

Employee digital proficiency is pivotal to digital transformation success. Upskilling decisions often rely on decision-making approaches that assume stable participation and become misaligned when engagement varies. The aim of this study was to develop and demonstrate the Employee Intervention Decision Tree (EIDT), a non-probabilistic model for selecting digital proficiency interventions under behavioural uncertainty.
Employee engagement was modelled as a state of nature (strong, moderate, and weak), operationalised using literature-informed impact multipliers. Three intervention types (mentorship, online tutorials, and self-paced study) were evaluated using normalised state-adjusted values, with an illustrative 2:2:1 weighting (cost:gain:duration) and assessed using non-probabilistic decision rules (maximax, maximin, Laplace, Hurwicz, and minimax regret). The model was demonstrated using anonymised data from a business implementing two digital platforms (N = 148; n = 127). Sensitivity testing compared alternative weighting regimes (3:2:1, 1:2:3, 1:1:1) and alternative engagement multiplier specifications (±20% and ±30%).
Recommendations varied systematically across engagement states, decision rules and weightings. Online tutorials dominated the high-proficiency tier. In the medium tier, self-paced study was preferred, with only maximin favouring tutorials. In the low tier, ties under Hurwicz and minimax regret were resolved in favour of self-paced study. Sensitivity results showed priority-consistent shifts under alternative weighting regimes, while multiplier perturbation scenarios produced no recommendation changes, indicating that the model is structurally robust to plausible calibration error.
The model supports transparent, risk-aligned prioritisation of upskilling investments, integrating behavioural nuance with decision logic, addressing a critical gap in digital proficiency strategy.
The EIDT links proficiency assessment with decision-making under uncertainty, reframing upskilling investment as a state-contingent strategic choice.
1. Introduction
Effective integration of digital technologies requires more than technology-centric strategies. Workforce capability is a critical determinant of digital transformation (DT) success (Blanka, Krumay, & Rueckel, 2022; Mkhize & Lourens, 2025). Employee digital proficiency is therefore pivotal for adoption and sustained value realisation (Martínez-Caro, Cegarra-Navarro, & Alfonso-Ruiz, 2020). Digital proficiency is multidimensional, spanning skills, confidence, adaptability, and willingness to adopt new digital behaviours. These dimensions vary across employees, necessitating targeted support to ensure readiness (Lokuge, Sedera, Grover, & Xu, 2019; Nguyen & Broekhuizen, 2022).
Human resource development (HRD) scholarship shows that training effectiveness depends on engagement, contextual relevance, motivation, and transfer opportunities. These factors make standardised programmes ill-suited to heterogeneous employee needs (Garavan et al., 2021; Nguyen & Broekhuizen, 2022; Sousa & Rocha, 2019). In practice, however, upskilling decisions frequently rely on predictive or score-based tools that presuppose consistent participation and stable outcomes, conditions that rarely hold in dynamic DT environments where engagement fluctuates and risk becomes difficult to assess (Agostino & Costantini, 2022; Kausel & Jackson, 2020; Poulose, Bhattacharjee, & Chakravorty, 2025). Although diagnostic frameworks, such as DigComp (Vuorikari, Kluzer, & Punie, 2022; Ferrari, 2013), Ng's Digital Literacy Framework (Ng, 2012), and adaptive skills models (Hangauer, Worcester, & Armstrong, 2013), support proficiency assessment, they too are limited for ex ante intervention selection because they do not account for behavioural variability in engagement. To address this gap, a non-probabilistic decision tree was designed in this study to guide intervention selection when engagement is uncertain. The proposed model evaluates intervention alternatives under scenarios of strong, moderate, and weak employee participation, applying established non-probabilistic decision rules. By structuring these comparisons, it translates managerial judgement into a formal framework that enables transparent, risk-sensitive upskilling choices, without relying on predictive assumptions.
2. Background
2.1 Decision-making for workforce development under uncertainty
Traditional HRD emphasises retrospective evaluation of the workforce through cost-benefit analysis, return on investment, and post hoc outcome assessment. However, these methods provide limited ex ante guidance when outcomes depend on uncertain behavioural responses (Phillips & Phillips, 2016). Consequently, upskilling choices frequently rely on managerial heuristics that fail to balance costs, time, and learning gains under volatile engagement. Although digital proficiency is increasingly measured using self-reported, task-based, and analytics-derived indicators, the resulting evidence remains largely descriptive and only weakly integrated with contextual and behavioural dynamics (Blanka et al., 2022; Fenech, Baguant, & Ivanov, 2019).
Probabilistic and optimisation models perform best in data-rich settings with reliable estimates (Alabi, Ajayi, Udeh, & Efunniyi, 2022; Kausel & Jackson, 2020); however, in DT contexts, predictive precision can mask rather than reduce risk, underscoring the need for approaches that explicitly accommodate behavioural variability (Nguyen & Broekhuizen, 2022). To address this gap, this study introduces the Employee Intervention Decision Tree (EIDT), a non-probabilistic, state-contingent framework that formalises managerial reasoning and embeds behavioural insights within structured decision rules. Unlike deterministic optimisation, predictive scoring, or generic multi-criteria ranking, the EIDT preserves state-contingent variation, makes risk posture explicit, and clarifies how intervention choices shift under different engagement scenarios. Table 1 positions the EIDT alongside related technical approaches, highlighting its distinctive role in contexts where uncertainty is high and managerial judgement must remain visible in the choice process.
