The study responds to address the practical problem faced by the digital marketers, content creators and digital business agencies on creating content, which is both human-readable and LLM-compatible. The present study identifies and analyses the key factors influencing content optimization for Large Language Models (LLMs) to develop a strategic framework for Large Language Model Optimization (LLMO) that aligns with modern search paradigms.
This research employs a two-phases multi-criteria decision-making (MCDM) approach combining CRITIC (Criteria Importance Through Intercriteria Correlation) to determine factor weights, and DEMATEL (Decision-Making Trial and Evaluation Laboratory) to map causal relationships. A panel of 15 experts across three countries (India, UAE and USA) rated the influence of five identified factors.
The study identifies five critical factors for LLMO: Retrieval Augmentation, Readability Enhancement, Content Quality Assurance, Filtering of Unsafe Content and User-Centric Content Design. Retrieval Augmentation and User-Centric Design emerged as key causal factors, while Readability and Content Quality acted as bridges or effects. Although factor weights were relatively balanced, the DEMATEL analysis revealed interdependencies highlighting the dynamic nature of LLMO.
The results provide actionable guidance to digital marketing experts and agencies, content strategists, marketing heads and developers to structure web content that is both human-readable and LLM-compatible. The study offers insights to organizations on how they can enhance their digital visibility and authority in AI-powered search ecosystems.
This study fills a critical gap by offering the first integrated CRITIC-DEMATEL framework for LLMO. It distinguishes LLMO from traditional SEO and offers a novel causal model to support the development of holistic, future-ready content strategies.
1. Introduction
Smarter digital content matters because AI and intelligent systems increase content effectiveness and engagement by generating and optimizing creative assets that better capture attention of the audience and drive their interest. Natural language generation and programmatic content systems scale personalization and maintain relevance across large audiences while improving productivity and lead generation (Deng et al., 2019; Kshetri et al., 2024). Data-driven personalization such as using audience signals, predictive models and fine-tuning on marketing objectives, raises conversion potential and aligns creative with specific market segments and contexts (Heitmann et al., 2025). These systems deliver competitive advantages through faster content iteration, automated testing and adaptive delivery that reduces manual costs and accelerates time-to-market (Kshetri et al., 2024; Deng et al., 2019). By raising engagement rates, improving ad performance in comparison to traditional content and upgrading lead quality through customized messaging, smarter content systems collectively improve marketing performance (Kshetri et al., 2024). Therefore, the discipline of information search has been greatly impacted by large language models (LLMs), which have changed conventional information retrieval (IR) paradigms. In the past, the main methods used by traditional search engines to find documents were keyword matching and ranking algorithms. Recent developments in LLMs, on the other hand, use natural language processing (NLP) to produce semantic, context-rich responses that frequently go beyond the bounds of traditional IR. LLMs can scan large datasets and extract pertinent contextual information through improved semantic search (Fu et al., 2025).
LLMs came up as a powerful substitute over conventional search engines. Chen et al. (2024) revealed that patients and their families have begun to prefer LLM-powered search systems due to their ability to interpret natural language queries and provide contextually appropriate answers. Similarly, Mendel et al. (2025) argued that people in general often compare the benefits of LLMs over conventional search engines. Overall, literature indicate that while LLMs often excel in immediacy and delivering nuanced responses, their performance varies upon the prompt engineering skills of the users, which directly affects the relevance and accuracy of the responses provided.
Literature aims to balance between the capabilities of LLM-based search systems and the challenges associated with their use. According to Sharma et al. (2024) conversational search interface biases can reinforce existing opinions and produce feedback loops, highlighting the need for careful design and regulatory monitoring. Hence, prompt engineering is important in extracting reliable information from LLMs, underlining it as a critical skill for analysts in both open-source intelligence (OSINT) and broader applications.
