This study aims to evaluate the efficacy of modern machine learning classifiers, random forest, gradient boosting trees, decision trees, support vector machines and logistic regression, in forecasting corporate bankruptcy among Italian firms, aiming to surpass traditional credit-scoring approaches by leveraging rich financial data.
Using a comprehensive panel of 1,826,157 firm–year observations (532,255 active; 76,464 bankrupt) from 1980 to 2019, the authors compare models trained on different data configurations, while addressing class imbalance through undersampling and advanced synthetic minority over-sampling technique (SMOTE) techniques. Models are validated on held-out samples, regional subsets and an out-of-time test (2016–2017), with performance gauged by area under the curve (AUC), F1-score, precision, recall and specificity.
Ensemble methods (random forest and gradient boosting) outperform other classifiers, particularly when using raw accounting inputs, achieving AUCs near 0.99 and F1-scores up to 0.98; resampling enhances robustness without diminishing predictive power, and variable-importance analysis underscores capital-structure metrics as key early warning indicators.
To the best of the authors’ knowledge, this is the first large-scale Italian bankruptcy study to juxtapose ratio-based models with high-dimensional raw data under multiple SMOTE variants, revealing that comprehensive financial statement variables markedly improve predictive accuracy and offering novel insights for both researchers and risk practitioners.
1. Introduction
Predicting corporate bankruptcy is a longstanding problem in accounting, auditing and finance, with clear implications for lenders, auditors, supervisors and managers. Methodologies have evolved with advances in data availability and computation, form early statistical models to modern artificial intelligence approaches, including machine learning and deep learning (Moll and Yigitbasioglu, 2019; Ranta et al., 2023). Because firm failure can propagate real-economy losses, accurate early-warning systems are valuable for decision-making. Our focus in on bankruptcy prediction (the probability a firm enters form insolvency), or credit scoring at loan origination (Climent et al., 2019; Lin et al., 2012).
Since the paper by Beaver (1966), many studies followed a conventional approach using a dichotomous variable (1 for bankrupt, 0 for active company). The conventional explanatory variables used in bankruptcy prediction typically consist of accounting ratios derived from financial statements. Among models built on accounting ratios, those developed by Altman (1968) and Ohlson (1980) became the milestones and continue to be used by researchers to detect financial distress. Alternative studies use factors not related to accounting. One example is the study by Bottazzi et al. (2011) focusing on productivity and growth. Another is Mueller and Stegmaier (2015) focusing on the size and age of firms, and others are Daily and Dalton (1994), Darrat et al. (2016), Liang et al. (2020) and Hazami-Ammar (2024), who study corporate governance indicators. Balcaen and Ooghe (2006) and Habib et al. (2020) have conducted extensive and comprehensive reviews. They provide in-depth analysis and insights into these topics. In addition, Jackson and Wood (2013) discuss the use of accounting measures as predictors of bankruptcy. It is important to acknowledge that these methods present some constraints. These methods can be sensitive to issues such as multicollinearity, outliers and missing data, which can affect the accuracy and reliability of the results. These limitations, together with the growth of large administrative databases, have spurred wider use of machine learning for distress prediction (Alaka et al., 2018; Chen et al., 2016; Desai et al., 2023; Liang et al., 2020; Ravi Kumar and Ravi, 2007; Tang et al., 2020). Our empirical design is guided by the idea that bankruptcy is less a sudden event than the endpoint of resource attrition and slack exhaustion. Financial statements provide direct, low-level measures of that process: profitability and margins speak to the ability to generate rents; cash, working capital and undrawn credit reflect deployable slack; leverage and interest expense capture constraints on discretion. When buffers shrink and claims tighten, managerial room to reallocate resources narrows, pushing failure risk higher. Because these mechanisms unfold over time, we expect multiyear raw accounting items, which retain the levels and paths of resources and obligations, to carry more predictive content than constructed ratios that compress or normalize away that information. This theoretical lens motivates our choice to compare ratios with two raw-item configurations and to evaluate models in an out-of-time setting that mirrors real early-warning use. Two literatures are most relevant. First, bankruptcy prediction in accounting and finance: foundational ratio-based models remain widely used (Altman, 1968; Beaver, 1966; Ohlson, 1980), while more recent benchmarks, often US centric, combine accounting and market variables and evaluate on rolling samples (Campbell et al., 2008). Second, a growing stream of research advocates raw financial statements items rather than ratios for certain prediction tasks; for example, Bao et al. (2020) study accounting fraud in US listed firms with three-based ensembles. The foundation of the accounting system lies in raw accounting data, making its potential role in bankruptcy prediction a compelling area of exploration Our study contributes by bringing a systematic raw-vs-ratio comparison to bankruptcy prediction and by ng so in a nonbank oriented setting. We compare three feature designs: ratios, a compact raw accounting data set and a near-full raw financial statement set, built from the last three fiscal years. We evaluate five classifiers: random forest (RF), gradient boosting (GBT), decision trees (DT), support vector machines (SVM) and logistic regression (LR). Finally, we emphasize strict out-of-time testing and imbalance-aware training with calibration and robustness checks. By focusing on Italy, where creditor rights, firm size distribution and reporting practices differ from the USA, we provide external-validity evidence on whether raw-item machine learning predictors travel across institutional regimes.