Conceptual comparison of the EIDT with alternative technical approaches
| Approach class | Primary logic | Strength | Limitation in the present context | References |
|---|---|---|---|---|
| Deterministic optimisation | Selects a single best option under fixed assumptions | Efficient where inputs are stable and well specified | Less suited to contexts where engagement and learning transfer vary across states | Aven (2016), Ragsdale (2021) |
| Predictive or score-based approaches | Forecasts or classifies likely outcomes from historical patterns | Useful for prediction and segmentation in data-rich environments | Does not directly represent managerial risk posture in intervention choice | Alabi et al. (2022), Kausel and Jackson (2020), Nguyen and Broekhuizen (2022) |
| Generic multi-criteria ranking approaches | Ranks alternatives across multiple criteria | Enables transparent comparison across cost, gain, and duration | Often produces a static ordering that obscures state-contingent shifts | Belton and Stewart (2002), Bhushan and Rai (2004) |
| EIDT | Combines state-adjusted payoffs with non-probabilistic decision rules | Makes behavioural uncertainty, risk posture, and tie-break logic explicit | Depends on theory-informed calibration and requires context-sensitive parameter setting | Aven (2016), Goodwin and Wright (2014), Nguyen and Broekhuizen (2022) |
3. Theoretical foundation of the non-probabilistic decision tree
DT challenges conventional HRD decision models that assume stable participation and predictable outcomes. Workforce capability development is shaped by shifting task demands, organisational constraints, and behavioural variability, limiting the applicability of deterministic optimisation. The non-probabilistic decision tree developed in this study is therefore grounded in an integrative theoretical foundation spanning HRD and strategic human capital perspectives, behavioural theory, and non-probabilistic decision theory.
HRD and strategic human capital provide a broad framing of capability development as both an organisational investment and a learning process. From this perspective, digital proficiency is treated as a capability-building priority developed through learning opportunities and organisational support rather than as a discrete training event (Fenech et al., 2019; Garavan et al., 2021; Phillips & Phillips, 2016). Drawn from established theories, behavioural theory contributes the specific explanatory mechanisms that account for variation in employee behaviour. The self-determination theory (SDT) links sustained engagement to autonomy, competence, and relatedness (Ryan & Deci, 2000), while the social cognitive theory (SCT) emphasises self-efficacy and observational learning (Bandura, 1986). The technology acceptance model (TAM) highlights perceived usefulness and ease of use as determinants of uptake and sustained use of digital systems (Davis, 1989). In DT contexts, these behavioural drivers are dynamic and shaped by organisational climate, workload, and perceived relevance (Nguyen & Broekhuizen, 2022). In the model, behavioural mechanisms are operationalised through intervention-specific calibration multipliers (1.00, 0.50, 0.10), which correspond to high, moderate, and weak engagement states. These values are not probabilistic estimates, but scenario anchors derived from behavioural theory (SDT, SCT, TAM) and HRD practice, ensuring that engagement uncertainty is represented explicitly in the decision structure rather than treated as a residual influence.
Non-probabilistic decision theory provides the bridging logic, translating these theoretically grounded but uncertain behavioural conditions into a structured basis for comparing potential upskilling interventions without assuming reliable probabilities (Aven, 2016). Table 2 maps the resulting strategic principles of true uncertainty, scenario planning, adaptive reasoning, regret minimisation, flexibility, accessibility, and multi-criteria evaluation to structural features of the decision tree.
Conceptual alignment between strategic decision principles and structural features of the non-probabilistic decision tree
| Key strategic principle | Decision tree feature | Application to digital proficiency | References |
|---|---|---|---|
| True uncertainty | Non-probabilistic structure (no reliance on probabilities) | Enables decisions when digital outcomes (e.g. skill uptake, tool adoption) are unpredictable | Aven (2016), Nguyen and Broekhuizen (2022) |
| Scenario planning | Branches represent alternative digital readiness pathways | Allows modelling of diverse employee profiles (e.g. low literacy, latent competence, productivity) | Jafari and Van Looy (2025) |
| Adaptive reasoning | Re-entry points and feedback loops | Supports iterative development and re-evaluation as digital tools or roles evolve | Jafari and Van Looy (2025) |
| Regret minimisation | Minimax regret criterion embedded in branch logic | Helps avoid irreversible training investments or misaligned role assignments | Goodwin and Wright (2014) |
| Strategic flexibility | Modular tree design with optional paths | Accommodates organisational shifts, new technologies, or evolving strategic priorities | Belton and Stewart (2002) |
| Cognitive accessibility | Heuristic-based branching and simplified decision nodes | Empowers managers and employees to make informed choices without complex analytics | Kausel and Jackson (2020), Ragsdale (2021) |
| Multi-criteria decision-making | Embedded scoring and weighting logic at key decision nodes | Enables evaluation of digital strategies across multiple dimensions (e.g. cost, engagement, adaptability) | Belton and Stewart (2002), Bhushan and Rai (2004) |
4. Research methodology
A pragmatic approach was adopted to design the non-probabilistic decision tree, beginning with a conceptual model as the foundation. As shown in Figure 1, the conceptual tree unfolds in three phases, ending in a terminal Decision node. In Phase 1, employees are stratified into high-, medium-, and low-proficiency tiers at the root node of the decision tree. In Phase 2, each proficiency tier is linked to a tailored set of interventions. In Phase 3, the effectiveness of interventions is evaluated using several operational steps to apply intervention scoring criteria and non-probabilistic decision rules. Finally, the outcomes of the non-probabilistic decision rules are shown at the terminal node (Decision). These conceptual phases were operationalised to produce the EIDT through a seven-step process: (1) collect proficiency inputs, (2) define interventions, (3) specify scoring criteria, (4) model engagement states of nature, (5) compute and normalise payoffs, (6) apply decision rules, and (7) conduct sensitivity analysis. Rather than serving as a purely conceptual sequence, this seven-step process establishes a reproducible and transparent decision procedure in which each stage generates a defined input for the next, ensuring methodological rigour and practical applicability.