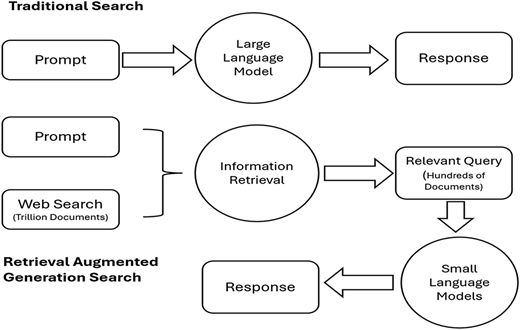
To address these pitfalls associated with standalone LLM generation, some studies have implemented retrieval-augmented generation (RAG) frameworks that integrate robust document retrieval with generative models. Byun et al. (2024) described a system that personalizes information retrieval by augmenting LLM outputs with relevant data from structured databases, thereby reducing hallucination and improving search precision. However, LLMs can generate human-like responses, augmenting them with real-time data retrieval remains essential to maintain authoritativeness, timeliness and contextual relevance. The difference between basic search and RAG framework is highlighted in Figure 1.
In traditional search a LLM takes the query as input and directly generates a response based on its pretrained knowledge. It doesn't fetch external data during inference. The RAG approach is a hybrid approach combining information retrieval with language modelling. The system searches trillions of web documents to retrieve a smaller subset of the most relevant documents. Instead of a single massive LLM, a smaller LLM is used to generate a response, grounded in the retrieved evidence. This enables the model to use up-to-date or niche knowledge not stored in its parameters. RAG framework is especially useful for real-time research, medical diagnosis, legal advice, financial news, where accuracy and recency matter. The integration of LLMs into information search has led to transformative changes in data processing and utilization (Figure 1). The enhanced natural language understanding capabilities facilitate more intuitive interactions and provide richer, more contextually appropriate responses compared to traditional IR systems. However, the literature also cautions that these systems are not without challenges. Bias, potential misinformation through hallucinated content and the need for sophisticated prompt engineering remain persistent issues that require further research and methodological refinement (Sharma et al., 2024; Byun et al., 2024). Thus, while LLMs have opened new frontiers in information search, continued innovation in retrieval augmentation and regulatory frameworks will be critical to fully harness their potential.
With the rising importance of real time search it is imperative that businesses understand how to optimize their website content for LLMs. The process is called Large Language Model Optimization (LLMO). While SEO (Search Engine Optimization) and optimizing content for LLMs have overlapping goals – making content discoverable and useful – they differ significantly in strategy, purpose and mechanics.
2. Literature review
Looking from dynamic capability lens, LLMO represents a transformative paradigm within digital marketing to attain competitive advantage (Kumar et al., 2024, 2025). This positioning extends generative AI's role beyond content creation to strategic knowledge systems that enhance personalization, efficiency and customer insights through advanced NLP capabilities (Kshetri et al., 2024; Khoshtaria et al., 2025). Conceptually, LLMO operates at the intersection of human enhancement and replacement across marketing cycle stages such as research, strategy formulation and tactical execution necessitating ethical governance frameworks to address autonomy, accountability and bias mitigation. The integration of LLMO within digital marketing innovation practices fundamentally reconfigures value creation mechanisms, enabling data-driven decision-making (Cillo and Rubera, 2025).
Fundamentally, SEO, SEM and SMM have been the drivers of digital marketing. SEO enhances a website's visibility on search engines, driving organic traffic and establishing an online presence. This process is intrinsically linked to content creation, where high-quality, relevant and engaging content is essential for attracting audiences, building brand reputation and improving search engine rankings (Samuel, 2013). Techniques for SEO include on-page elements such as keyword optimization, meta tagging and content quality improvements, as well as off-page elements like link-building and social signals, all of which are geared towards enhancing organic traffic and user engagement (Aman et al., 2024; Kamila et al., 2024). With the advent of technology, information and AI, marketing practitioners are compelled to integrate SEO, content creation and LLMs to effectively navigate the modern digital landscape. Literature published so far have progressed in multiple ways on developing knowledge and digital marketing strategies. For example, Berman and Katona (2013) offer a framework for optimizing search marketing, need of the efficient allocation of resources between SEO and sponsored links. Ho et al. (2020) present a conceptual framework for developing content marketing capabilities, outlining the necessary organizational strategies to build an effective digital presence through content, which is supported by few recent reviews (Blanco-Ruiz et al., 2024; Mukherjee et al., 2026). Hollebeek and Macky (2019) further enhance this understanding by exploring the crucial role of digital content in fostering valuable consumer engagement, trust and long-term relationships.
