


Due to the limitations of current dynamic point cloud compression (DPCC) datasets, such as scarce categories, lack of detailed textures, and minimal variation in point cloud sequence movements. We present a comprehensive and diverse dataset, namely PKU-DPCC, to address the need for more categories and scene diversity for DPCC. Compared with the existing Moving Picture Experts Group (MPEG) and Audio Video Coding Standard (AVS) PCC datasets, the proposed dataset shows significant superiority in data scale, diversity, and compression difficulty. Specifically, our PKU-DPCC encompasses 50 dynamic point cloud sequences of six superclasses, and each sequence consists of 250 frames with geometry and attribute information and embodies the object or scene of a specific subclasses in the real world. Besides the diverse data content, samples in our dataset possess precise geometry details and various motion patterns, catering to a wide range of testing requirements in dynamic PCC. To construct this new dataset, we first collect numerous 3D meshes and then check the quality of each sample, resulting in 50 high-quality sequences for conversion to our final point cloud dataset. Furthermore, we conduct precise annotations for two scenarios of perceptible distortions and quality assessments on the provided point cloud data, which aims to broaden the range of its applications. To facilitate a fast algorithm performance evaluation, we select a part of representative samples constituting a subset, which has been adopted to the AVS PCC dataset. We conduct lossless and lossy compression tests on both geometry and attribute information from our subset to demonstrate the necessity of our newly constructed dataset. Experimental results reveal that the proposed dataset can become a new benchmark for evaluating and improving dynamic PCC algorithms. Our dataset is publicly available at https://openi.pcl.ac.cn/OpenDatasets/PKU-DPCC.
1 Introduction
Point clouds refer to a collection of points within a Three-Dimensional (3D) coordinate system. Each point represents a specific position in 3D space and may encompasses additional information, such as color or intensity values. Point clouds are generated from 3D scanning equipment like LiDAR sensors, structured light scanning, and RGB-D camera [12], etc. A LiDAR system emits laser beams and measures the time for these laser beams to bounce back after striking a surface. These measurements determine the distance to objects, creating a point cloud representation of the scanned scene or object. Point clouds find extensive applications in various domains. For example, in computer graphics, they are utilized to construct realistic 3D models of objects or environments. In computer vision, point clouds are processed to extract features, detect objects, or facilitate 3D reconstructions. In robotics systems, they provide a 3D description of the environment, which is crucial for robot navigation, obstacle avoidance, manipulation, and interaction. Moreover, they hold significant value in application fields such as architecture, archaeology, urban planning, and virtual reality, where the precise 3D representations of real-world objects or spaces are indispensable
Point cloud data, characterized by its voluminous nature, especially when derived from high-resolution cameras or sensors, necessitates the deployment of point cloud compression (PCC) methods to manage and process large-scale point cloud data effectively. This imperative stems from the need to handle the sheer volume of data and the desire to exploit this data across various technological domains. PCC research is pivotal in developing efficient algorithms and techniques to minimize the storage and transmission overhead associated with point cloud data. Effective compression can drastically reduce these requirements, leading to lower storage costs and enhanced efficiency in data management. This is particularly beneficial for organizations that rely on large-scale data collection, such as geographical information systems and 3D city modeling, where the economic and operational implications of data storage are non-trivial [25,42].
Furthermore, PCC plays a critical role in the context of data transmission. By compressing point cloud data, the volume of data that needs to be transmitted can be substantially reduced. This reduction is crucial for applications that depend on real-time data transfer, such as telepresence in virtual reality, live navigation updates in autonomous vehicles, and remote sensing for environmental monitoring. In these scenarios, the ability to transmit data efficiently over limited bandwidth becomes a key enabler of functionality and performance. Moreover, the ongoing research and development in PCC catalyze technological advancements in data compression and processing methodologies. These advancements enhance the state-of-the-art in PCC and foster innovation in related fields such as machine learning, computer vision, and spatial analysis. In essence, PCC research is a cornerstone of modern data processing, enabling leveraging point cloud data’s full potential. Through developing sophisticated compression algorithms and techniques, PCC research drives the evolution of digital technologies, paving the way for discoveries, applications, and efficiency in an increasingly data-driven world.