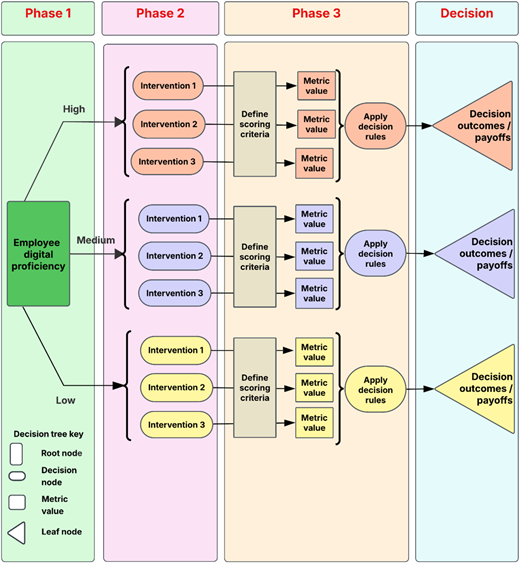
4.1 Step 1: input data
Operationalisation began by specifying root-node inputs (Phase 1 of the conceptual model) using anonymised digital proficiency data from employees at an international travel business, based in Southern Africa. At the time of data collection, employees (aged <30 to >50 years, with tenure from <1 to >5 years) were adopting two enterprise-wide platforms to support bookings and streamline workflows. Digital proficiency was assessed via an anonymous five-point Likert-scale questionnaire, administered electronically over three weeks and completed voluntarily, measuring Digital Literacy, Digital Competence, and Digital Productivity. The 40-item instrument was refined through expert review for face and content validity prior to administration. Of N = 148 invited employees, n = 127 responded. Following data collection, reliability and structural validity were confirmed (Cronbach's α = 0.62–0.91 across subdimensions; CR = 0.91–0.95; AVE = 0.52–0.62), supporting satisfactory construct reliability and convergent validity. The data were screened, identifiers were removed, and composite digital proficiency scores were computed (M = 4.06; Median = 4.11; SD = 0.56). These scores were stratified into tiers: high (>80%, n = 73), medium (65–80%, n = 44), and low (<65%, n = 10) to support tier-specific intervention evaluation.
4.2 Step 2: potential interventions
In Step 2, intervention options were identified for each proficiency tier, using proficiency scores to link capability gaps to appropriate upskilling intervention strategies (Phase 2 of the conceptual model). A representative set of commonly used interventions was selected, varying in cost structure, delivery format, support intensity, time commitment, and behavioural dependence. Table 3 illustrates these interventions, drawing on established HRD practices in mentoring, structured training, e-learning, and self-directed study (Garavan et al., 2021; Phillips & Phillips, 2016). The tiered application of each intervention reflects research in both digital readiness and digital maturity, which emphasises differentiated support strategies across stages of transformation (Jafari & Van Looy, 2025; Nguyen & Broekhuizen, 2022). By positioning interventions in this way, the table highlights how delivery modes and implementation features can be tailored to proficiency levels while keeping behavioural risks visible in the decision process.
Illustrative potential interventions per digital proficiency tier
| Proficiency tier | Intervention | Delivery format and duration | Employees best suited to the intervention | Key implementation features | Behavioural risk |
|---|---|---|---|---|---|
| High | In-house mentorship (proprietary software) | Mentor-supported; ∼2 weeks | Highly proficient needing targeted support | Targeted coaching; practice with feedback; cost scales with mentor time | Availability of mentors |
| Online tutorial (proprietary software) | Self-paced; ∼5 hours | Narrow, task-specific gaps | Modular instruction; worked examples; independent completion | Learner self-regulation | |
| Self-directed study (proprietary software) | Self-study; ∼20 hours | Independent learners | Manuals, job aids, documentation; flexible, low cost | Sustained motivation | |
| Medium | In-house training (proprietary software) | Facilitator-led; ∼4 weeks | Functional but incomplete proficiency | Guided instruction; hands-on practice; structured feedback; higher support needs | Availability of mentors |
| Online tutorial (proprietary software) | Self-paced; ∼10 hours | Independent learners needing broader exposure | Standardised modules; scalable; completion depends on discipline | Learner self-regulation | |
| Self-directed study (proprietary software) | Self-study; ∼20 hours | Independent learners using internal resources | Minimal support; flexible, low cost; slower progression | Sustained motivation | |
| Low | In-house training (general digital proficiency) | Facilitator-led; ∼4 weeks | Require foundational support | Structured instruction; guided repetition; supervised practice; resource-intensive | Availability of mentors |
| Online training (general digital proficiency) | Self-paced; ∼10 hours | Broad foundational needs | Sequenced tasks; moderate cost; may need prompting | Learner self-regulation | |
| Self-directed study (general digital proficiency) | Self-study; ∼20 hours | Basic independent learners | Manuals, guidance notes, exercises; inexpensive, flexible; risk of delay | Sustained motivation |
4.3 Step 3: potential intervention scoring criteria
To support strategic selection, a scoring scheme was defined in Step 3 for each intervention (Phase 3 of the conceptual model) using three criteria drawn from prior research: estimated cost, expected digital proficiency gain, and time-to-competence (duration) (Tang et al., 2024; Tolsgaard et al., 2015). These criteria balance resource commitment, anticipated outcomes, and implementation timelines, and were applied consistently across interventions to enable transparent comparison. Organisational priorities were represented through a 2:2:1 weighting (cost:gain:duration), reflecting a stronger emphasis on cost and gain than duration. Table 4 reports the criteria, units, definitions, and weightings ().