LLMs have revolutionized these practices by facilitating marketers by generating creative ideas and personalizing consumer experiences with data-driven insights. LLMs can help practitioners to enhance their customer engagement, satisfaction and loyalty and to position themselves as industry leaders in a competitive market. Bijalwan et al. (2025) explained the impact of advanced generative AI models, like OpenAI's Sora, on marketing and advertising employment, highlighting transformative shifts in job roles and skill requirements that are often preferred by the practitioners. This integration of technology, content strategy and engagement have capacity to drive modern marketing landscape.
AI-powered SEO tools utilizing machine learning and NLP continue to transform digital marketing practices through semantic keyword alignment, voice search optimization and automated technical improvements (Kumar et al., 2024). LLMs like ChatGPT enhance content creation, meta descriptions and chatbot interactions, while broader AI applications encompass predictive analytics, recommendation systems and conversational commerce (Singh and Namin, 2025).
2.1 Large Language Model Optimization
In contrast, the optimization of LLMs within Retrieval-Augmented Generation (RAG) frameworks diverges significantly from traditional SEO. While SEO optimizes static content for search engine indexing, RAG frameworks couple the retrieval of contextually relevant documents with the generative capabilities of LLMs to produce dynamic, context-aware responses (Potluru et al., 2025). In a RAG system, the optimization process focuses on two interdependent components. First, the retrieval mechanism must efficiently index and fetch high-quality, pertinent documents or data points from a knowledge base. Second, the LLM component must be fine-tuned to generate accurate and contextually informed outputs using the retrieved content (Potluru et al., 2025). This dual focus – optimizing both retrieval accuracy and generative performance – is largely absent in conventional SEO practices, which centre primarily on enhancing content visibility rather than content generation.
Furthermore, optimization for LLMs in a RAG framework often involves iterative fine-tuning processes, evaluation of prompt engineering and dynamic adjustment of retrieval parameters to balance response quality and computational efficiency (Potluru et al., 2025). In contrast, traditional SEO methods are more static; once a website's content and technical factors are optimized, subsequent changes are typically reactive (for example, in response to search engine algorithm updates) rather than an intrinsic part of an iterative feedback loop, as seen in RAG optimizations (Samuel, 2013; Aman et al., 2024). Therefore, the fundamental difference lies in the operational objectives: while SEO is primarily about increasing discoverability and ranking through keyword relevance and backlinks, the optimization for LLMs in a RAG framework is aimed at enhancing the synergy between information retrieval and natural language generation, ensuring that the outputs are both contextually appropriate and accurate (Potluru et al., 2025).The key difference between SEO and LLMO is listed in Table 1.
2.2 Factors affecting LLM optimization
Optimizing website content for effective featuring in LLMs requires a multifaceted approach that integrates enhanced retrieval methods, improved readability, quality assurance and structured design. First, retrieval augmentation strategies are critical as they enable LLMs to access current and high-precision information. Li et al. (2026) demonstrated that augmenting LLMs with non-parametric data/image retrieval significantly enhances the accuracy and relevance of the outputs. This result implies that websites intending to be featured in LLM-driven applications should curate and structure their content in ways that facilitate seamless extraction and integration into retrieval-augmented frameworks.
Furthermore, enhancing the readability of website content is essential for ensuring that LLMs can process and generate comprehensible summaries. Will et al. (2024) provided evidence that using LLMs to simplify and optimize text not only brings the content closer to the recommended reading levels but also maintains accuracy. As website content serves as both information for users and a training corpus for LLMs, prioritizing clear language and simple syntactic structures will support more effective content parsing and usage by these models (Zaid and Farooqi, 2024). Similarly, designing content with consistent metadata and schema markups can further aid in its discovery and retrieval by LLM architectures.