This paper stands out from previous studies firstly because it uses a significantly larger sample; our data set includes 532,255 active companies and 76,464 bankrupt companies and uses the last three financial statements. Because class imbalance can bias estimation, we implement random undersampling and synthetic minority over-sampling technique (SMOTE), including different extension of the original methodology, to test robustness. Our progressive design evaluates whether models that ingest raw accounting data, can surpass traditional ratio-based approaches and whether results hold under different sampling strategies, regions and out-of-sample and out-of-time validations. We also speak to the emerging discussion on the theoretical foundations of machine learning in accounting (Bertomeu, 2020). This has been possible using a progressive approach in testing the model. This approach is based on the use of a growing amount of accounting data obtained by reports that composed the comprehensive financial statement.
Across all settings, RF delivers the strongest performance, with GBT and DT close behind; LR and SVM are weaker. Models using raw accounting items outperform ratio-only designs, consistent with the RBV/slack lens that emphasizes resource levels and trajectories. Robustness checks by region and strict out-of-time splits confirm these patterns.
The paper proceeds as follows. Sections 2 and 3 present the related literature and theoretical background. Section 4 details the research design, data and sample selection. Section 5 reports empirical results and robustness analyses. Section 6 concludes.
2. Literature review
Early bankruptcy prediction models relied on univariate, multivariate, logit and probit techniques (Altman, 1968; Beaver, 1966; Edmister, 1972). Beaver (1966) used univariate analysis, testing 30 financial ratios one at a time on a sample of 79 firms in a paired sample. He found that working capital/debt was the most significant ratio for the classification in terms of discriminant power, followed by the net income/total assets ratio (Beaver, 1966). Altman (1968) introduced multivariate discriminant analysis (MDA), using five ratios to create a linear discriminant function, achieving high accuracy but declining performance over extended time horizons (Altman, 1968). Later studies, such as Edmister (1972) and Deakin (1972), expanded these methods by incorporating more financial ratios.
Despite their early success, MDA and similar method faced significant limitations, including multicollinearity, sensitivity to outliers and strict assumptions of linearity and normality (Balcaen and Ooghe, 2006). To address these issues, researchers adopted logit and probit models, which estimate conditional probabilities of bankruptcy (Ohlson, 1980). Since the early studies by Ohlson (1980) and Zmijewski (1984), several contributions have gone on to use conditional models to predict business failure (Becchetti and Sierra, 2003; Charitou et al., 2004; Gloubos and Grammatikos, 1988; Hillegeist et al., 2004; Jones and Hensher, 2007; Keasey et al., 1990; Mossman et al., 1998; Zavgren, 1985). However, while more flexible, these models did not substantially improve classification rates (Son et al., 2019) and remained constrained by assumption about variable independence, data distribution, outliers and missing values (Balcaen and Ooghe, 2006). Traditional statistical models are characterized by strict assumptions on linearity, normality and independence among predictor variables and preexisting functional forms relating to criterion and predictor variable reduce their real-world applications (Hua et al., 2007). Recognizing these limitations, scholars turned to machine learning techniques, which offer greater adaptability and the ability to process complex, high-dimensional data (Wang et al., 2012).
Since the 1990s, the advent of machine learning and then deep learning transform bankruptcy prediction, significantly improving accuracy over traditional statistical methods. Various algorithms, particularly RF, SVM and GBT, have demonstrated superior performance. Barboza et al. (2017) compared statistical models with machine learning approaches and found that RF outperforms Altman’s Z-score model, consistently with other studies (Joshi et al., 2019; Petropoulos et al., 2020; Rustam and Saragih, 2018). Similarly, SVM has been widely applied, achieving good results in various financial contexts (Chen, 2011; Du Jardin, 2017; Gogas et al., 2018; Song et al., 2018; Tsai, 2020). Beyond tree-based models, neural networks have gained popularity for bankruptcy prediction. Research demonstrates that they outperforms better than traditional models, despite challenges related to interpretability (Du Jardin, 2010; Lee et al., 2005; López Iturriaga and Sanz, 2015). Ravisankar and Ravi (2010) tested novel neural network structures on a cross-country data set, improving accuracy, sensitivity and specificity. DTs have also been used to predict bankruptcy, with Du Jardin (2017), Fitzpatrick and Mues (2016) and Olson et al. (2012) showing higher performance using them. Kwak et al. (2012) applied machine learning approaches, such as DT and SVMs, to predict bankruptcy in Korea and found them effective.
Hosaka (2019) used convolutional neural networks (CNNs) on Japanese listed companies to identify their potential for detecting bankruptcy. Findings show that the “common” methods (e.g. discriminant analysis, SVM and AdaBoost) are outperformed by CNNs analysis. Mai et al. (2019) show that the combination of textual and accounting data can improve predictive power of deep learning algorithms.
Among deep learning models, generic artificial neural networks have often been used, with promising results, to predict business failure, as shown by various studies (Neves and Vieira, 2006; Chou et al., 2017; Du Jardin, 2018; Kim et al., 2016; Lee and Choi, 2013; Oreski and Oreski, 2014).
The application of ensemble classifiers appears to enhance bankruptcy prediction. Ensemble machine learning is based on the combination of multiple models and thus aims to restrict the error of a single base learner. Jones et al. (2015) and Jones (2017) show that GBT and similar methods offer higher performance than both conventional classification methods and sophisticated statistical learning techniques, such as neural networks and SVM (Hastie et al., 2009; Schapire and Freund, 2012).
