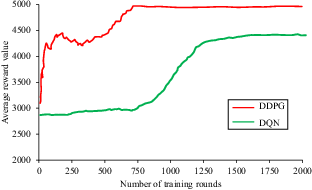
As shown in Figure 27, after 2000 rounds of training, the DQN algorithm initially converged slowly and reached its maximum value in round 1250. Compared with the DQN algorithm, the DDPG algorithm converged from round 30 to round 250 and had a higher return value than the DQN algorithm. It reached its maximum value at round 750 and had a return value greater than that of the DQN. The DQN is a model-free reinforcement learning method that requires a large amount of interactive data for policy updates, resulting in low data utilisation and a long training time. The DDPG algorithm adds a policy network to the DQN and determines unique actions based on input states. Updating of the strategy network is based on the temporal difference method. The off-policy algorithm uses experience replay technology and experience replay pool to improve sample efficiency by reusing historical data. Therefore, compared with the ship collision-avoidance decision model based on the DQN, the DDPG model had better training performance.
4.6 Discussion
Figures 4–26 show that the AS was able to learn the optimal collision-avoidance path through strategy exploration and learning. In addition, the numbers of training steps per round indicate that, because OU exploration noise was added to the actions provided by the agent, the number of training steps of the agent was unstable in the initial stage. In subsequent training rounds, the number of training steps began to stabilise, indicating that the agent had learned a better strategy.
The collision-avoidance path diagrams of four typical scenarios show that the AS was able to learn the optimal collision-avoidance path through strategy exploration and learning. Previous experimental results (Cheng, 2007) support the effectiveness of the proposed algorithm. Comparative analyses showed that the change trends of the number of training steps per round and the cumulative reward value in the four cases were not consistent. This may be due to the possibility that the agent (the AS) learned the strategy through continuous training during the learning process. Because the speed of the AS varied, when it learned faster it reached the target point more quickly, thereby reducing the number of steps required. If the agent takes a longer time to reach the target point, the number of steps required will increase. This will result in inconsistent trends in the number of training steps per round and the cumulative reward value.
To test the generalisation ability and robustness of the DDPG algorithm during the simulations, a test experiment with added noise was performed. In the experiment, OU random noise was added to the state of each component of the agent, resulting in a possible over-oscillation phenomenon. This made the behaviour unstable, but the final action may still be stable. It should be noted that, even under different environmental conditions, the agent achieved the desired effect in the simulation environment without the need for further parameter adjustment. Finally, the experimental results showed that the DDPG algorithm can learn complex and continuous control tasks, and the method has strong generalisation ability.
5. Conclusion
For traditional ship collision-avoidance algorithms, historical experience data cannot be recovered and used for online training and learning, resulting in low algorithm accuracy and uneven and redundant actual collision-avoidance paths. In this work, a collision-avoidance decision for ASs on inland waterways based on the DDPG algorithm was developed by designing reasonable corresponding states, action spaces and reward functions. To verify the applicability of the proposed method, various scenarios were simulated. The simulation experiments showed that the AS took the best and most reasonable action in unfamiliar environments, successfully completing collision-avoidance tasks and achieving end-to-end learning methods. In other words, use of the proposed method enabled agents to safely avoid collisions in complex environments. Finally, a comparison was made between DQN and DDPG methods. The results showed that the DDPG algorithm had faster convergence speed and accuracy, and achieved continuous operation output with smaller errors, further verifying the effectiveness of the proposed method. The method thus provides a certain theoretical basis for ensuring the collision avoidance of ASs navigating inland waterways.
In terms of future work, there are mainly two aspects. Firstly, in multi-ship scenario experiments, only agents perform actions to avoid collisions. In practical situations, multi-ship collision-avoidance tasks typically require the co-operation of ships. Therefore, DRL-based multi-ship collaborative collision-avoidance method is a focus of future research. Secondly, intelligent navigation is a complex task that includes path planning, path tracking, collision avoidance and more. The collision-avoidance algorithm will only be activated when there is a risk of collision between the agent and an obstacle. Designing an efficient algorithm that integrates multi-tasking to provide decision making support for the entire process of intelligent navigation is another focus of future research.
6. Societal implications and ethical considerations
There are many difficulties in translating theoretical research on AS navigation into practical engineering applications. Theoretical research results are often at a relatively low stage of technological maturity, while engineering applications require ensuring the maturity and reliability of related technologies. When translating theoretical research into practical applications, extensive experimental verification and testing is required to ensure that the adopted technologies and systems can operate effectively and reliably in real environments. Autonomous navigation involves the safety and reliability of ships, and any system failure or error may lead to accidents or losses. The application of autonomous navigation technology requires real ship projects for experimental verification to evaluate the actual application effect of the technology, which requires a significant investment in resources and funds, as well as multi-party support. The development and application of ASs need to be combined with relevant regulations and ethical principles to ensure that autonomous navigation decisions comply with ethical and legal requirements, taking into account human safety and ship responsibilities.
Author contributions
Conceptualisation, Zhang. Methodology, Zhang and Sun. Software, Zhang. Validation, Zhang and Sun. Formal analysis, Zhang. Writing – original draught preparation, Zhang. Writing – review and editing, Zhang. Both authors have read and agreed to the published version of this paper.