The PCC algorithms can be divided into two main categories: geometry compression and attribute compression. Geometry compression focuses on the geometry properties of the point cloud, such as the position. Point cloud geometry compression algorithms [38,13,37,1,14,39,34,32,35] reduce the size of point cloud data by encoding and compressing the spatial locations of points. These PCC algorithms commonly employ prediction, transform coding, quantization, and entropy coding to eliminate redundancies within the point cloud data. Point cloud attribute compression focuses on additional acquired information of the point cloud, such as color, intensity, and texture. Attribute compression algorithms [7,27] utilize image compression algorithms or other compression tools to remove the color redundancy among points. It is worth highlighting that geometry and attribute data are often jointly compressed to attain higher compression performance [47,41,14]. The design principles of the compression algorithm depend on the characteristics of point cloud data, application requirements, and the balance between rates and reconstruction quality [26,40,32].
The international standardization organizations are currently investigating PCC algorithms, including MPEG Geometry-based Point Cloud Compression (G-PCC) [22,10,15] and MPEG Video-based Point Cloud Compression (V-PCC) [46]. These organizations are dedicated to developing algorithms to achieve PCC more effectively and efficiently. Generally, MPEG G-PCC is a geometry-based compression standard initially focusing on static and dynamic acquired point clouds. It employs the coordinate and color quantization approaches to achieve different compression rates according to various application requirements. MPEG V-PCC is a video-based compression standard that converts point clouds into a series of video frames and then compresses these frames using existing compression algorithms or tools, such as Versatile Video Coding (VVC) [3], High-Efficiency Video Coding (HEVC) [28] to achieve high compression rate and reconstruction quality.
During the PCC process, the compression datasets play a vital role in training and evaluating coding models. Additionally, it serves as a crucial benchmark for assessing the effectiveness and performance of various compression techniques. Table 1 summarizes their application fields, advantages, disadvantages, and accessibility.
MPEG PCC datasets are created to evaluate and compare PCC algorithms in standards. These datasets contain static and dynamic point cloud from different sources, covering different scenarios and applications. Additionally, they are acquired mainly through specialized equipment, such as LiDAR scans, structured light scans, and RGB-D cameras. For example, Owlii1 [43], Microsoft Voxelized Upper Bodies (MVUB2) [21], and 8i Voxelized Full Bodies (8iVFBv23) [9] are acquired from RGB-D camera array [6,18]. The advantage of the MPEG PCC dataset is that it provides rich and diverse point cloud data acquired from different types of equipment, which process high-quality data and are suitable for different algorithm evaluations and research. However, the number of MPEG datasets is small, and the coverage is relatively narrow. The acquisition process of MPEG requires expensive professional equipment and technology, which limits the expansion and popularity of the dataset.
Stanford Bunny4 [29] dataset is a classic point cloud dataset containing a rabbit model. This dataset is commonly used to test and validate the performance and effectiveness of point cloud processing algorithms, such as reconstruction and completion. However, the dataset size is small, involving only one model of point cloud data. For the research community, a dataset with better diversity and complex scenarios is urgently required.
ShapeNet5 [5] and ModelNet6 [33] datasets are large-scale 3D CAD model databases, which contain rich point cloud data. These datasets are
The comparison of the existing static and dynamic point cloud compression (PCC) datasets with our proposed PKU-DPCC, describing essential information such as “Class”, “Frames Per Second (FPS)”, “Bit Depth”, “Frame Number”, “Attribute”, alongside their respective advantages and disadvantages.
| Dataset | Sequence | Class | FPS | Bit Width | Frame Number | Attribute | Characteristic |
|---|---|---|---|---|---|---|---|
| ShapeNet | Static | CAD model, 55 and 40 object classes, non-actual scene, 2048 points. | |||||
| ModelNet | Static | ||||||
| 8iVFBv2 | Longdress | Dynamic | 30 | 10 | 300 | R,G,B | Dynamic voxelized sequence, RGB-D camera, full-body portraits and various movements, a small range of motion. |
| Redandblack | Dynamic | 30 | 10 | 300 | R,G,B | ||
| Soldier | Dynamic | 30 | 10 | 300 | R,G,B | ||
| Loot | Dynamic | 30 | 10 | 300 | R,G,B | ||
| MVUB | Sarah | Dynamic | 30 | 9,10 | R,G,B | Dynamic voxelized sequence, RGB-D camera, upper bodies with gestural movements, contain holes. | |
| Phil | Dynamic | 30 | 9,10 | R,G,B | |||
| Andrew | Dynamic | 30 | 9,10 | R,G,B | |||
| David | Dynamic | 30 | 9,10 | R,G,B | |||
| Ricardo | Dynamic | 30 | 9,10 | R,G,B | |||
| Owlii | Basketball | Dynamic | 30 | 600 | R,G,B | Dynamic mesh sequence, full-body with various movements, a broader and more extensive range of motion. | |
| Dancer | Dynamic | 30 | 600 | R,G,B | |||
| Exercise | Dynamic | 30 | 600 | R,G,B | |||
| Model | Dynamic | 30 | 600 | R,G,B | |||
| PKU-DPCC | Fifty | Dynamic | 30 | 9–15 | 250 | R,G,B | Six superclasses, 50 point cloud sequences, arbitrary density sampling, rich scenes from real world. |
widely used in the research field of computer vision and computer graphics. However, the CAD models may have a simple geometry structure and textural. The acquisition methods of these point cloud datasets mainly involve techniques and equipment, such as LiDAR scanning, CAD, and mesh transformation. These methods require specialized equipment support, and thus the datasets are expensive to obtain. Meanwhile, there are limitations in the size and diversity, which can only partially cover some applications and scenarios. There is an urgent need for a scene and category point cloud dataset rich in as a benchmark for compression testing.