Generally, the predictive power of an ensemble learner is higher than that of a base classifier. Accounting and finance literature acknowledges the validity of boosting models for bankruptcy prediction, and there is also agreement in other scientific fields that they have significant predictive power. Bagging (Breiman, 1996) and boosting (Schapire, 1990) are the most frequently applied techniques. Kim and Kang (2010) run a comparison of neural networks using boosting and bagging with neural networks which do not use them. They obtained improved performance when boosting and bagging techniques were used, with a slight advantage in terms of accuracy for the bagged model. Fedorova et al. (2013) tested a set of 888 firms from Russia comparing boosted neural networks with other techniques and the boosted model appeared to achieve highest overall accuracy. Boosting and bagging have also been applied to DT, and consistently with other algorithms, boosted ensembles outperform other classifiers. Achieving better performance than conventional models, GBT has been applied to bankruptcy prediction with good results. In fact, according to Jones (2017), GBT features make it possible to counter and overcome the constraints of traditional models, and the eXtreme Gradient Boosting (XGBoost) performs better than other traditional applications. Ziȩba et al. (2016) first used XGBoost on a data set made up of Polish firms, and found significantly better performance than traditional methods. Carmona et al. (2019) ran a comparison between XGBoost, LR and RF to evaluate their predictive power in the US banking industry, and once again, found substantial improvement in accuracy rates.
Other studies show the benefits of ensemble learning in terms of the accuracy of the prediction, especially when compared with SVM. Wang et al. (2014) developed a new boosted tree-based algorithm which proved to be more accurate than SVM. Heo and Yang (2014) tried to predict bankruptcy in Korea using an AdaBoost algorithm, comparing it with SVM and found greater accuracy for AdaBoost.
These studies share a common feature; taking into account machine learning capability to handle large data sets, the training sample is small. Again, as discussed in the literature, feature representativeness in a sample is usually helpful in improving the performance and accuracy of models. Liang et al. (2015) examined the effect of applying filter and wrapper-based feature selection methods on model performance in bankruptcy prediction and credit scoring. Through the comparison of various methods for feature selection and ensemble classification, Lin et al. (2019) find that genetic algorithms such as the wrapper-based feature selection method give better performance than filter-based. Jadhav et al. (2018) suggest an innovative process to select features able to enhance credit rating through the combination of information gain and a genetic algorithm.
Finally, the issue of bankruptcy prediction is commonly defined by significantly imbalanced data sets in which the number of active companies is higher than nonactive ones. Quantitative models which use a full sample may be affected by this and thus produce biased predictions. To overcome this problem, specific sampling techniques such as undersampling or oversampling can be used. Veganzones and Séverin (2018) show that great imbalance in a data set influences the performance of algorithms applied to the field of bankruptcy prediction, as prediction methods reward the majority class to the detriment of the minority class. They also report that resampling techniques can be useful, and that SMOTE is one the most efficient. Similar results have been obtained by Faris et al. (2020), their findings show increased performance as a consequence to SMOTE application. Together with the original version of SMOTE scholars have studies new extensions, some updates such as ADASYN, Borderline SMOTE or the combination with clustering techniques have begun to provide some interesting positive results (Garcia, 2022).
Borderline SMOTE has been applied on polish context to predict bankruptcy by Smiti and Soui (2020), showing significant improvement in classification rate of machine learning algorithms. Shen et al. (2021) used ADASYN founding improved performance metrics.
3. Theoretical framework
We view financial distress as the culmination of resource erosion and slack depletion that constrain adaptation. The resource-based view holds that survival depends on building and preserving valuable, rare and hard-to-imitate resource positions, while organizational slack, cash, working capital and borrowing headroom, buffers shocks and enables timely redeployment (Barney, 1991; Bourgeois, 1981). In financial statements, these mechanisms appear as level and trajectories of profitability, liquidity and leverage or interest burden. Accordingly, our predictors are not merely covariates but observable measure of resource stocks and constraints whose dynamics raise default hazard when slack is thin, and debt claims tighten. Following this RBV and slack lens raw accounting items can out-perform ratio-based analysis as they preserve information about the quantities and paths of resources that ratios can obscure. This view coheres with, and helps interpret, the canonical bankruptcy literature: accounting signals of deteriorating solvency and liquidity have long predicted failure (Beaver, 1966; Altman, 1968; Ohlson, 1980), and dynamic models that emphasize recent information further improve accuracy (Shumway, 2001). Market-informed work similarly ties higher failure risk to low profitability, high leverage, thin cash and volatile returns (Campbell et al., 2008). Complementing these statistical regularities, organizational research shows that, as firms encounter threat, threat-rigidity responses, centralization, curtailed search and short-term retrenchment, can worsen capability renewal and slack, hastening decline (Staw et al., 1981; Weitzel and Jonsson, 1989). Together, these streams motivate our empirical choices: we use multi-year raw financial data to track resource and slack dynamics, and we evaluate models out-of-time to reflect the temporal evolution of failure risk. Evidence that small-firm distress follows similar accounting regularities, and benefits from tailored predictors, reinforces this perspective for nonblue-chip settings (Altman and Sabato, 2007).
4. Methodology
4.1 Sample and data preprocessing
We gather data about Italian firms from 1980 to 2019, categorizing them into two groups: bankrupt and active or continuing (nonbankrupt) firms. The original sample includes 114,495 bankrupt firms and 867,974 active firms. Figure 1 illustrates the regional distribution of firms, revealing a higher concentration in Northen Italy. Financial statements data was obtained from AIDA – Bureau Van Dijk and where possible manually integrated. To develop a robust predictive model, we conducted extensive data preprocessing and cleaning. First, we removed observations with missing financial statement values to ensure data completeness.