In addition to readability and retrieval, assessing content quality is paramount. Techniques that automate source evaluation can help websites ensure that only credible and safe content is incorporated. Hendrik et al. (2025) introduced an LLM-based tool to evaluate websites according to criteria such as relevance, comprehensiveness and accessibility. Integrating similar automated evaluations into web content management systems can serve as a quality control measure, ensuring that LLMs are supplied with high-standard, error-free data. The integration of filtering mechanisms Vadlapati (2024) to remove undesirable or unsafe content further secures the integrity of the information used by LLMs, positioning a website as a trustworthy data source.
Moreover, enhancing user experience on a website can be significantly achieved by integrating LLM features directly into the interface. Cultural heritage websites, for instance, have begun to utilize LLMs to synchronize browsing activities with dynamic content exploration, as shown by Cossatin et al. (2025). This approach not only enriches the user experience but also suggests that websites might benefit from designing content that is both user-centric and machine-friendly. By combining human and artificial intelligence in a unified interaction environment, websites can ensure that their content is accessible, engaging and optimally primed for LLM consumption (Rana, 2025). Thus, optimization of website content for featuring in LLMs involves a strategic synthesis of retrieval augmentation techniques, readability enhancements (Will et al., 2024), robust quality evaluation (Hendrik et al., 2025) and user-centric design principles (Cossatin et al., 2025). This comprehensive approach ensures that the content is not only high-quality and accessible for human users but also formatted and structured in a manner that meets the complex requirements of modern LLM architecture, ultimately enhancing the integration and performance of LLM-based applications.
The literature on LLMO remains limited. However, based on the available studies published in recent years, this study identifies five key factors that influence the development of an effective LLMO strategy. The factors are listed in Table 1. The review of literature suggests that there is an absence of any literature highlighting the key differences between SEO and LLMO. Furthermore, we were not able to find any literature providing a framework for effective LLMO. This study attempted to fill these research gaps. With this background the study has two research objectives (RO1).
Identify the key factors affecting Large Language Model Optimization
Develop a framework for effective Large Language Model Optimization
3. Research methodology
This study employs a two-stage multi-criteria decision-making (MCDM) approach combining the CRITIC (CRiteria Importance Through Intercriteria Correlation) method and the DEMATEL (Decision-Making Trial and Evaluation Laboratory) technique to prioritize and analyse causal relationships among the identified factors. The selection of the CRITIC method is grounded in its capacity to derive objective weights from inherent data variability and the degree of conflict among factors, thereby minimizing the influence of subjective bias. This characteristic is particularly beneficial in contexts where data-driven assessment is paramount. Literature exemplify this application by employing the CRITIC technique to determine criteria weights in their study on occupational hazard identification, demonstrating its utility in extracting robust, objective parameter valuations.
Similarly, the DEMATEL technique is widely adopted for its ability to uncover causal relationships among various factors, facilitating the classification of drivers and outcomes. This method helps construct an interdependent relationship network that distinguishes between cause and effect, leading to structured insights that support strategic decision-making. DEMATEL helps construct interrelations between criteria, reinforcing its appropriateness for identifying key drivers in complex decision-making environments. Further supporting this, Chakraborty et al. (2018) highlights the method's effectiveness in aggregating expert insights and exposing causal interdependencies among subsystems with minimal resource expenditure.
By integrating the CRITIC and DEMATEL methods, a robust, data-driven framework is created that enhances strategic development, such as that required for LLMO strategies. CRITIC provides a transparent, objective foundation by quantifying the influence of data variability, while DEMATEL complements this by revealing the underlying causal structure among factors. The combined application of these methodologies ensures that decision-making is both empirically sound and strategically insightful, as evidenced by their successful integration in various domains.
3.1 Research design
The methodology follows a structured four-step process, Figure 2.
Step1: Identification of Factors
A comprehensive literature review and expert consultations were conducted to identify critical factors influencing the research context. None of the factors were excluded by the experts and a total of five factors were shortlisted for further analysis.