Therefore, we introduce a comprehensive and diverse dynamic PCC dataset to address the limitations existed in the dynamic PCC datasets. These limitations include single-category, lack of fine texture, and limited motion of point cloud sequences. Our proposed dynamic point cloud compression dataset, namely PKU-DPCC, features abundant motions information, which significantly increase the compression difficulty. Through the analysis of bitrates in lossy and lossless compression, we observe that controlling the bitrates is also challenging. The visualization of PKU-DPCC dataset is shown in Figure 1, and it offers the following advantages.
A curated dynamic PCC dataset, incorporating comprehensive geometry and color information, consisting of 50 sequences that encompass a diverse array of scenarios with intricate structures, great clarity, and six superclasses, as shown in Figure 2.
Each sequence consists of 250 frames, featuring a widely dynamic range and offering various quantization levels covering from 9 to 15 bits. Additionally, the dataset provides access to raw mesh data, which can be conveniently sampled to obtain any desired number of points for different requirements.
To complement the dynamic point cloud sequences, a rigorous clustering approach is employed to select multiple samples, followed by many comparisons of geometry and attribute compression performances using the AVS reference software and other learning-based compression methods. These analyses effectively highlight the notable differences between the newly constructed dataset and the other available dynamic point cloud datasets in AVS and MPEG. Meanwhile, a part of samples of PKU-DPCC have been adopted by AVS workgroup [36].

The visualization of PKU-DPCC dataset exemplifies its diversity and richness. PKU-DPCC encompasses six superclasses, each comprising various objects or scenes arranged diversely. The visualization offers a overview of the dataset’s contents, effectively showcasing the extensive array of objects and scenes it covers.
The visualization of PKU-DPCC dataset exemplifies its diversity and richness. PKU-DPCC encompasses six superclasses, each comprising various objects or scenes arranged diversely. The visualization offers a overview of the dataset’s contents, effectively showcasing the extensive array of objects and scenes it covers.

2 Data Acquisition
2.1 Data Generation
When preparing 3D point cloud models for training or testing on point cloud compression platforms such as MPEG G-PCC or V-PCC, we need to acquire a large amount of high-quality mesh data, such as from Sketchfab7, and process them in various ways. These processes include point cloud sampling at different texture resolutions (4096). While the sampling rates of these mesh data are generally consistent, the number of points in the sampled point clouds may vary due to differences in the original data. Additionally, we save the sampled data in different point cloud storage formats. Finally, we perform quantization of the point cloud data at various bit depths. In this process, we refer to MPEG’s distribution classifications for different datasets (e.g., Solid, Dense, etc.) to cover a wide range of quantization levels, ensuring the data meets the requirements of the compression tasks and is suitable for input into point cloud compression tools.
2.2 Data Clustering
In our experimental setup, we deploy K-means clustering [19,44,8] to assess the geometry and attribute compression ratios for each frame, utilizing the AVS PCRM v11.0 platform under C4 (All-Intra) conditions to calculate compression ratios. This approach allows us to create clusters with different K values, such as 4, 6, 8, and 10. It enables us to select point clouds representing various levels of compression difficulty. Meanwhile, we enrich the AVS dynamic point cloud dataset by offering a broader range of compression ratios for diverse algorithms. Upon removing the outlier point of Figure 3, the analysis of the clustering outcomes shows a more focused data distribution. It is noteworthy that the most favorable results emerge when clustering into eight groups (K = 8), including identifying two additional outliers. This clustering leads to six superclass datasets, in which a part of the subsets are selected as auxiliary dynamic datasets for AVS standards. This selection is introduced and explored in AVS proposal [36,23], enhancing the dataset’s utility for evaluating compression algorithms across a spectrum of difficulty levels.
3 Experiment Analysis
3.1 Test Condition
MPEG is embarked on developing geometry-based compression for dynamic dense point clouds, expanding its focus beyond dynamic sparse point clouds.