Potential intervention scoring criteria
| Criterion | Criterion description | Criterion weighting ( | Metric description | Metric unit | Direction of metric |
|---|---|---|---|---|---|
| Baseline intervention cost | Total cost per potential intervention, calculated using a fixed rate per participant | 2 | Currency value from vendor quotes/internal cost analysis | Currency value | Lower cost = better cost efficiency |
| Baseline intervention gain | Rating of employee skills gain post-intervention | 2 | Assigned rating using a 5-point scale to indicate the expected gain in employee digital proficiency | 5-point scale, with 5 representing the highest proficiency | Higher rating = better gain |
| Baseline intervention duration | Anticipated duration (in weeks) for employees to achieve expected digital skills post-intervention | 1 | Calendar weeks required for employees to achieve expected digital skills | Weeks | Shorter duration = more time and cost efficient |
4.4 Step 4: states of nature and engagement multipliers
Employee engagement was modelled as a state of nature to represent behavioural uncertainty outside managerial control that materially affects upskilling outcomes (Phase 3 of the conceptual model). Three states, strong, moderate, and weak , were specified to reflect established links between engagement and learning effectiveness. These states were operationalised using impact multipliers (m) that adjust cost, expected gain, and duration to reflect engagement levels (Table 5). The multipliers (1.00, 0.50, 0.10) are calibration parameters derived from behavioural theory and intervention design logic rather than statistical estimates. They preserve a monotonic ordering across engagement states, capture the non-linear effect of engagement on learning outcomes, and vary by intervention type to reflect differences in behavioural dependence. Mentor-supported interventions are more resilient under declining engagement, while self-directed modalities are more vulnerable to reduced benefit and extended completion time (Bandura, 1997; Davis, 1989; Johnson & Aragon, 2003; Ryan & Deci, 2000). Under this interpretation, 1.00 denotes strong engagement as the reference condition, while lower gain multipliers and higher duration multipliers represent the expected erosion of efficiency as engagement weakens. The values are therefore justified as theoretically consistent scenario anchors, not precise causal magnitudes.
State impact factor multipliers per employee engagement level
| Digital proficiency tier | Potential intervention | Impact factor multiplier per employee engagement: Intervention cost and intervention gain | Impact factor multiplier per employee engagement level: Intervention duration | References | ||||
|---|---|---|---|---|---|---|---|---|
| Strong (sstrong) | Moderate (smoderate) | Weak (sweak) | Strong (sstrong) | Moderate (smoderate) | Weak (sweak) | |||
| High | In-house mentorship | 0.70 | 0.20 | 0.10 | 1.00 | 1.30 | 1.70 | Bandura (1997), Edmondson (2018), Ulrich et al. (2023) |
| Online tutorial | 0.50 | 0.30 | 0.20 | 1.00 | 1.50 | 2.00 | Davis (1989), Johnson and Aragon (2003) | |
| Self-paced study | 0.35 | 0.40 | 0.25 | 1.00 | 1.70 | 2.50 | Chen, Yu, Cheng, and Hao (2019), Knowles (1984) | |
| Medium | In-house mentorship | 0.60 | 0.30 | 0.10 | 1.00 | 1.40 | 1.80 | Chen et al. (2019), Ulrich et al. (2023) |
| Online tutorial | 0.45 | 0.35 | 0.20 | 1.00 | 1.60 | 2.20 | Davis (1989), Johnson and Aragon (2003), Sweller (2011) | |
| Self-paced study | 0.25 | 0.45 | 0.30 | 1.00 | 1.80 | 2.80 | Ragsdale (2021), Ryan and Deci (2000) | |
| Low | In-house mentorship | 0.50 | 0.35 | 0.15 | 1.00 | 1.50 | 2.00 | Bandura (1997), Edmondson (2018), Ullrich, Reißig, Niehoff, and Beier (2023) |
| Online tutorial | 0.40 | 0.40 | 0.20 | 1.00 | 1.70 | 2.50 | Davis (1989), Johnson and Aragon (2003) | |
| Self-paced study | 0.20 | 0.50 | 0.30 | 1.00 | 2.00 | 3.00 | Knowles (1984), Ragsdale (2021), Ryan and Deci (2000) | |
4.5 Step 5: normalised and weighted payoff values
Intervention payoff values were calculated to enable comparison across heterogeneous criteria and engagement states (Phase 3 of the conceptual model). First, the defined values for each intervention, per digital proficiency tier and intervention criterion, were adjusted to reflect behavioural uncertainty by applying the relevant state-impact multiplier for each engagement state:
Where denotes the state-adjusted value of intervention at tier for criterion under engagement state ; denotes the intervention baseline value of intervention at tier for criterion c under engagement state s; and represents the corresponding engagement multiplier.
Because criteria use different units and scales, state-adjusted values were normalised to a common [0,1] range to enable aggregation. Min–max normalisation was applied to preserve within-criterion ordering across engagement states while ensuring comparability (Han, Kamber, & Pei, 2012). A standard min–max transform was used for expected gain (higher is better), and an inverted min–max transform was used for cost and duration (lower is better):
Where denotes intervention at tier for criterion under engagement state ; denotes the state-adjusted intervention value to be normalised; represents the minimum state-adjusted value for intervention at tier for criterion under engagement state ; and represents the maximum state-adjusted value.
Finally, normalised criterion values were aggregated using the specified 2:2:1 weighting (cost:gain:duration) to produce a payoff matrix that captures intervention performance across engagement states:
Where denotes the weighted combined intervention payoff value for intervention at tier for criterion under engagement state ; wcost, wgain, and wduration denote the weighting assigned to intervention cost, gain, and duration, respectively; and denotes the normalised score for intervention at tier for criterion under engagement state .