Step 2: Prioritization Using CRITIC Method
The CRITIC method was applied to assign objective weights to the factors based on their contrast intensity and degree of conflict.
Step 3: Causal Relationship Analysis Using DEMATEL
DEMATEL was then used to map the causal relationships among the factors and classify them into cause-and-effect groups.
Step 4: Synthesis and Interpretation
The integration of CRITIC and DEMATEL results provided a comprehensive understanding of both the priority and interdependence of the factors.
3.2 CRITIC method for factor weights
The CRITIC method was used to compute the objective weights of factors based on the variability (standard deviation) and correlation among criteria. The decision matrix was calculated in which each respondent being a row while each column is given by factors. The original decision matrix was normalized to bring all criteria on a comparable scale. For each factor, the standard deviation was computed to reflect the contrast intensity. Next, the Pearson correlation coefficients between pairs of factors were calculated to measure redundancy.
CRITIC is used here as an objective way to estimate how important each LLMO factor is based on the experts' ratings. A factor receives a higher weight when (1) experts' scores vary more (it helps discriminate between factors) and (2) it is less redundant with other factors (it adds unique information). We then normalize these scores, so the weights sum to 1. The CRITIC score for each factor was determined using:
Where is standard deviation and is correlation between factors j and k. The final weight is then calculated using normalization:
3.3 DEMATEL for causal relationship modelling
To explore causal interrelationships among the factors, the DEMATEL method was used. A group of domain experts was asked to assess the influence of one factor on another using a scale of 0 (no influence) to 4 (very high influence). The average of the expert responses formed the initial direct-relation matrix. DEMATEL turns expert judgments about “how much one factor influences another” into an influence network. It helps identify driver factors (net influencers) and outcome factors (net receivers). This is useful for managers because it clarifies where to intervene first so that the levers trigger improvements across the overall LLMO system.
The matrix was normalized to ensure all values lie between 0 and 1. Next, total relation matrix (T) was calculated as:
Where D is the normalized direct-relation matrix, and I is the identity matrix. The prominence and net cause–effect values were computed for each factor using:
Where is the sum of the i-th row (influence given) and is sum of i-th column (influence received). Factors positive is cause factors, while those with negative values are effect factors.
3.4 Data collection
A focus group of 15 experts was convened to prioritize and model causal relationships. Experts were recruited using purposive sampling to ensure that they possessed relevant domain knowledge and diversity. Eligibility criteria included: (1) a minimum of five years of professional experience in digital marketing/content strategy, SEO/search analytics or AI/LLM-enabled information retrieval; (2) current involvement in decision-making or implementation of content/search initiatives and (3) familiarity with content quality, safety or user experience considerations in digital channels. To improve heterogeneity, we targeted equal representation across three countries (1/3rd from each India, UAE and USA) and both genders; the final sample characteristics are summarized in Table 2. Experts first validated the factor list derived from the literature and then provided independent ratings using a standardized questionnaire with clear anchors (1–10 importance scores; 0–4 influence scores). Focus group included both male (66.66%) and female (33.33%). Majorly having a post graduate degree and work experience of >5 years.
4. Results
Experts were asked to rate different factors' importance on a scale of 1–10. The decision matrix was prepared using their responses and listed in Table 2. Next the standard deviation (STD) for each factor was calculated.
Next the correlation between each factor was calculated. In the CRITIC method, the absolute value of the correlation coefficient is used when calculating the conflict or contrast between criteria. The resultant values are listed in correlation strength and are given in Table 3.
Next the critic score () was calculated for all factors and then weight was calculated using the formula discussed in the methodology section Table 3.
The result shows that retrieval augmentation is the most important factor contributing to effective LLMO followed by user centric design and filtering of unsafe content. The most important criteria found were readability and quality of content. One important observation being that the weight of all factors is comparable, which highlights the importance of all five factors in LLMO.