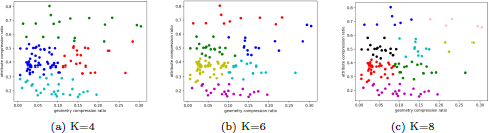
The clustering results of geometry and attribute compression ratios for different K in K-means method. The compression ratios are calculated by AVS Point Cloud Reference Model (PCRM) v11.0 [16] platform under C4 (All-Intra) conditions. We finally select a part of sequences as the complementary sequences for the AVS dynamic point cloud dataset.
The clustering results of geometry and attribute compression ratios for different K in K-means method. The compression ratios are calculated by AVS Point Cloud Reference Model (PCRM) v11.0 [16] platform under C4 (All-Intra) conditions. We finally select a part of sequences as the complementary sequences for the AVS dynamic point cloud dataset.
Dynamic dense point cloud coding may be the next research focus in AVS PCC inter-frame coding. AVS PCC encompasses four Category 3 (Cat3) type sequences: Basketball_player_vox11,
Dancer_player_vox11, Exercise_vox11, and Model_vox11. The upper of Table 2 provides the basic information about these sequences. The lower of Table 2 illustrates the fundamental characteristics of subset sequences selected for AVS standard. (1) The six columns in the Table 2 represent the number of point clouds, geometry quantization precision, number of frames, frame rate, geometry peak, and attribute information. “Geometry CR” and “Attribute CR” denote the lossless compression rates for geometry and attributes, respectively. (2) Compared to the existing 8iVFB and Owlii datasets, our dataset has a broader quantization range. As shown by the “Geometry CR” and “Attribute CR” in Table 2, our dataset presents greater compression difficulty and more complex data distribution. It encompasses a wider range of compression rates, posing higher challenges for different compression algorithms.
Meanwhile, Figure 4 shows the visualization results of the selected point clouds. These sequences serve as complementary to the existing AVS dataset. Subsequent experiments highlight the distinctions between these subset sequences and the current AVS sequences, which substantiates the validity of our proposed sequences.
We primarily focus on three key aspects to substantiate the suitability of the dataset as a supplementary sequence for the AVS dynamic point cloud dataset. These aspects are as follows: (1) Compression ratios: We evaluate the compression ratios derived from the geometry and attribute of the selected sequence, which effectively highlights the disparities between the newly added sequences and the existing ones. (2) Rate distortion performance: By examining the Rate Distortion (RD) curve, we assess the dynamic range disparity and the distortion of the selected sequence in comparison to the existing sequence. Notably, we observe a diminishing slope in the curve, indicating a reduction in distortion over time. (3) Variation analysis: To ascertain the rationality of the selected sequences, we employ the frame-by-frame variation analysis of our dynamic point cloud sequence. The magnitude of variation differences between adjacent frames serves as a determining factor for the appropriateness of the selected sequence. These investigations provide compelling evidence for researchers seeking to incorporate our dataset as valuable test sequence to their future endeavors.
Highlighting the distinctions between the newly proposed dataset and the existing AVS dynamic point cloud compression dataset. The “vox11” represents quantization to level 11. The “Total Point Number” means the number of points in 64 frames. The “Compression Ratio (CR)” is calculated by AVS PCRM software.
| Sequence | Point Number | Geometry Precision | Frame Number | Frame Rate | Geometry Peak | Attribute | Geometry CR | Attribute CR |
|---|---|---|---|---|---|---|---|---|
| Basketball_vox11 | 186, 907, 991 | 11 bits | 64 | 30 | 211−l | R,G,B | 0.02 | 0.33 |
| Dancer_vox11 | 166,028,718 | 11 bits | 64 | 30 | 211−l | R,G,B | 0.02 | 0.33 |
| Exercise_vox11 | 156,840,910 | 11 bits | 64 | 30 | 211−l | R,G,B | 0.02 | 0.35 |
| Model_vox11 | 163,936,020 | 11 bits | 64 | 30 | 2”−l | R,G,B | 0.02 | 0.32 |
| Woman_vox12 | 142,834,864 | 12 bits | 64 | 30 | 212−1 | R,G,B | 0.15 | 0.36 |
| Girl_vox12 | 147,479,840 | 12 bits | 64 | 30 | 212−1 | R,G,B | 0.17 | 0.25 |
| Caretaker_vox11 | 150,234,330 | 11 bits | 64 | 30 | 211−l | R,G,B | 0.20 | 0.51 |
| Lillian vox10 | 79,393,555 | 10 bits | 64 | 30 | 210−1 | R,G,B | 0.07 | 0.18 |
| House_vox 10 | 107,365,392 | 10 bits | 64 | 30 | 210−1 | R,G,B | 0.09 | 0.55 |
| Wardrobe_vox12 | 157,248,442 | 12 bits | 64 | 30 | 212−1 | R,G,B | 0.24 | 0.66 |
| Horned_vox12 | 135,128,173 | 12 bits | 64 | 30 | 212−1 | R,G,B | 0.11 | 0.29 |
| Vehicle_vox12 | 156,244,206 | 12 bits | 64 | 30 | 212−1 | R,G,B | 0.25 | 0.15 |
| Boat_vox12 | 153,911,463 | 12 bits | 64 | 30 | 212−1 | R,G,B | 0.20 | 0.49 |
| Tiger vox11 | 123,694,564 | 11 bits | 64 | 30 | 211−l | R,G,B | 0.11 | 0.46 |

The visualization of the clustered point clouds. It reveals significant disparities in category composition and data distribution compared to the original full-body human point clouds (Owlii [43]). Moreover, we conduct empirical demonstrations highlighting these differences, such as compression ratio and distortion.