4.6 Step 6: non-probabilistic decision rules
Non-probabilistic decision rules were applied to the payoff matrix to assess intervention robustness under behavioural uncertainty (Phase 3). Five non-overlapping rules—maximax, maximin, minimax regret, Laplace, and Hurwicz—were selected to represent orientations from optimistic value-seeking to conservative risk mitigation, providing complementary lenses for choice across engagement scenarios (Arrow & Hurwicz, 1977; Goodwin & Wright, 2014; Laplace, 1902) (Table 6).
Decision rules and intervention selection logic
| Decision rule | Decision-making approach | Decision rule application for decision-making |
|---|---|---|
| Maximax | Optimistic (upside seeking) |
|
| Maximin | Pessimistic (downside protection) |
|
| Laplace | Equal-weight average |
|
| Hurwicz | Tempered optimism, using the optimism coefficient alpha (α), also known as the coefficient of realism |
|
| Minimax regret | Regret-averse |
|
| Tie-break procedure | Equal potential intervention scores are addressed using a tie-break procedure |
|
4.7 Step 7: sensitivity analysis
A deterministic sensitivity analysis was conducted to test the robustness of intervention recommendations under alternative modelling assumptions. Two dimensions of sensitivity were examined.
Criterion-weight sensitivity: Criterion-weight sensitivity was assessed by varying the relative emphasis on cost, gain, and duration across four regimes: 2:2:1 (baseline, balanced emphasis on cost and gain), 3:2:1 (stronger cost emphasis), 1:2:3 (stronger duration emphasis), and 1:1:1 (equal weighting).
Multiplier sensitivity: Engagement multipliers were perturbed by ±20% and ±30% around the baseline values in Table 5 to capture plausible deviations from theory-informed calibration. These adjustments preserved the ordinal structure of engagement states and intervention-specific relationships, with strong engagement (1.00) retained as the reference condition.
For each scenario, state-adjusted cost, gain, and duration values were recalculated, normalised, and evaluated using non-probabilistic decision rules. Across both weight and multiplier variations, recommended interventions remained stable, confirming that the decision tree is robust to reasonable shifts in managerial priorities and engagement calibration. This strengthens confidence that the model's outputs are not artefacts of specific parameter choices but reflect consistent decision logic under uncertainty.
5. Results
5.1 State-adjusted intervention cost, gain, and duration
Engagement materially altered intervention cost, expected gain, and duration across proficiency tiers. Baseline values reflected inherent criterion estimates, whereas state-adjusted values were derived by applying multipliers for strong, moderate, and weak engagement (Table 7). State-adjusted cost generally followed the same ordering across tiers (mentorship highest, tutorials intermediate, self-paced lowest), although mentorship and tutorials converged under weak engagement in the high- and medium-proficiency tiers. State-adjusted gains were more condition-sensitive: mentorship delivered the highest gains under strong (and mostly moderate) engagement but declined most sharply as engagement weakened, whereas tutorials and self-paced study showed flatter gain profiles and, under weak engagement, matched or exceeded mentorship. State-adjusted duration increased as engagement weakened, with mentorship exhibiting the smallest delays, whereas self-paced study showed the largest extensions, particularly in medium- and low-proficiency cohorts. Overall, the results indicate a trade-off across potential interventions between intervention resource intensity, employee behavioural dependence, and the time taken to enhance employee proficiency. These patterns confirm that the engagement multipliers translate behavioural assumptions into observable differences in intervention cost-efficiency, expected learning gain, and time-to-competence, illustrating how behavioural uncertainty shapes practical outcomes.
State-adjusted intervention cost, gain, and duration across digital proficiency tiers
| Proficiency tier | Intervention | Baseline cost (ZAR) | Baseline gain (1–100) | Baseline duration (weeks) | State-adjusted criterion values | ||
|---|---|---|---|---|---|---|---|
| Strong engagement (cost/gain/duration) | Moderate engagement (cost/gain/duration) | Weak engagement (cost/gain/duration) | |||||
| High | In-house mentorship | 73,000 | 80 | 2 | 51,100/56/2.0 | 14,600/16/2.6 | 7,300/8/3.4 |
| Online tutorial | 36,500 | 60 | 3 | 18,250/30/3.0 | 10,950/18/4.5 | 7,300/12/6.0 | |
| Self-paced study | 14,600 | 40 | 4 | 5,110/14/4.0 | 5,840/16/6.8 | 3,650/10/10.0 | |
| Medium | In-house mentorship | 220,000 | 80 | 4 | 132,000/48/4.0 | 66,000/24/5.6 | 22,000/8/7.2 |
| Online tutorial | 110,000 | 60 | 6 | 49,500/27/6.0 | 38,500/21/9.6 | 22,000/12/13.2 | |
| Self-paced study | 8,800 | 40 | 8 | 2,200/10/8.0 | 3,960/18/14.4 | 2,640/12/22.4 | |
| Low | In-house mentorship | 30,000 | 80 | 4 | 15,000/40/4.0 | 10,500/28/6.0 | 4,500/12/8.0 |
| Online tutorial | 20,000 | 60 | 6 | 8,000/24/6.0 | 8,000/24/10.2 | 4,000/12/15.0 | |
| Self-paced study | 2,000 | 40 | 10 | 400/8/10.0 | 1,000/20/20.0 | 600/12/30.0 | |
Note(s): ZAR: South African Rand
5.2 Weighted payoff scores across cost, gain, and duration
Aggregated payoffs show how intervention rankings change when cost, gain, and duration are jointly evaluated across engagement states. State-adjusted values were normalised and combined into weighted payoff scores, yielding a payoff matrix that revealed conditional patterns beyond single-criterion comparisons (Table 8). For high proficiency, online tutorials performed best under moderate engagement. For medium proficiency, mentorship dominated under strong and moderate engagement, while self-paced study was preferred under weak engagement. For low proficiency, mentorship led under strong and moderate engagement, and self-paced study again dominated under weak engagement. Overall, the results indicate that optimal intervention choice is state-contingent, varying by both proficiency tier and engagement level.