Next, we will discuss the result of the DEMATEL model. The experts from the focus group were asked to assess the influence of one factor on another using a scale of 0 (no influence) to 4 (very high influence). Out of twenty possible comparisons, one comparing the factor with itself was given zero score. The response for each comparison across all experts were aggregated by taking average of respective scores. This exercise resulted in an initial direct influence matrix given in Table 4. The initial direct relationship matrix was then normalized to get direct influence matrix (D). Then matrix operations were performed using MATLAB to get total relationship matrix (T) given by Table 5.
The next column sum (D) was calculated for each factor to quantify the influence given. Similarly, row sum was calculated to quantify the influence received by a factor. Finally, we calculated D + R for prominence (importance of factors) and D-R for relationships (cause or effect). Higher the value of prominence the importance of the factor is high. Secondly if a relationship is a positive factor is in effect group otherwise it is in a cause group. The result of the DEMATEL model is given in Table 6. The result of DEMATEL analysis suggests that prominence of all factors is comparable and an effective content strategy for LLMO should address all these factors to get their content featured in search of LLMs. The relationship results show that Retrieval Augmentation is the effect of combined effort of remaining four factors, namely Readability Enhancement and Content Quality Assurance. Filtering Unsafe Content and User-Centric Content Design.
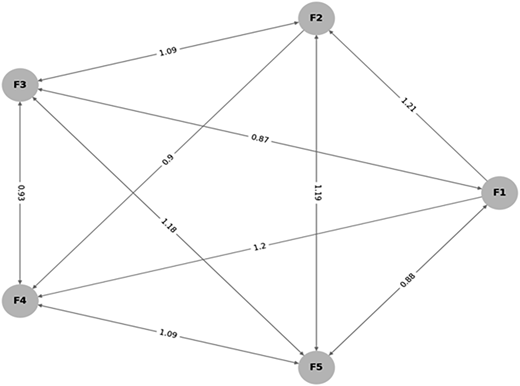
Finally, the Causal Diagram was derived from the Total Relationship Matrix using DEMATEL. In Figure 2 arrows indicate the direction and strength of influence (values > 0.8 shown), with thicker paths representing stronger relationships.
The causal diagram derived from the DEMATEL analysis reveals key interdependencies among the five factors influencing LLMO. Retrieval Augmentation (F1) emerges as a primary causal factor, exerting significant influence on Readability Enhancement (F2), Content Quality Assurance (F3) and User-Centric Content Design (F5). This highlights the foundational role of high-quality, contextually relevant information in shaping downstream processes. F2 functions as both a receiver and influencer – it is shaped by F1 and, in turn, impacts F3 and Filtering of Unsafe Content (F4), suggesting its bridging role in optimizing LLM comprehension and filtering accuracy. F3 and F4 appear as net effect factors, dependent on preceding enhancements in retrieval, readability and design, thus serving as performance outcomes of the optimization pipeline. Conversely, F5 stands out as a user-oriented driver, influencing F2, F3 and F4 by structuring interactions and content in alignment with human needs. Overall, the diagram underscores the importance of focusing on retrieval and user-centric design as strategic levers to amplify the effectiveness and safety of LLM-generated content. The summary of the cause-and-effect role of the five identified factors is listed in Table 7.
To assess the robustness of the CRITIC derived weights, a sensitivity analysis was conducted. First, ±5% perturbations were introduced to the standard deviation values to examine the stability of the normalized weights. The results indicated negligible variation in factor weights, with no change in relative ranking. Second, a leave-one-expert-out (LOO) analysis was performed by iteratively excluding each expert's ratings and recalculating weights. The mean deviations across iterations were minimal, confirming the stability of the weighting structure. These findings suggest that the CRITIC weights are robust and not unduly sensitive to minor fluctuations in expert judgments.