The visualization of the clustered point clouds. It reveals significant disparities in category composition and data distribution compared to the original full-body human point clouds (Owlii [43]). Moreover, we conduct empirical demonstrations highlighting these differences, such as compression ratio and distortion.
The evaluation of compression performance for geometry and attribute are specific reference software: MPEG Geometry Solid Test Model v1.0 (GeS-TM) [17] as the inter-frame test benchmark, MPEG G-PCC8 TMC13 v21.0 [22] for intra-frame test analysis, and MPEG V-PCC9 TMC2 v12.0 [46] for interframe coding. The latest AVS Point Cloud Reference Model (AVS PCRM) v11.0 [16] also assesses compression efficiency for geometry and attributes. The following equation determines the Compression Ratio (CR) for geometry and attribute compression:
where “Bits” represents the size of the bitstream, “BW” is the bit width, and “PN” is the point number of the input point cloud. Geometry distortion is quantified using the Peak Signal-to-Noise Ratio (PSNR), Point-to-Point Geometry PSNR (D1 PSNR), and Point-to-Point Geometry PSNR with Hausdorff distance (D1H PSNR) [2]. Attribute distortion is assessed via PSNR for the YUV color components. Experiments are conducted on a desktop computer with an Intel(R) Core(TM) i9-9900K CPU at 3.60GHz and 32GB of RAM.
3.2 Non-learning-based Lossless Compression
We present the experimental results in three categories, following the principles of progressing from non-learning to deep learning based methods, and from geometry to attributes. The first category is non-learning-based lossless compression methods. This category primarily uses traditional compression algorithms to analyze the differences in compression rates between our proposed dataset and other datasets from a lossless compression perspective. Since most existing international and domestic standards focus on traditional compression algorithms, such as MPEG G-PCC and AVS PCC, we first analyze the compression performance of these traditional algorithms.
For lossless compression, we utilize traditional encoding tools, such as G-PCC, AVS PCRM, and Ges-TM software as our compression algorithms. This approach allows us to compare the performance differences between existing compressed datasets and our proposed dataset. The MPEG GeS-TM [17] software utilizes MPEG Category 2 (Cat2) test sequence to compress dynamic dense point clouds. While the Cat2 can be divided into easy-to-hard levels based on encoding difficulty: A level (8iVFBv2: Loot_vox10, 8iVFBv2: Solier_vox10, 8iVFBv2: Redandblack_vox10, Queen), B level (8iVFBv2: Longdress _vox10), and C level (Owlii: Basketball_player_vox11, Dancer_player _vox11). Notably, the results in Figure 5 reveal the contrasting assessments between G-PCC, AVS PCRM, and GeS-TM regarding the difficulty of point cloud compression.
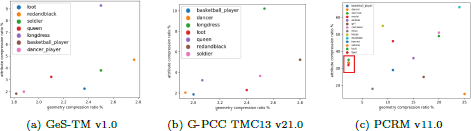
The scatter diagram of geometry and attribute compression ratios from various inter-frame compression tools. The objective is to compare the disparities between the existing AVS dataset and our proposed dataset. We acquire the compression ratios through different approaches: (a) employs the MPEG Geometry Solid Test Model (GeS-TM) [17] inter-frame test software. (b) utilizes the MPEG G-PCC software with an intra-frame setting. (c) highlights the disparity in compression ratios between the existing AVS dataset and our proposed dataset by AVS PCRM. The red box corresponds to the existing dynamic point cloud sequences of AVS, while the remaining dots represent our proposed dataset.