Normalised criteria scores and combined weighted intervention payoff values by state
| Digital proficiency tier | Potential intervention | Normalised criteria scores per state of nature | Combined weighted intervention payoff value per state of nature | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Strong | Moderate | Weak | |||||||||||
| Cost | Gain | Duration | Cost | Gain | Duration | Cost | Gain | Duration | Strong | Moderate | Weak | ||
| High | In-house mentorship | 0.00 | 1.00 | 1.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 | 3.00 | 1.00 | 1.00 |
| Online tutorial | 0.71 | 0.38 | 0.50 | 0.42 | 1.00 | 0.55 | 0.00 | 1.00 | 0.61 | 2.68 | 3.39 | 2.61 | |
| Self-paced study | 1.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 | 0.50 | 0.00 | 2.00 | 2.00 | 3.00 | |
| Medium | In-house mentorship | 0.00 | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 | 0.00 | 0.00 | 1.00 | 3.00 | 3.00 | 1.00 |
| Online tutorial | 0.64 | 0.45 | 0.50 | 0.44 | 1.00 | 0.55 | 0.00 | 1.00 | 0.61 | 2.68 | 2.43 | 2.61 | |
| Self-paced study | 1.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 2.00 | 2.00 | 4.00 | |
| Low | In-house mentorship | 0.00 | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 | 0.00 | 0.00 | 1.00 | 3.00 | 3.00 | 3.00 |
| Online tutorial | 0.48 | 0.50 | 0.67 | 0.26 | 0.50 | 0.70 | 0.13 | 0.00 | 0.68 | 2.63 | 2.22 | 2.94 | |
| Self-paced study | 1.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 2.00 | 2.00 | 4.00 | |
5.3 Operationalised employee intervention decision tree
Applying the five non-probabilistic decision rules to each tier's payoff matrix produced tier-specific recommendations under different risk orientations, with a transparent tie-break where rule outputs converged. In the high-proficiency tier, online tutorials dominated across rules, indicating robust performance across optimistic and balanced orientations (Figure 2). In the medium-proficiency tier, preferences varied by risk posture with self-paced study selected under maximax, Laplace, Hurwicz, and minimax regret, while tutorials were favoured under maximin, reflecting a more conservative stance. In the low-proficiency tier, mentorship was preferred under maximin and Laplace, whereas self-paced study was preferred under maximax. Hurwicz (α = 0.5) and minimax regret produced ties, resolved in favour of self-paced study due to broader cross-rule support. Overall, rule-based evaluation with transparent tie-breaking produced coherent, non-arbitrary recommendations under uncertainty.
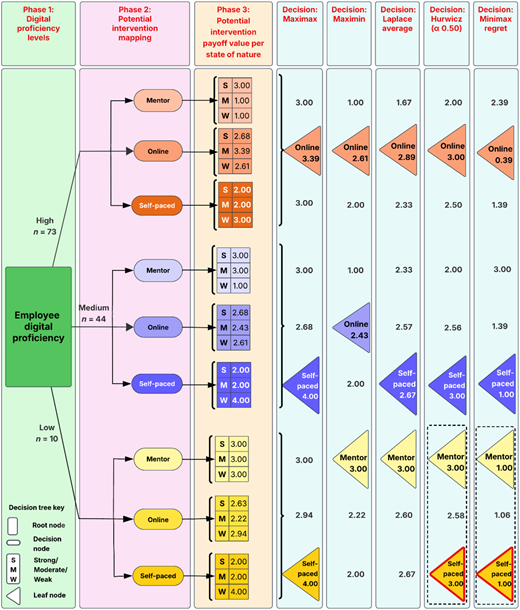
Employee intervention decision tree showing intervention selection across digital proficiency tiers based on five decision rules (black outline indicates tie-break intervention options; red outline indicates intervention choice after tie-break application)
Employee intervention decision tree showing intervention selection across digital proficiency tiers based on five decision rules (black outline indicates tie-break intervention options; red outline indicates intervention choice after tie-break application)
To aid interpretation, Table 9 summarises the main empirical outputs of the EIDT. For each proficiency tier, it shows the highest weighted-payoff intervention by engagement state, the final intervention selected under decision rules, and the decision-support implications. This format highlights how the EIDT differs from more static approaches by making intervention choice state-contingent, sensitive to risk posture, and transparent where ties occur.