Next, we excluded firms lacking three consecutive years leading up to bankruptcy date. We opted this threshold to maximize retained observations while ensuring predictive reliability. The resulting data set consists of 76,464 bankrupt firms and 532,255 active firms, totalling 1,826,157 firm-year observations, with each firm contributing data from its most recent three financial years. To our knowledge, this is the first study to handle a data set of this magnitude in bankruptcy prediction research. We constructed three data set panel with varying input variables. Panel A includes financial ratios (15 input variables) identified by practitioners and previous studies (Du Jardin and Séverin, 2011; Jones, 2017; Liang et al., 2016). Panel B, following the approach of Bao et al. (2020), used the raw accounting data used to compute the financial ratios (45 input variables). Then, given that this raw data is only a small part of the financial data contained in financial statements, we also followed the “brute force” approach suggested by Bao et al. (2020) in training and testing the model on a data set containing all the raw accounting data presented in financial statements (Panel C). This third data set thus consisted of all items contained in an annual report (215 input variables). This is possible because machine learning based models can handle very large amounts of features while remaining immune to irrelevant inputs. Preprocessing also covered variable standardization and missing value handling. Tree-based models (RF, DT, GBT) do not require standardization because they are scale-invariant (Hastie et al., 2009). Outliers were addressed by winsorizing features at the 1st and 99th percentiles. Missing values were imputed using year × industry medians estimated from the training data, and a binary missing-indicator was added for each imputed feature; ratios with zero or negative denominators were set to missing, flagged and then imputed.
4.1.1 Variables.
Bankruptcy is classified as a binary variable, where bankrupt firms are coded as “1,” and an active firm are coded as “0.” However, unlike previous literature, we code as bankrupt only the year where the firm actually starts the bankruptcy procedure.
Regarding input variables we use three different approaches. The first follows the widely accepted methods of using financial ratios, which have consistently demonstrated robust predictive power in bankruptcy research (Altman, 1968; Beaver, 1966; Jones et al., 2015).
Over the years, various financial ratios have been used to assess business failure risk, with the most reliable indicators linked to working capital, cash flow, earnings and leverage (Beaver et al., 2005; Jones, 2017). Building on prior research, we selected financial ratios and also integrated them with ratios defined in the Italian Association of Certified Chartered Accountants “Code of crisis and insolvency” [1] (Consiglio Nazionale dei Dottori Commercialisti e degli Esperti Contabili, 2019). These ratios were specifically designed and tested on Italian insolvent firms to enable early detection of financial distress and have demonstrated higher predictive efficiency than traditional scoring models such as the Altman Z-score. Appendix 1 provides a detailed definition of the selected financial ratios.
See Appendix 2 for descriptive statistics of main features used for the prediction, and for industries represented in the sample classified according to one-digit NACE codes.
4.1.2 Balancing the data set.
After data cleaning and removing missing values, the final data set remained highly imbalanced with active firms comprising approximately 80% of the sample. Given that the objective of this research is to develop a classifier capable of identifying bankrupt companies, it is crucial to ensure that the model effectively learns from the minority class. To address this imbalance, we applied both undersampling and oversampling techniques. For undersampling, we use random undersampling, where observations from the majority class were randomly removed to create a more balanced data set. However, reducing the data set size can lead to information loss, so we also implemented oversampling. Rather than using random resampling, which risks overfitting, we used the SMOTE as proposed by Chawla et al. (2002). SMOTE enhances the minority class representation by generating synthetic data points along the vector between and existing minority-class sample and its k-nearest neighbors (Ashraf and Ahmed, 2020). The literature suggests oversampling as the best approach for tasks like bankruptcy prediction (Veganzones and Séverin, 2018). SMOTE is the recognized as the most effective oversampling method (Lin et al., 2017), significantly improving model classification performance. Aware of this potential SMOTE have been updated with new extensions: Borderline-SMOTE, ADASYN, Safe-Level-SMOTE, DBSMOTE (Fernandez et al., 2018). To further validate our results, we explored three extensions, Borderline-SMOTE, ADASYN and K-means SMOTE. These advanced techniques refine sample generation by incorporating decision boundary adjustments, adaptive sampling and clustering approaches, ensuring a more representative minority class.
4.2 Machine learning models
RF, GBT, DT, SVM and LR were trained and tested using a 70/30 random split of the data, following a widely used approach in the literature (Hastie et al., 2009). In addition, to ass out-of-sample performance, 25% of the training data was set aside for out-of-sample validations, ensuring a robust evaluation of model generalizability. Appendix 3 presents comparative table for your five methods All the models are implemented using Python.
4.2.1 Decision tree.
DT is a supervised learning algorithm that classifies instances starting from a root node up to leaf nodes (Safavian and Landgrebe, 1991). The model follows a flowchart-like structure, where each node represents a decision rule, and leaf nodes correspond to class labels. These classifiers have recently become popular due to their powerful classification capability and intuitive interpretability (Gepp and Kumar, 2015).
4.2.2 Random forest.
RF is a machine learning technique used for classification and regression tasks (Breiman, 2001). It constructs multiple DT applied on bootstrap replicates of original samples by randomly choosing k independent variables. It is robust to the presence of outliers and noise in the training sample (Yeh et al., 2014). The core concept of the algorithm is to introduce random perturbations in the learning system, ensuring differentiation among the trees and then aggregate their predictions using ensemble techniques. The model outputs the classification class based on majority voting from the DT, providing more precise forecasts and, most importantly, avoiding data overfitting.