The scatter diagram of geometry and attribute compression ratios from various inter-frame compression tools. The objective is to compare the disparities between the existing AVS dataset and our proposed dataset. We acquire the compression ratios through different approaches: (a) employs the MPEG Geometry Solid Test Model (GeS-TM) [17] inter-frame test software. (b) utilizes the MPEG G-PCC software with an intra-frame setting. (c) highlights the disparity in compression ratios between the existing AVS dataset and our proposed dataset by AVS PCRM. The red box corresponds to the existing dynamic point cloud sequences of AVS, while the remaining dots represent our proposed dataset.
Table 3 presents the compression performance of V-PCC TMC2 v12.0 under the CW condition (lossless geometry and lossless attributes compression). By comparing the compression ratios and bit rate for the three levels of data within Cat2, we observe a progressive increase in compression difficulty, with the compression levels varying from low to high. We utilize the GeS-TM and PCRM software to evaluate these datasets thoroughly to obtain compression ratios and conduct scatter plot analyses. Figure 5 (a) exhibits the compression performance of GeS-TM v1.0 under the Octree-RAHT-C1 condition, explicitly highlighting the lossless geometry and lossy attributes. Notably, the Cat2 classification no longer adequately applies to geometry-based encoders (e.g., G-PCC), as it represents highly dense human point clouds. Conversely, geometry-based encoders demonstrate a more comprehensive applicability range compared to V-PCC [4,45]. They exhibit superior performance when dealing with diverse point cloud categories, such as objects, buildings, and landscapes.
Figure 5 (b) depicts the compression ratios for G-PCC TMC13 v21.0, employing the Octree-RAHT-C1 conditions. By examining the scatter plots of the compression ratio, we note minimal changes in the coding complexity relationship among the different sequences after incorporating the inter-frame coding tool. Furthermore, Figure 5 (c) shows that the four sequences within Cat3 exhibit similar compression difficulties, as highlighted by the area enclosed by the red box. However, our proposed new dataset (PKU-DPCC) exhibits significant disparities compared to the existing sequences, encompassing diverse categories, such as objects and buildings.
3.3 Non-learning-based Lossy Compression
The seond category considers the differences in attribute information. We present the compression performance of traditional algorithms on our dataset. Since existing learning-based attribute compression algorithms do not outperform traditional algorithms, we only showcase the performance of non-deep methods in simultaneous geometry and attribute compression.
We perform an analysis on four AVS sequences and subset sequences of PKU-DPCC using AVS PCRM V11.0 software. Meanwhile, we calculate the geometry and attribute PSNR values for various bitstream sizes and generate the RD curves, as shown in Figure 6. The distortion curves in Figure 6 (a) and (b), based on D1 and D1H distortion measures, indicate a wider range of distortion for our PKU-DPCC dataset compared to the same compression rates. The performance difference becomes more pronounced at higher compression rates. Figure 6 (c), (d), and (e) present the RD curves for the YUV components, illustrating that our data exhibits a smaller slope and lower bitrates than the four dynamic point cloud sequences in the AVS test condition.
The V-PCC TMC2 v12.0’s compression performance under CW conditions features lossless geometry and attributes. The “Compression Ratio (CR)” serves as a measure of the encoding difficult for the point cloud.
| Class | Sequence | Point Number | Geometry Precision | Frame Number | CR | Bitrate Bit Per Input Point (Bpip) (Mbps) | Geometry | Color | Total |
|---|---|---|---|---|---|---|---|---|---|
| Cat2-A | Loot_vox10 | 238,146,391 | 10 bits | 30 | 0.02 | 208.675 | 0.15 | 0.79 | 0.94 |
| Redandblack_ vox10 | 218,121,242 | 10 bits | 30 | 0.02 | 272.496 | 0.18 | 1.16 | 1.34 | |
| Soldier_vox10 | 322,589,704 | 10 bits | 30 | 0.02 | 318.805 | 0.17 | 0.88 | 1.05 | |
| Queen_vox10 | 250,602,891 | 10 bits | 50 | 0.02 | 411.186 | 0.16 | 0.89 | 1.05 | |
| Cat2-B | Longdress_vox10 | 250,294,582 | 10 bits | 30 | 0.03 | 355.663 | 0.15 | 1.36 | 1.51 |
| Cat2-C | Basketball_vox11 | 375,422,539 | 11 bits | 30 | 0.04 | 853.661 | 0.28 | 2.15 | 2.43 |
| Dancer_vox11 | 333,190,689 | 11 bits | 30 | 0.04 | 778.617 | 0.30 | 2.20 | 2.50 |
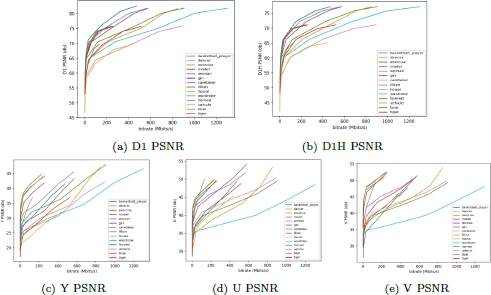
The RD curves of the compression performance of the four AVS dynamic point clouds sequences and the ten point clouds of PKU-DPCC sequences. (a) and (b) are the RD curves of geometry compression in terms of D1 PSNR and D1H PSNR, respectively. (c), (d) and (e) are the RD curves of attribute compression in terms of the YUV PSNR, respectively.