Consolidated EIDT results by engagement state, decision rule, and decision-support implication
| Digital proficiency tier | Highest weighted-payoff intervention by engagement state | Final intervention selected under decision rules | Decision-support implication | Advantage of the EIDT over other technical approaches |
|---|---|---|---|---|
| High | Strong: In-house mentorship; Moderate | Online tutorial under all rules | Although the highest-payoff intervention varies across engagement states, online tutorials provide the most robust overall choice across the rule set | The EIDT identifies a balanced option under behavioural uncertainty rather than relying on a single-state optimum |
| Online tutorial; Weak: Self-paced study | ||||
| Medium | Strong: In-house mentorship; Moderate: In-house mentorship; Weak: Self-paced study | Self-paced study under maximax, Laplace, Hurwicz, and minimax regret; Online tutorial under maximin | The medium tier shows that recommendations change with decision posture: self-paced study is attractive under upside, average, and regret-based reasoning, while tutorials are preferred under downside protection | The EIDT makes organisational risk posture explicit in intervention selection |
| Low | Strong: In-house mentorship; Moderate: In-house mentorship; Weak: Self-paced study | Self-paced study under maximax; In-house mentorship under maximin and Laplace; Self-paced study under Hurwicz and minimax regret after tie-break with in-house mentorship | The low tier shows the greatest decision tension | The EIDT surfaces this ambiguity, and resolves it transparently through explicit tie-break logic, showing where intervention choice is finely balanced rather than artificially definitive |
5.4 Sensitivity analysis
Sensitivity analysis was conducted to test the robustness of EIDT recommendations under alternative modelling assumptions, focusing on criterion weights and engagement multipliers. When examining criterion weights, varying the emphasis on cost, gain, and duration across four regimes (2:2:1, 3:2:1, 1:2:3, and 1:1:1) produced only limited switching (Table 10). Most recommendations remained stable, with changes concentrated in high-tier selections near threshold boundaries and in the medium-tier maximin rule, which is more sensitive to worst-case outcomes. A cost-heavy weighting (3:2:1) favoured self-paced study, while duration-heavy (1:2:3) and equal weighting (1:1:1) favoured mentorship.
Decision outcome sensitivity to varying criterion weightings
| Tier | Decision rule | Weighting | Sensitivity summary | |||
|---|---|---|---|---|---|---|
| 2:2:1 (illustrative) | 3:2:1 (cost-heavier) | 1:2:3 (duration-heavier) | 1:1:1 (equal) | |||
| High | Maximax | Online tutorial | Self-paced study | In-house mentorship | In-house mentorship | 2 switch(es) |
| Maximin | Online tutorial | Self-paced study | Online tutorial | Online tutorial | 1 switch(es) | |
| Laplace | Online tutorial | Self-paced study | In-house mentorship | In-house mentorship | 2 switch(es) | |
| Hurwicz (α = 0.5) | Online tutorial | Self-paced study | In-house mentorship | Online tutorial | 2 switch(es) | |
| Minimax regret | Online tutorial | Self-paced study | In-house mentorship | Online tutorial | 2 switch(es) | |
| Medium | Maximax | Self-paced study | Self-paced study | In-house mentorship | In-house mentorship | 1 switch(es) |
| Maximin | Online tutorial | Self-paced study | In-house mentorship | In-house mentorship | 2 switch(es) | |
| Laplace | Self-paced study | Self-paced study | In-house mentorship | In-house mentorship | 1 switch(es) | |
| Hurwicz (α = 0.5) | Self-paced study | Self-paced study | In-house mentorship | In-house mentorship | 1 switch(es) | |
| Minimax regret | Self-paced study | Self-paced study | In-house mentorship | In-house mentorship | 1 switch(es) | |
| Low | Maximax | Self-paced study | Online tutorial | In-house mentorship | In-house mentorship | 1 switch(es) |
| Maximin | In-house mentorship | Self-paced study | In-house mentorship | In-house mentorship | 1 switch(es) | |
| Laplace | In-house mentorship | Self-paced study | In-house mentorship | In-house mentorship | 1 switch(es) | |
| Hurwicz (α = 0.5) | Self-paced study (after tie-break with in-house mentorship) | Self-paced study | In-house mentorship | In-house mentorship | 1 switch(es) | |
| Minimax regret | Self-paced study (after tie-break with in-house mentorship) | Self-paced study | In-house mentorship | In-house mentorship | 1 switch(es) | |
When the engagement multipliers were varied, perturbing the moderate and weak values by ±20–30% produced no recommendation switches across tiers or decision rules (Table 11). High-tier recommendations consistently favoured online tutorials, medium-tier recommendations favoured self-paced study except under the maximin rule, and low-tier recommendations remained unchanged, including the tie-break outcomes. This stability shows that the model is robust to calibration error in the engagement multipliers. In contrast, weighting assumptions drove modest variation in recommendations, confirming that weighting choices represent the principal source of sensitivity.
Decision outcome sensitivity to alternative engagement multiplier perturbation scenarios
| Tier | Decision rule | Baseline | −30% | −20% | +20% | +30% | Sensitivity summary |
|---|---|---|---|---|---|---|---|
| High | Maximax | Online tutorial | Online tutorial | Online tutorial | Online tutorial | Online tutorial | 0 switch(es) |
| Maximin | Online tutorial | Online tutorial | Online tutorial | Online tutorial | Online tutorial | 0 switch(es) | |
| Laplace | Online tutorial | Online tutorial | Online tutorial | Online tutorial | Online tutorial | 0 switch(es) | |
| Hurwicz (α = 0.5) | Online tutorial | Online tutorial | Online tutorial | Online tutorial | Online tutorial | 0 switch(es) | |
| Minimax regret | Online tutorial | Online tutorial | Online tutorial | Online tutorial | Online tutorial | 0 switch(es) | |
| Medium | Maximax | Self-paced study | Self-paced study | Self-paced study | Self-paced study | Self-paced study | 0 switch(es) |
| Maximin | Online tutorial | Online tutorial | Online tutorial | Online tutorial | Online tutorial | 0 switch(es) | |
| Laplace | Self-paced study | Self-paced study | Self-paced study | Self-paced study | Self-paced study | 0 switch(es) | |
| Hurwicz (α = 0.5) | Self-paced study | Self-paced study | Self-paced study | Self-paced study | Self-paced study | 0 switch(es) | |
| Minimax regret | Self-paced study | Self-paced study | Self-paced study | Self-paced study | Self-paced study | 0 switch(es) | |
| Low | Maximax | Self-paced study | Self-paced study | Self-paced study | Self-paced study | Self-paced study | 0 switch(es) |
| Maximin | In-house mentorship | In-house mentorship | In-house mentorship | In-house mentorship | In-house mentorship | 0 switch(es) | |
| Laplace | In-house mentorship | In-house mentorship | In-house mentorship | In-house mentorship | In-house mentorship | 0 switch(es) | |
| Hurwicz (α = 0.5) | Self-paced study (after tie-break with in-house mentorship) | Self-paced study (after tie-break with in-house mentorship) | Self-paced study (after tie-break with in-house mentorship) | Self-paced study (after tie-break with in-house mentorship) | Self-paced study (after tie-break with in-house mentorship) | 0 switch(es) | |
| Minimax regret | Self-paced study (after tie-break with in-house mentorship) | Self-paced study (after tie-break with in-house mentorship) | Self-paced study (after tie-break with in-house mentorship) | Self-paced study (after tie-break with in-house mentorship) | Self-paced study (after tie-break with in-house mentorship) | 0 switch(es) |
6. Discussion
The EIDT developed in this study transformed behavioural uncertainty into actionable decision guidance for DT workforce development. The sensitivity analysis demonstrated that intervention effectiveness is conditional, varying systematically with employee engagement and the applied decision rule. This aligns with behavioural decision theory, which emphasises that choices are shaped by risk preferences and contextual states rather than fixed probabilities (Aven, 2016; Goodwin & Wright, 2014). The observed shifts, where high-gain interventions dominate under strong engagement but lower cost or resilient options become attractive under weaker participation, reflect organisational trade-offs between ambition and risk containment (Bandura, 1986; Ryan & Deci, 2000).