5. Discussions
This study presents a structured framework for LLMO by identifying key contributing factors and analysing their interdependencies using CRITIC and DEMATEL methodologies. The findings confirm that Retrieval Augmentation (F1) is a pivotal factor, aligning with prior research by Li et al. (2026), who emphasized the importance of integrating high-quality, real-time external data to enhance the accuracy of LLM outputs. This reinforces the growing consensus that retrieval-augmented generation (RAG) frameworks outperform standalone LLMs in information-rich applications, particularly in fields requiring current and domain-specific knowledge (Byun et al., 2024). The role of Readability Enhancement (F2) as a bridging factor also echoes the findings of Will et al. (2024), who argued that simpler language structures increase not only user comprehension but also the ability of LLMs to parse and summarize information effectively. However, unlike Will et al.’s emphasis on readability as a standalone design criterion, this study suggests that F2 is both influenced by upstream factors (such as retrieval) and critical in shaping downstream effects (such as content safety and quality), thus positioning it as a mediating factor rather than an isolated input. Contrary to some earlier studies, such as Hendrik et al. (2025), who posited Content Quality Assurance (F3) as a leading variable in ensuring reliable LLM integration, our causal analysis reveals F3 as a net effect factor. This implies that while quality remains essential, it is substantially determined by improvements in retrieval, readability and user-focused design. This divergence suggests that quality control in LLMO may be more of an emergent property than a controllable input, particularly in complex content ecosystems.
Findings of this study also show that Filtering of Unsafe Content (F4) is a downstream effect, reliant on the robustness of preceding factors. This result aligns with the filtering framework proposed by Vadlapati (2024), who emphasized automation and metadata as tools for removing undesirable data from LLM pipelines. However, our analysis extends this viewpoint by highlighting the systemic dependence of effective filtering on upstream readability and content quality assurance – factors not sufficiently emphasized in Vadlapati's model. A notable contribution of this study is the identification of User-Centric Content Design (F5) as a causal factor – a perspective supported by Cossatin et al. (2025), who demonstrated that user-aligned design not only improves engagement but also increases the likelihood of content integration into LLM workflows. This finding adds to the existing literature by emphasizing that the user experience is not merely a consumption endpoint but also a strategic entry point for LLMO.
6. Conclusions
This study proposes a novel framework for LLMO by integrating the CRITIC and DEMATEL methodologies to identify, prioritize and map the interrelationships among five critical factors: Retrieval Augmentation, Readability Enhancement, Content Quality Assurance, Filtering of Unsafe Content and User-Centric Content Design. The findings reveal that while all five factors are essential, Retrieval Augmentation and User-Centric Design emerge as primary causal drivers that significantly influence downstream elements such as readability, content quality and content safety. The study confirms that LLMO is not a linear process but a dynamic system in which factors interact with varying degrees of causality and dependence. By objectively assigning weights through CRITIC and mapping causal relationships through DEMATEL, the research fills an important gap in the current literature, which lacks structured models for content optimization tailored to LLM-based search and response systems. The results not only advance theoretical understanding but also offer actionable insights for digital marketers, web developers and content strategists seeking to make their content more discoverable, useable and authoritative within LLM ecosystems. The framework provides a foundation for developing holistic LLMO strategies that align with evolving AI search paradigms, moving beyond traditional SEO toward more semantic, user-focused and machine-friendly content creation practices.
7. Limitations and future directions
This study highlights the critical factors influencing LLM Optimization; however, certain limitations must be noted. The CRITIC results show that all five factors are comparably important, making ranking less meaningful without conducting a sensitivity analysis to validate the stability of weights. The analyses rely on expert ratings; although we used a standardized instrument and aggregated responses, such judgments remain subjective and can be influenced by experts' backgrounds and market contexts. Second, the expert panel (n = 15) was purposively selected and limited to three countries, which may constrain generalizability. Third, CRITIC produces data-driven weights but does not eliminate all bias originating from the input scores; future work could test weight stability via sensitivity analysis and inter-rater agreement and extend the panel. Finally, the DEMATEL structure reflects perceived influence pathways rather than empirically observed causal effects; future studies could validate the proposed relationships using larger samples and complementary techniques and triangulate with behavioural or performance data from real content/LLMO implementations. Future studies can employ Structural Equation Modelling (SEM) to statistically validate causal relationships and explore larger, more diverse samples. Incorporating real-time user data and machine learning analytics could further refine the framework and adapt it to evolving LLM and user interaction trends.