Randomizing both training samples and feature space, RF is able to improve performance, while however maintaining or even slightly increasing bias because of smaller variance. A key advantage over other machine learning algorithms is the ability to identify the contribution of each predictor in classification. It does not simply respond to a need for classification, but also supplies information explaining the result (Maione et al., 2016). With an approach similar to bagging, it generates continuously classification functions based on subsets. It avoids correlation in bootstrapped sets by randomly selecting a subset of characteristics from each node of the tree (Booth et al., 2014; Yeh et al., 2014). RF has also been shown resistant to overfitting (Breiman, 2001).
4.2.3 Gradient boosting.
GBT is a widely used model in bankruptcy prediction. Proposed by Friedman (2001, 2002), known for its strong predictive accuracy (Gong et al., 2020; Landry et al., 2016). Unlike RF, which builds trees independently in parallel, GBT uses a sequential approach. It includes base learners as a weighted sum to reduce bias and variance and to reweight data that were previously misclassified. Since it strengthens scalability, it is used as the basis for many optimizations including XGBoost, LightGBT and CatBoost.
4.2.4 Logistic regression.
LR is one of the most frequent models applied to predicting bankruptcy. It assumes that active and failed companies are detected using a logit tie between the input variable, and the output variable. From a mathematical point of view, a LR estimated using our sample is equivalent to a discrete hazard model, used in the past for bankruptcy prediction (Shumway, 2001).
4.2.5 Support vector machine.
A SVM is a class of learning technique proposed in 1995 by Cortes and Vapnik (1995). The aim of this algorithm is the identification of the “hyperplane,” which is the maximum margin between two opposite classes, which in this case are bankrupt firms and active firms (Belavagi and Muniyal, 2016). Data are then plotted as a point for each class.
The classification result is determined by the class the point belongs to. The nearest points to the optimal hyperplane are named support vectors (Belavagi and Muniyal, 2016).
4.3 Performance analysis
To compare the performance of the models we choose the following metrics: accuracy, precision, recall, specificity, F1-score and area under the curve (AUC).
4.3.1 Accuracy.
Accuracy is one most widely used metrics for evaluating the performance of a machine learning model (Tharwat, 2018). It measures the amount of correctly classified items relative to the total test size. Ideally it is used to evaluate how well the classifier can correctly classify the elements, but very often it does not consider aspects such as accuracy in identifying a given class. In the first version of our model, it is not very useful as it does not work well with highly imbalanced data sets. It is however more useful in the second phase where resampling techniques rebalance the data set and the accuracy score can be estimated. Accuracy can be calculated as given in equation (1):
where TP is true positive, i.e. bankrupt firms correctly classified, and TN is true negative, i.e. active companies correctly classified. A false negative is a bankrupt firm wrongly classified and a false positive is a firm that is not bankrupt wrongly classified as such.
4.3.2 Precision, recall and specificity.
To avoid problems related to data set imbalance, three additional metrics are defined: precision, recall and specificity.
Precision is the ratio of the number of correct predictions of a class over the total of the times the model predicts it. So, when a model is effective for a class, it usually makes good predictions in that class. Precision’s calculation is given by equation (2):
The second metric, recall, is the ratio of how successfully the algorithm predicts positive values. It is also known as sensitivity and is computed as follows in equation (3):
Specificity refers to the true negative rate and the probability of a negative test, on condition that it is truly negative. It is computed as follows in equation (4):
Specificity quantifies how sensitive the model is to recognise a class, while specificity quantifies how specific the model is in distinguishing between classes.
4.3.4 F1-score.
Precision and recall are used to compute the F1-score that represents their harmonic mean. It is a significant measure for evaluating the performance of model without balanced sample. This metric is determined as given by equation (5):
4.3.5 Area under the curve.
The receiver operating characteristic (ROC) is a probability curve that illustrates a model’s classification performance by mapping the false positive rate (FPR) on the x-axis and true positive rate on the y-axis. It effectively visualizes recall against 1-specificity, based on the model’s predicted bankruptcy probability. This graph helps evaluate model performance as FPR increases and can also be thought of as a diagram revealing Type I error. The AUC is the area under the ROC curve, and it is a frequently used to compare results of models developed on unbalanced data sets (Bradley, 1997).
AUC values typically range from 0.5 to 1, where 0.5 indicates random guessing and 1 signifies perfect classification accuracy. AUC scores greater than 0.8 are proof of good and effective predictors. AUC values higher than 0.9 are viewed as sign of very strong classifiers showing an excellent balance between sensitivity and specificity. Note that for SVM the AUC is not applicable as the ROC curve requires probability estimates while the SVM provides the class labels directly as the outcome.
5. Results
Our analysis demonstrates that RF and GBT consistently achieve the highest predictive accuracy across all data sets. Notably, models using raw accounting data outperform those relying on financial ratios.
Table 1 (Panel A) shows the results for the first version of the data set with 15 financial ratios as predictors. Panel B shows the results for the second version of the data set using raw accounting data used to determine financial ratios. Panel C shows the results for the third version of the data set containing all raw accounting data from financial statements. The data set is unbalanced, so the results of the accuracy ratio are ignored for the present while the AUC and the F1-score are discussed below.