The RD curves of the compression performance of the four AVS dynamic point clouds sequences and the ten point clouds of PKU-DPCC sequences. (a) and (b) are the RD curves of geometry compression in terms of D1 PSNR and D1H PSNR, respectively. (c), (d) and (e) are the RD curves of attribute compression in terms of the YUV PSNR, respectively.
In summary, Figure 6 aims to demonstrate the compression differences between our dataset and the MPEG dataset, indirectly showcasing the varying levels of compression difficulty. The poorer compression performance of our data indicates a higher compression difficulty, posing greater challenges for both traditional algorithms and deep learning methods. These experiments also highlight the value of our dataset to the compression community.
3.4 Learning-based Lossy Compression
The third category is learning-based lossy compression methods. This category focuses on the latest state-of-the-art (SOTA) lossy compression algorithms based on deep learning. We analyze the RD curves from a lossy compression perspective and demonstrate the compression challenges presented by our dataset.
We conduct single-frame and multi-frame point cloud compression tests on a selected batch of PKU-DPCC. This batch of data is selected based on clustering results, with representative data chosen from each major category (superclasses) for experimentation. The chosen point clouds include the following four sequences: Animated_Woman, Tiger_Animation, Walking_Man, and Wooden_Boat. Specifically, Animated_Woman and Tiger_Animation are quantized to 10 bits, while Walking_Man and Wooden_Boat are quantized to 11 bits. For the multi-frame dynamic compression evaluation, the first 32 frames from these four sequences are extracted as test sequences.
For the lossy single-frame point cloud compression, we select representative learning-based compression methods for comparison, including the sparse convolution-based methods PCGCv210 [31] and SparsePCGC11 [30], as well as the residual coding based method GRASP-Net12 [24]. D1 (Point-to-Point Distance) PSNR and D2 (Point-to-Plane Distance) PSNR [20] are used as the evaluation metrics. These results of the single-frame lossy compression are shown in Figure 7, which indicates the following performance ranking: PCGCv2 > GRASP-Net > SparsePCGC > AVS PCRM > G-PCC. It demonstrates that our PKU-DPCC quantized to 10-bit and 11-bit range, presents a greater compression challenge compared to the conventional MPEG datasets.
For lossy dynamic point cloud compression, we employ the learning-based methods, including PCGCv2 and D-DPCC13 [11] for comparison. The overall compression performance is depicted in Figure 8. The compression performance on dynamic point clouds ranks as follows: V-PCC > PCGCv2 > D-DPCC. These results suggest that our dataset has a broad dynamic range, making compression more challenging for most learning-based methods like D-DPCC. Therefore, we recommend incorporating the proposed PKU-DPCC dataset into the compression performance tests of learning-based point cloud compression methods and standards.
3.5 Dynamic Range Analysis of Sequences
We perform a dynamic sequence analysis on the selected data, demonstrating the relationship between the number of frames and the total bitstream size in Figure 9. The entire bitstream encompasses the attribute bits, geometry bits, and head information bits. This analysis confirms the dynamic nature of our proposed sequences. The experiment exhibits significant diversity and encompasses a broad scope of motion amplitudes. For instance, Figure 9 (a) demonstrates the varying range of motion within the Animated_Woman, spanning from subtle to substantial and ultimately stabilizing. Figure 9 (b) indicates uniform motion and insignificant variation. Figure 9 (c) and (h) depict intermittent movements characterized by both forceful and gentle actions. Figure 9 (d) and (f) show that the mid-term movement is intense, and the front and back are more moderate. Figure 9 (e) reveals a smooth initial motion followed by a sudden, substantial jump. Figure 9 (g) presents irregular motion information. Figure 9 (i) portrays a progression from smooth to violent and back to smooth motion. All these result analyses indicate that our data (PKU-DPCC) possesses a good dynamic range, presenting greater challenges for dynamic point cloud compression algorithms and coding tools. The dataset also indicates that we have contributed an excellent benchmark to the point cloud compression community.