From the HRD perspective, the findings resonate with human capital theory, which frames digital proficiency as an investment whose returns depend on participation and engagement (Fenech et al., 2019; Garavan et al., 2021; Phillips & Phillips, 2016). The variability across tiers and rules underscores that capability development is not an inherent property of training modalities but emerges from the interaction between employee behaviour and organisational priorities. Similarly, insights from the technology acceptance model highlight that perceived usefulness and ease of use condition uptake, reinforcing the importance of modelling engagement as a state of nature (Davis, 1989; Nguyen & Broekhuizen, 2022). The use of multiple non-probabilistic decision rules adds analytical depth, exposing how preferences shift under optimistic, pessimistic, or regret-averse orientations (Arrow & Hurwicz, 1977; Goodwin & Wright, 2014).
The sensitivity analysis further clarified the robustness of the model. Shifts in criterion weighting produced some variation in recommendations, reflecting alternative managerial priorities, whereas proportional perturbations of the engagement multipliers did not alter final selections. This indicates that organisational priority setting is the main lever of variation, while modest calibration error in engagement parameters has little practical effect. In interpretive terms, managers can therefore be confident that recommendations remain stable under plausible engagement scenarios, with weighting choices representing the key dimension of strategic discretion.
Rather than prescribing a single optimal intervention, the EIDT functions as a transparent decision-support tool, making assumptions explicit and enabling managers to align choices with risk posture, resource constraints, and transformational goals. The value of the model lies in its ability to structure managerial judgement under uncertainty, offering a reproducible, theory-grounded approach to digital upskilling decisions.
7. Contribution and future research directions
This study reframes digital upskilling in DT and HRD as a forward-looking decision problem under behavioural uncertainty. The non-probabilistic, state-contingent decision tree models engagement as a state of nature and applies multiple decision rules to make organisational risk posture explicit and testable, translating proficiency indicators into transparent intervention choices across cost–gain–time trade-offs. Future research should validate and refine the model through applied case studies, direct comparison with deterministic, predictive, and alternative multi-criteria decision approaches, context-specific calibration of state parameters, and dynamic feedback as engagement evolves. Such work would clarify not only where the EIDT is practically useful, but also under what conditions it performs differently from more conventional intervention-selection approaches.
8. Conclusion
This study introduced the EIDT as a transparent framework for selecting digital upskilling interventions under behavioural uncertainty. By modelling engagement as a state of nature and evaluating cost, expected capability gain, and time-to-proficiency through explicit payoffs and non-probabilistic decision rules, the EIDT shifts choice from deterministic optimisation to scenario-robust selection. Results indicate state-contingent effectiveness: high-gain options dominate under strong engagement, whereas weaker participation favours lower cost or more flexible alternatives, consistent with organisational risk posture. As a decision-support (not predictive) artefact, the EIDT makes assumptions explicit, surfaces sensitivity to behavioural variability, and enables defensible, risk-aligned choices, contributing a theoretically-grounded and practically-applicable approach to workforce decision-making in DT. Sensitivity analysis further indicates that the EIDT is responsive to managerial priorities while remaining structurally stable, with predictable, risk-posture-consistent shifts concentrated where intervention trade-offs are most finely balanced, indicating sensitivity without fragility.
9. Limitations
Several limitations should be noted. Development of the EIDT relied on anonymised employee data from a single organisational context and a relatively small sample, which limits generalisability. A restricted set of intervention types was used for illustration, and the study did not include direct empirical comparison with alternative modelling approaches such as deterministic optimisation, predictive models, or other multi-criteria frameworks. Extending the model to additional interventions will require refinement of the scoring criteria and possibly new or alternative measures. The framework should also be validated longitudinally and across different stages of DT, with future research testing its performance over time and in varied organisational settings.
Ethical considerations
The Johannesburg Business School Research Ethics Committee (JBSREC) at the University of Johannesburg granted ethical clearance for the study. The dataset used to calculate employee digital proficiency tiers was collected anonymously from 127 participants, under ethical clearance code JBSREC2024182.
The authors extend their sincere appreciation to the participating business, as well as all individuals who assisted in the execution of this study.