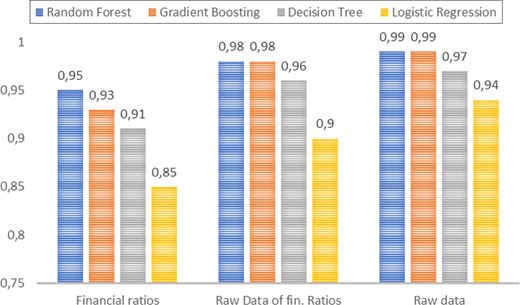
RF and GBT outperform other models in all the three versions of the data set, with DT close in terms of AUC. This results are consistent with previous contributions from literature that identified RF (Joshi et al., 2019; Rustam and Saragih, 2018), GBT (Carmona et al., 2019; Jones, 2017; Ziȩba et al., 2016) and DT (Du Jardin, 2017; Fitzpatrick and Mues, 2016) as more efficient than other methods. The results also suggest that the model that includes financial ratios as predictors has a lower performance than the models including raw accounting data. The model that uses all financial items contained in the annual report offers the best results, with an AUC that is very close to 1. RF and GBT registered 0.99. Figure 2 graphically presents the results and compares the various algorithms applied. The trend is also confirmed by the F1-score where there is a strong and consistent improvement moving from the model with financial ratios to those with raw accounting data.
In summary, we can conclude that RF, GBT and DT are the most effective machine learning methods for handling class imbalance, with RF showing superior performance. In addition, the use of raw accounting data improves model accuracy compared to financial ratios alone, reinforcing the value of granular financial statement information.
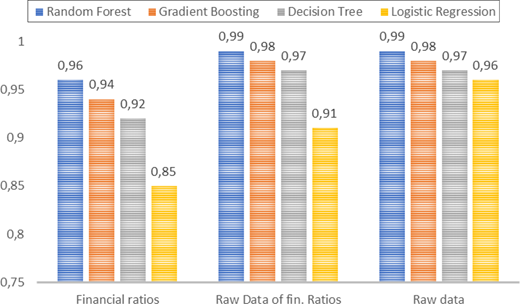
Aware of the limitations posed by imbalanced samples, we applied customized resampling techniques to evaluate the model’s performance. This approach also enabled us to incorporate accuracy as a metric for assessing the model’s effectiveness. Tables 2 and 3 present the results of applying SMOTE and random undersampling, confirming the robustness of our approach. These results are also graphically presented in Figures 3 and 4. Tables 2 focuses on SMOTE; demonstrating that balancing the data set enhance the reliability of model performance. Models trained on raw accounting data (Panels B and C) consistently outperform those relying solely on financial ratios (Panel A), as reflected in higher AUC and F1-scores. These findings align with existing literature on oversampling techniques (Faris et al., 2020; Garcia, 2022; Veganzones and Séverin, 2018), though our study uniquely examines a significant larger data set. Across all models RF and GBT consistently achieve the highest predictive accuracy with AUC values of 0.99 and 0.98, respectively, when trained on raw data. Balancing the data set enables a more reliable evaluation using accuracy as a metric, further reinforcing the effectiveness of these models. RF, in particular, achieves a 98% accuracy when trained on full financial statements data. Even models based on financial ratios perform well, with RF, GBT and DT surpassing 80% accuracy, significantly outperforming LR and SVM. To sum up, using SMOTE to reduce limitations of unbalanced data sets confirms the results previously obtained.
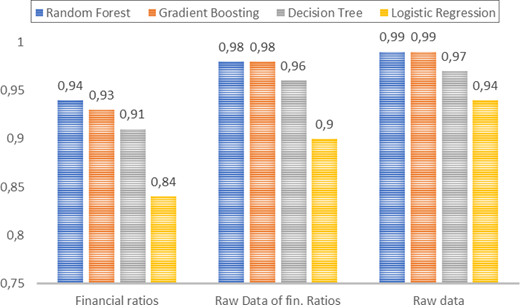
Table 3 presents the results of random undersampling, where observations from the dominant class were removed to balance the data set. Our findings confirm the stability and robustness of our research design; aligning with trends observed in the unbalanced data set. Notably, models trained on raw accounting data continue to offer higher performance than those based on financial ratios. Evaluating performance using AUC, F1-score, and accuracy, RF and GBT emerge as the top-performing algorithms. Their AUC values remain consistent across different data set variations, reinforcing their reliability. RF achieves an AUC of 0.99 when trained on raw data (0.94 with financial ratios), while GBT follows closely with 0.98 (0.93 with financial ratios). DT also demonstrate strong performance, with AUC increasing from 0.91(financial ratios) to 0.97 (raw data). A similar performance trend is observed in F1-score, further validating RF as the most effective bankruptcy prediction model. RF reaches a maximum F1-score of value of 0.98 when using the complete set of raw accounting variables, confirming its superior predictive power. While other models exhibit improvements with raw data, they remain less effective than RF and GBT, emphasizing the critical role of detailed accounting information in machine learning-based financial distress prediction.
Similarly, as seen with the SMOTE-applied model, accuracy serves as a valuable metric for assessing model performance. Once again, RF delivers the highest accuracy, achieving 0.98 with raw data, 0.86 with financial ratios and 0.94 with raw data used to calculate the ratios.