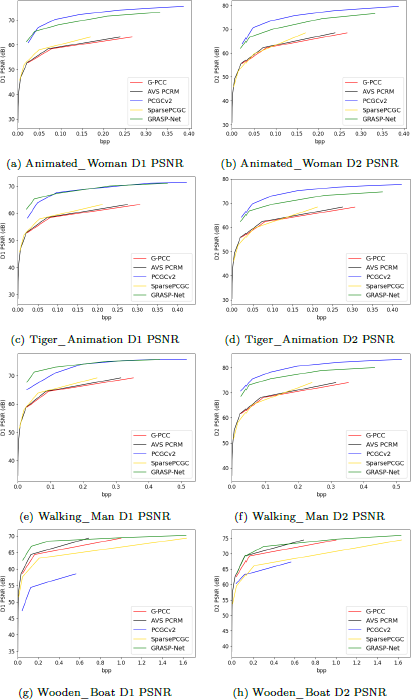
The RD curves of lossy geometry compression using the learning-based networks on selected single-frame point clouds from PKU-DPCC. With the metric measurements by D1 PSNR and D2 PSNR, respectively.
The RD curves of lossy geometry compression using the learning-based networks on selected single-frame point clouds from PKU-DPCC. With the metric measurements by D1 PSNR and D2 PSNR, respectively.
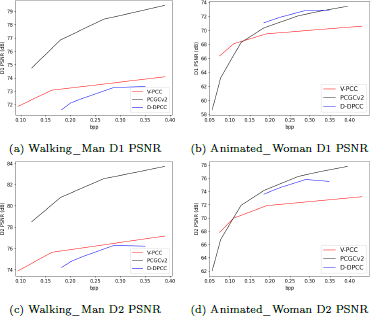
The RD curves for the dynamic lossy geometry compression, employing various methods on two selected 32 frame point clouds from PKU-DPCC dataset.
The RD curves for the dynamic lossy geometry compression, employing various methods on two selected 32 frame point clouds from PKU-DPCC dataset.
4 Conclusion
We introduce a distinctive dynamic point cloud dataset, namely PKU-DPCC, which comprises of multiple subclasses with substantial dissimilarities. PKU-DPCC possesses distinct appearance characteristics and abundant motion vector information. Furthermore, its intricate nature presents challenges for compression, rendering it ideal as a test dataset for evaluating dynamic point cloud compression algorithms. By leveraging this dataset, we address the scarcity of diverse dynamic point cloud types and contribute to its enrichment. We demonstrate the versatility of our proposed dataset, by evaluating its performance across different lossless compression ratios of geometry and attribute, lossy compression PSNR of geometry and attribute, distortion levels analysis, and dynamic ranges analysis, etc. Meanwhile, the dataset we proposed has also been adopted and utilized by the AVS standard working group. In the future, we plan to expand PKU-DPCC to support various compression applications, including point cloud quality assessment and just noticeable difference (JND) prediction of static and dynamic point clouds coding.
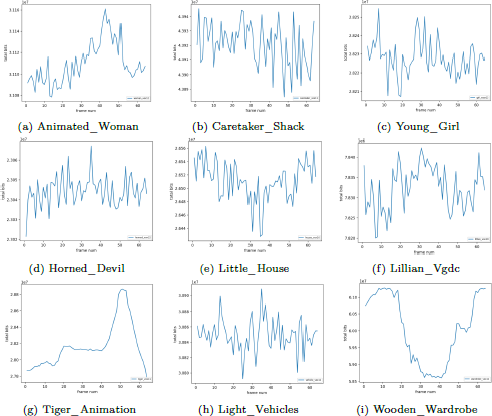
The relationship between frame rate and total bits. This bits include the attribute bits, geometry bits, and header information bits. Meanwhile, the proposed dataset highlights the dynamic nature of the collected data. Each frame in the test data occupies a unique bit size and displays diverse motion information. Additionally, these figures show that the motion vector is hard to predict. (a-i) illustrate the bitstream fluctuation range across 64 frames of the selected subset data sequences.
The relationship between frame rate and total bits. This bits include the attribute bits, geometry bits, and header information bits. Meanwhile, the proposed dataset highlights the dynamic nature of the collected data. Each frame in the test data occupies a unique bit size and displays diverse motion information. Additionally, these figures show that the motion vector is hard to predict. (a-i) illustrate the bitstream fluctuation range across 64 frames of the selected subset data sequences.