5.1 Out-of-sample validation
Out-of-sample validation is a crucial step in assessing a model’s ability to generalize to new information. This process helps detect overfitting, characterized by excellent training performance but poor results with real-world predictions. Out-of-sample technique allows us to detect such issues early on, enabling us to refine and improve the model accordingly. By splitting the data set into three independent subsets; a training set for model learning, a test set for evaluation and a validation set containing previously unseen observations; we ensure that performance metrics accurately reflect the model’s predictive capacities. The results confirm the strong performance of models when trained on raw accounting data. As show in Tables 4–6RF and GBT consistently achieve AUC values above 0.90, reinforcing their predictive strength. Panel C of Table 4 further highlights the advantage of incorporating raw accounting data, leading to enhanced model accuracy. In addition, the application of resampling techniques maintains model stability as evidenced in Table 5 (SMOTE oversampling) and Table 6 (random undersampling).
5.2 Additional checks
To assess the potential influence of geographical factors, we tested RF on regional subsamples of Italian firms (see Appendix 4 for details). Given RF’s superior performance across all models, we focused exclusively on its results to evaluate its practical applicability. Table 7 presents findings from the unbalanced data set, confirming the consistency of RF’s performance across different regions. Following the methodology applied to the full sample, we first tested the model on the unbalanced sample (Table 7) and then evaluated its performance after applying SMOTE oversampling (Table 8) and undersampling (Table 9). In Table 7, Panel A reports results using financial ratios, while Panels B and C examine raw accounting data (used for ratios calculations) and full accounting data, respectively. Results are consistent with previous findings, demonstrating strong predictive performance. AUC and F1-score progressively improve as raw accounting data is incorporated, reinforcing its predictive value. Although resampling techniques slightly reduce absolute performance, RF maintains AUC values above 0.90, confirming its robustness. The results across Tables 8 and 9 further support RF’s reliability in various economic environments.
This paper aims to contribute to the ongoing debate on the use of machine learning in accounting research by systematically testing RF and GBT with different set of accounting features. The testing phase began with income statement (IS) variables only, then including only variable derived from balance sheet (BS). Finally, Table 10 compares results when using raw accounting data by both IS and BS. Following the methodology applied in previous tests, we conducted analyses on the unbalanced data set (Panel A), then applied oversampling (Panel A) and undersampling (Panel C). Results confirm that model performance improves as more features are incorporated.
5.2.1 Synthetic minority over-sampling technique oversampling extension.
To address class imbalance, we applied SMOTE and tested five models. Prior research highlights SMOTE’s benefits (Garcia, 2022), leading to the development of over 85 extensions (Fernandez et al., 2018).
Beyond standard SMOTE, we experimented with three extension: ADASYN, which prioritizes harder-to-classify minority instances (He et al., 2008); Borderline-SMOTE, which focuses oversampling on instances near the decision boundary (Fernandez et al., 2018); and K-means SMOTE, which enhances representativeness by integrating K-means clustering with SMOTE. For robustness testing, we applied these SMOTE variants only to RF due to its superior performance. Table 11 shows that all SMOTE extensions, maintain high predictive accuracy (AUC = 0.99) consistent with baseline SMOTE. Table 12 confirms that out-of-sample validation remains stable (AUC = 0.98).
5.2.2 Out-of-time analysis and economic-cycle evaluation.
To further validate our results, we conduct an out-of-time validation to assess the model’s external validity. We split the data set into two subsamples: a training data set which included observations from 2010 to 2015, and the out-of-time validation data set made of observations from 2016 and 2017. Using RF on an imbalanced data set we present the results in Table 13. As expected, performance slightly declines yet remains highly effective (AUC = 0.95). In addition, we asses temporal robustness by conducting two out-of-time tests aligned with major macroeconomic episodes to capture the effect of economic cycles. We focus on two episodes: the global financial crisis (2008–2009) and the sovereign crisis and recovery (2011–2013). We create two specific sub-periods: the first spans 2005–2010 and the second 2011–2015. For the global financial crisis, models are trained on data through 2004 and then tested on data from 2005 to 2010. For the second period, we train models on data through 2010 and then test them on 2011–2015. Untabulated results are similar to those from the baseline analysis.
5.3 Variable importance analysis
A common criticism of machine learning models, particularly neural networks, is their lack of interpretability, often referred to as the “black box” problem. However, techniques like RF and GBT allow for greater transparency by assessing relative variable importance (RVIs); a measure of how each input variable contributes to model prediction (Hastie et al., 2009; Jones, 2017). As it is a variable measure, a value of 100 to the variable with the highest contribution, while the remaining variables are adjusted in scale accordingly. To analyze interpretability, we computed RVI scores for RF using both financial ratios (Table 14) and raw accounting data (Table 15). Table 14 highlights debt ratio one year before bankruptcy as the strongest predictor (RVI = 100), followed by its values two and three years prior (RVI = 25.00 and RVI = 18.75, respectively). Additional higher liquidity (cash/current liabilities) correlates with a lower bankruptcy risk, aligning with prior research (Altman, 1968; Jabeur et al., 2021; Jones, 2017). The third most relevant variable is the ratio between tax liabilities and total assets, which makes a significant contribution to correct firm classification (RVI = 68.75 at t – 3 and 50.00 at t – 1).
Table 15 which examines raw accounting data, supports these findings and prior literature (Altman, 1968; Jabeur et al., 2021; Jones, 2017). Capital structure indicators remain the strongest predictors. Total short-term debt in the year preceding bankruptcy is the strongest overall predictor in RF, followed by equity level in the same year.
6. Conclusion
This paper evaluates the efficiency of five machine learning models, RF, GBT, DT, LR and SVM, in predicting bankruptcy using a large data set. By testing models on three sets of input variables (financial ratios, raw accounting data used for ratio computation and full financial statement data), we demonstrate that RF and GBT consistently outperform other models. The results confirming that incorporating raw accounting data enhances model accuracy, with AUC values reaches 0.99 when using the complete financial statement. Given the inherent class imbalance in bankruptcy data, we applied resampling techniques (SMOTE and undersampling) to validate model robustness. These approached mitigate bias toward the majority class, ensuring reliable classification of bankrupt firms. Our findings are aligned with prior literature (Barboza et al., 2017; Jones, 2017; Jones et al., 2015), confirming that ensemble models such as RF and GBT are highly effective for bankruptcy prediction. In addition, the analysis highlights that DT perform well (Carmona et al., 2019; Jones, 2017; Ziȩba et al., 2016), while LR and SVM remain less efficient in comparison. Overall, using raw accounting data guarantees consistently better performance for all the methods applied, and the use of the entire financial statement is more effective than the use of financial indicators. This also makes it possible to exploit the ability of these tools to handle a high number of variable inputs. Interpreted through the resource-based view and the notion of organizational slack, these findings suggest that the most predictive signals are observable footprints of a firm’s resource base and the claims placed upon it. Liquidity items (cash, working capital) proxy redeployable buffers; leverage and interest burden capture constraint tightening; profitability reflects the capacity to generate rents that replenish slack. When slack is thin and claims intensify, managerial discretion to reallocate resources narrows, an RBV/slack mechanism our models may detect in the joint evolution of statement items. The superior performance of raw multiyear inputs over ratios is consistent with this lens: raw items preserve the magnitudes and paths of resource stocks and obligations that ratio transformations can compress or obscure.
The results also align with organizational decline dynamics. As firms approach distress, retrenchment and centralization can slow capability renewal and investment, further eroding slack and amplifying the financial footprints our models exploit. Our interpretability analyses, RVIs, recurrently elevate capital structure, liquidity, coverage and profitability, which map directly to the RBV/slack constructs of resources, buffers and constraints. We emphasize that these are predictive associations: the models are built for early warning, not for identifying causal effects of managerial or policy interventions.
This paper offers interesting contributions to the literature showing that the use of raw financial data can improve performance of machine learning algorithms if compared with models using financial ratios as traditionally done in previous studies. This paper also contributes to the growing discussion on the role of machine learning in accounting science, a recent debate that mostly focused in accounting fraud detection (Bao et al., 2020; Bertomeu et al., 2021; Perols, 2011; Perols et al., 2017). This is the first attempt to understand how raw accounting data can enhance the performance of machine learning approach to predict bankruptcy. Our findings indicate that raw accounting data can significantly enhance bankruptcy prediction models, making them more effective than traditional financial ratios. This represents a notable shift in how financial data can be leveraged for predictive analytics in accounting and finance.
Our model underwent a series of robustness checks to control for potential bias due the high unbalance of the original data set. This paper has applied different oversampling techniques (SMOTE and its extensions), and it contribute to the literature by adding knowledge about the effectiveness of SMOTE and some of its main extensions in case of strongly unbalanced data sets (Shen et al., 2021). In addition, previous studies that have tried to analyze performance of different extension of SMOTE were focused on US context (Garcia, 2022), with this study we enrich literature by shedding the lights on a different setting.
This paper has implications for auditors, regulators, investors and the banking industry. Machine learning models appear in fact to be easy to manage and interpret and are thus of interest to practitioners. A complex phenomenon like bankruptcy can be more easily interpreted through machine learning models, especially when the most significant variables can be identified. An effective and clear bankruptcy prediction model is critical for many stakeholders, especially investors, banks, auditors and regulators. For banks and investors, predictive models enable better risk assessment and resource allocation, minimizing losses due to firm defaults. For auditors, these models enhance going concern assessment, allowing for early detection of financial distress and enabling auditors to provide more proactive recommendations to both management and authorities. The identification of the most important input variables also offers them the possibility to focus with more attention on those specific items. Notably, our results suggest that financial statements alone may be sufficient for bankruptcy prediction, eliminating the need to compute financial ratios separately. This could simplify data preparation and streamline risk assessment processes.
This paper has also implication for academics as results suggest that using raw accounting data can be able to provide valuable insights for the use of machine learning in bankruptcy prediction. This evidence could be useful to explore this same approach to develop machine learning models using raw accounting data for other purposes.
This study has limitations. First, its focus on Italina companies necessitates further research to determine the generalizability of these findings to other economic and legal contexts using larger data sets. Second, the reliance on raw accounting data, without theoretical underpinnings, warrants investigation into its contribution to binary classification. Future research could explore the inclusion of nonaccounting variables (e.g. governance, macroeconomic factors), different algorithms (including deep learning) and the development of a global, multicountry model.
Notes
Consiglio Nazionale Dei Dottori Commercialisti e Degli Esperti Contabili, Crisi d’impresa: gli indici dell’allerta (20 ottobre 2019).
The ROC curve requires probability estimates while the SVM provides the class labels directly as the outcome.
References
Further reading
Appendix 1
Set of financial ratios: Several indicators map to more than one economic construct (e.g. liquidity, leverage, coverage and efficiency). To avoid over-interpretation, we report for each ratio a primary domain (the construct most closely measured) and cross-links (other relevant domains). Labels are provided for exposition only; the predictive models use all features jointly and are not restricted by this taxonomy.